其實 , 對于語音識別這類和語音有關的幾個常見的AI功能——沒錯 , 是AI應用 , 模型都給你訓練好了的——往往一行代碼(核心實現)就能實現 , 不過為了謹慎起見 , 還是不要那么說吧 , 畢竟一行終端命令是一個功能 。 這個很厲害的AI就是百度飛槳的Speech , 其實就是PaddleSpeech啦 。
這是PaddlePaddle里的項目 。 PaddleSpeech基于飛槳PaddlePaddle的語音方向的開源模型庫 , 用于語音和音頻中的各種關鍵任務的開發 , 包含大量基于深度學習前沿和有影響力的模型 。 也就是封裝了語音識別語音翻譯等多個我們常用的功能 。 之前在很多AI應用上一直用國外的開源項目 , 雖然一直聽說PaddlePaddle但沒在意 , 后來用了某個一試 , 果然啊 , 比較符合胃口(門檻低唄) 。
如果我們想要做一個語音識別的小應用 , 或者就是想要體驗一下 , 可以試試PaddleSpeech這個 。 機智客簡單試了下 , 感覺效果還是很棒的 。 由于這是基于飛槳的PaddleSpeech , 所以我們在配置環境的時候就要安裝飛槳的庫 , 保證環境里有PaddlePaddle或者創建新的虛擬環境 , 安裝飛槳 。 再用pip安裝paddlespeech就行 。 這里官方強烈建議在Linux下 , 而且是3.7以及以上版本的Python , 由于自己用的是Ubuntu , 之前默認的Python就完全符合 , 這一步不存在障礙 。
等待安裝成功 , pip檢查沒有問題 , 就可以測試使用語音識別這些功能了 。 比如我們在本地文件夾里放一個測試的wav文件 , 然后用輸入paddlespeech asr --lang zh --input 0.wav這樣的命令開始識別 。 當然 , 這里沒有加路徑 , 說明是在當前目錄里開的終端 。 然后執行命令 。 此時會加載數據 , 然后會自動下載模型 , 下載PaddleSpeech需要的whl文件也就是paddlespeech_ctcdecoders-0.1.0-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl 。 文件并不大 , 不過之后有很多代碼輸出 , 安靜等著就行了 。
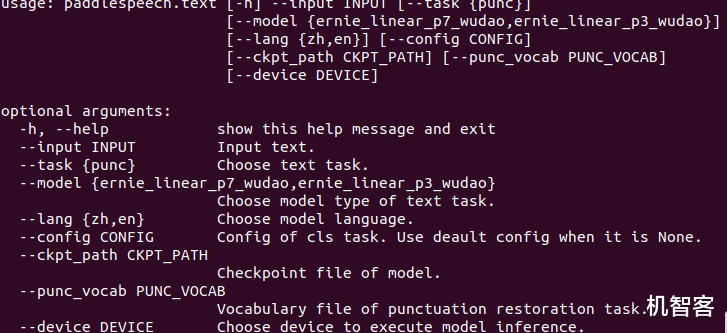
【華為|幾行代碼的事兒,語音識別翻譯合成克隆一條龍AI功能都有】等到結束了 。 正確的識別輸出就出來了 。 當然這里是輸出到終端里的 , 我們能直接看到 。 而paddlespeech命令還有很多參數和要求 , 我們可以在項目說明里查看文檔 , 或者在終端用help查看相關說明 。 這只是一個小例子 , Paddlespeech有很多內置的模型 , 也就是有很多相應的應用 , 方便我們直接調用 。 大家可以試一下 。
相關經驗推薦















- 華為鴻蒙系統|蒙系統的那些卡片功能,也就是剛面世時候的噱頭,用下來用處不大
- 華為|不可否認,華為做的事情,客觀上讓我們有了一個好的標桿
- 華為榮耀|9999元起售!國產“折疊屏性能王”誕生,榮耀逐步收復華為失地
- 華為鴻蒙系統|鴻蒙功耗很不錯,比以前耐用一些,系統也增加了一些小功能
- 紅米手機|中國的操作系統路在何方,華為鴻蒙系統普及路難, 新plug操作系統
- 華為|華為上架新機,搭載麒麟芯片,5000mAh僅售1399元
- |創小報151: 華為進軍私募;螞蟻減持眾安保險;佳能進軍造車;馬斯克
- 華為|2021年,最大蘋果的三大槽點
- iPhone|不想抄襲華為?iPhone14感嘆號挖孔不支持高刷,供應鏈產能不足!
- 華為手機|華為手機拍照不好看?新手必看指南