
文章圖片
文章圖片
文章圖片
一水 發自 凹非寺量子位 | 公眾號 QbitAI我并不認為Scaling Law已經完全結束了 。
正當學生Ilya為Scaling Law“潑下冷水”時 , 他的老師、AI教父Geoffrey Hinton卻毅然發表了上述截然相反的觀點 。
這一場面一出 , 我們不禁回想起了兩件有趣的事 。
一是Ilya幾乎從學生時代起就堅信Scaling Law , 不僅一抓住機會就向身邊人安利 , 而且還把這套理念帶進了OpenAI 。
可以說 , Ilya算是Scaling Law最初的擁躉者 。
二是Hinton后來在回顧和Ilya的相處時 , 曾大肆夸贊Ilya“具有驚人的直覺” , 包括在Scaling Law這件事上 , Hinton曾坦言:
當時的我錯了 , 而Ilya基本上是對的 。
比如Transformer確實是一種創新想法 , 但實際上起作用的還是規模 , 數據的規模和計算的規模 。
但是現在 , 這對師徒的態度卻來了個驚天大反轉 。
所以 , 這中間到底發生了什么?
Scaling Law不死派:Hinton、哈薩比斯緊隨學生Ilya , Hinton在接受《Business Insider》最新采訪時發表了對Scaling Law問題的看法 。
他的觀點相當明確——
Scaling Laws依然有效 , 只不過當前正面臨一些挑戰(limit) 。
其中 , 最大的挑戰無疑是數據缺失問題 。
大部分高價值數據都鎖在公司內部 , 免費互聯網數據已基本耗盡 。
而這個問題將由AI自行解決 , 即模型通過推理生成自己的訓練數據 。 此處他還特意cue到了AlphaGo和AlphaZero:
這就像AlphaGo和AlphaZero在規模小得多的情況下 , 為了精通圍棋而生成數據一樣 。
對于這些早期程序 , Hinton直言當時沒人擔心數據不足 , 因為它會自我對弈 , 并以此生成數據 。
照此 , 語言模型也可以采用同樣的方法來解決Scaling Law面臨的數據瓶頸 。
而和Hinton同樣支持Scaling Law的 , 還有谷歌DeepMind CEO哈薩比斯 。
哈薩比斯曾在不久之前的一場峰會上表示:
我們必須將當前系統的規模化推向極致 , 因為至少 , 它將是最終AGI系統的關鍵組成部分 。
甚至 , 它可能會成為整個AGI系統本身 。
正如Hinton所言 , 哈薩比斯早就在AlphaGo和AlphaZero身上看到了讓AI自主進化的無窮威力 。
當初訓練AlphaGo時 , DeepMind先讓其學習人類棋譜掌握基礎規則 , 隨后讓不同版本的程序通過數百萬局自我對弈不斷進化 , 最終擊敗了人類頂尖棋手 。
而到了AlphaZero , DeepMind更進一步 , 徹底摒棄人類數據 , 僅通過“Zero”狀態下的自我博弈 , 一天之內就讓AI成為了“有史以來最厲害的國際象棋選手” 。
這些都讓哈薩比斯逐漸堅信——通過規模化自動生成數據與自我進化 , AI最終能在各種任務上打敗人類 。
顯而易見 , 這一判斷恰好與Hinton關于“數據瓶頸可以被模型自行突破”的觀點形成了呼應 。
不過值得注意的是 , 哈薩比斯作為一位商業領袖、一位實打實的工程技術人員 , 他對Scaling Law的理解從來不止于“參數×數據×算力”的線性增長 。
他倡導的是一種更系統、更廣義的規模化 , 即模型規模、訓練范式、環境復雜度乃至系統架構本身 , 都需要作為一個協同演進的整體被同步擴展 。
這也是他為何反復強調構建“世界模型”、整合“搜索”與“規劃”能力的原因 。 他始終認為:
如果一個系統只能被動地擬合靜態數據分布 , 那么無論規模多大 , 最終都會撞上天花板;而一旦模型被允許進入“可交互的環境” , 數據本身就會變成一個可被無限擴展的變量 。
一言以蔽之 , 二人都認為Scaling Law本身沒有問題 , 關鍵是如何突破當下遇到的瓶頸 。
而且二人給出的解決思路在本質上高度一致 , 即讓AI自行解決 。
然而在Ilya看來 , 繼續擴展規模已經“不劃算”了:
這幾年大家幾乎都在喊“繼續擴大!再擴大!” 。 但當規模已經這么大時 , 你真的會相信再擴大100倍就能徹底改變一切嗎?
此言一出 , 外界紛紛認為Ilya這是在給Scaling Law“判死刑” 。
事實 , 果真如此嗎?
Scaling Law不夠用派:Ilya、LuCun實際上 , 要想搞清Ilya當下在想什么 , 我們還得回到Scaling Law這個問題本身 。
Scaling Law俗稱“大力出奇跡” , 其核心思想可概括為——
隨著模型參數規模、訓練數據量和計算資源的持續擴大 , AI模型的性能會按照可預測的規律穩步提升 。
這一規律在過去的AI發展中得到了反復驗證 , 從GPT-3到后來的大模型浪潮 , 幾乎每一次性能躍升都伴隨著規模的數量級增長 。
然而 , 從去年開始 , 關于Scaling Law的風向就開始變了 。
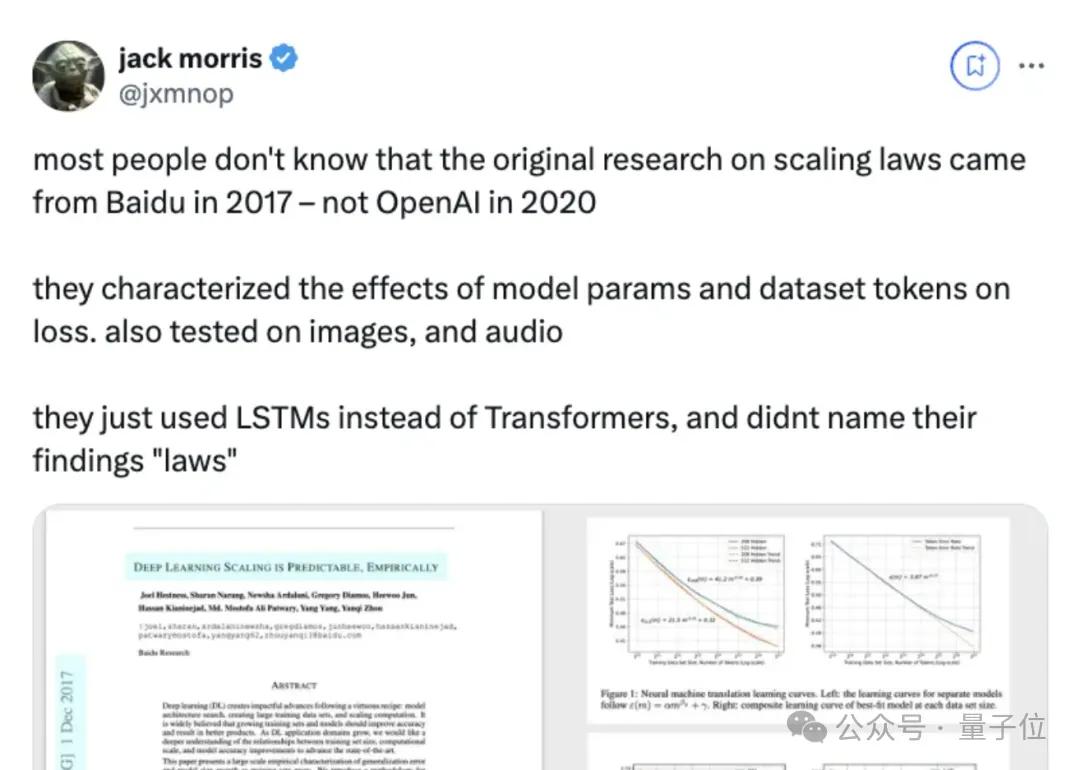
起初大家爭的還是歸屬權問題——
這個概念被OpenAI帶火之后 , 一位Meta研究員找出了百度2017年發表的一篇論文 , 結果發現論文里早就談到了Scaling Law問題 , 只是沒有相關正式命名 。
但僅僅到了年底 , 關于“Scaling Law見頂”的聲音開始越來越多了 。
也是在這個時候 , 已經離開OpenAI的Ilya , 在NeurIPS現場正式宣告了“預訓練即將終結” 。
我們所熟知的預訓練即將終結 。
他認為 , 數據是AI的化石燃料 , 隨著全球數據的限制 , 未來人工智能將面臨數據瓶頸 。
雖然當前我們仍然可以使用現有數據進行有效訓練 , 但這一增長趨勢終將放緩 , 預訓練的時代也會逐步結束 。
而未來屬于超級智能 , 比如智能體、推理、理解和自我意識 。
隨著Ilya的發言 ,關于Scaling Law的討論被徹底引爆 。
中間老東家OpenAI還跳出來附議了一波 , 只不過當時是為了宣傳他們的o系列推理模型——
o1核心成員Noam Brown表示 , o1代表的是一種全新的 , 以推理計算為代表的Scaling 。
就是說 , “預訓練雖然終結 , 但Scaling Law還沒死” 。
再到后來 , 吵吵嚷嚷間 , 人們等來了Ilya創辦的新公司 , 也是在這一階段 , Ilya開始試著回答——我們在Scaling什么?下一步做什么?
他在公司宣布成立后的采訪中表示:
過去十年深度學習的巨大突破 , 是一個關于尺度假設的特定公式 。 但它會改變……隨著它的改變 , 系統的能力將會增強 , 安全問題將變得最為緊迫 , 這就是我們需要解決的問題 。
從這里也能看出來 , 他開始逐漸強調一個觀念——Scaling Law變了 。
而這 , 也和他最新引起爭議的“Scaling Law無用論”相契合 。 他在問出“你真的會相信再擴大100倍就能徹底改變一切嗎”后表示:
會有變化 , 但我不認為僅靠更大規模就能帶來根本性的轉折 。 我們正重新回到研究時代 , 只不過這一次 , 我們手里多的是巨型計算機 。
在他看來 , 目前主流的“預訓練+Scaling”路線已經明顯遇到瓶頸 。 與其盲目擴大規模 , 不如把注意力放回到“研究范式本身”的重構上 。 (即所謂重新回到“科研時代”)
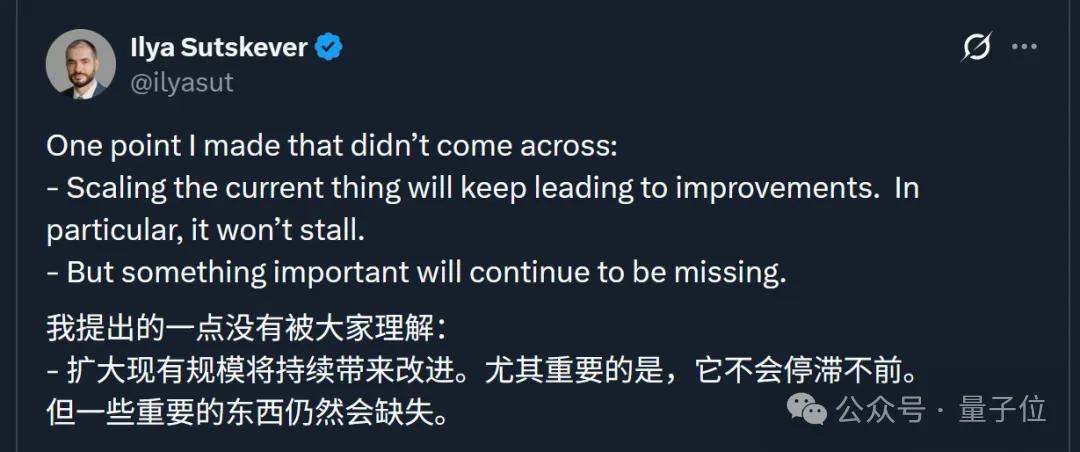
后來他還特意解釋道 , 不是說繼續擴展規模不會帶來變化 , 只是有些重要的東西仍然會缺失 。
至于缺失的是什么 , 盡管網友們狂轟亂炸了一番 , 但神秘的Ilya又“隱身”了 。
既然等不到他的回答 , 那我們只能從一些采訪中扒一扒蛛絲馬跡了 。
其中 , 我們就看到了這樣一個關鍵詞——情緒 。 Ilya無意間提過這樣一件事:
我碰到過一個例子 , 有一個人腦部受損 , 可能是中風或意外事故 , 導致他喪失了情感處理能力 。 所以他不再能感受到任何情緒 。 他仍然能言善辯 , 也能解一些簡單的謎題 , 考試成績也一切正常 。
但他感覺不到任何情緒 。 他不會感到悲傷 , 不會感到憤怒 , 也不會感到興奮 。 不知何故 , 他變得極其不擅長做任何決定 。 他甚至要花幾個小時才能決定穿哪雙襪子 。 他在財務方面也會做出非常糟糕的決定 。
這說明我們與生俱來的情感在使我們成為合格的行動主體方面扮演著怎樣的角色?說到你提到的預訓練 , 如果你能充分發揮預訓練的優勢 , 或許也能達到同樣的效果 。 但這似乎……嗯 , 預訓練是否真的能達到這種效果還很難說 。
【Hinton加入Scaling Law論戰,他不站學生Ilya】Anyway , 在Ilya看來 , Scaling Law或許有用 , 但真的是否夠用絕對大打問號 。
而另一個和Ilya同樣對Scaling Law持懷疑態度的是Yann LeCun 。
LeCun在今年4月的一場采訪中表示:
你不能簡單地假設更多的數據和計算能力就意味著更智能的人工智能 。
而且眾所周知 , LeCun一直認為大語言模型無法實現AGI , 為此他還另行成立公司創業世界模型 。
至此 , 表面上看 , 硅谷大佬們針對Scaling Law問題似乎形成了態度鮮明的兩派 。
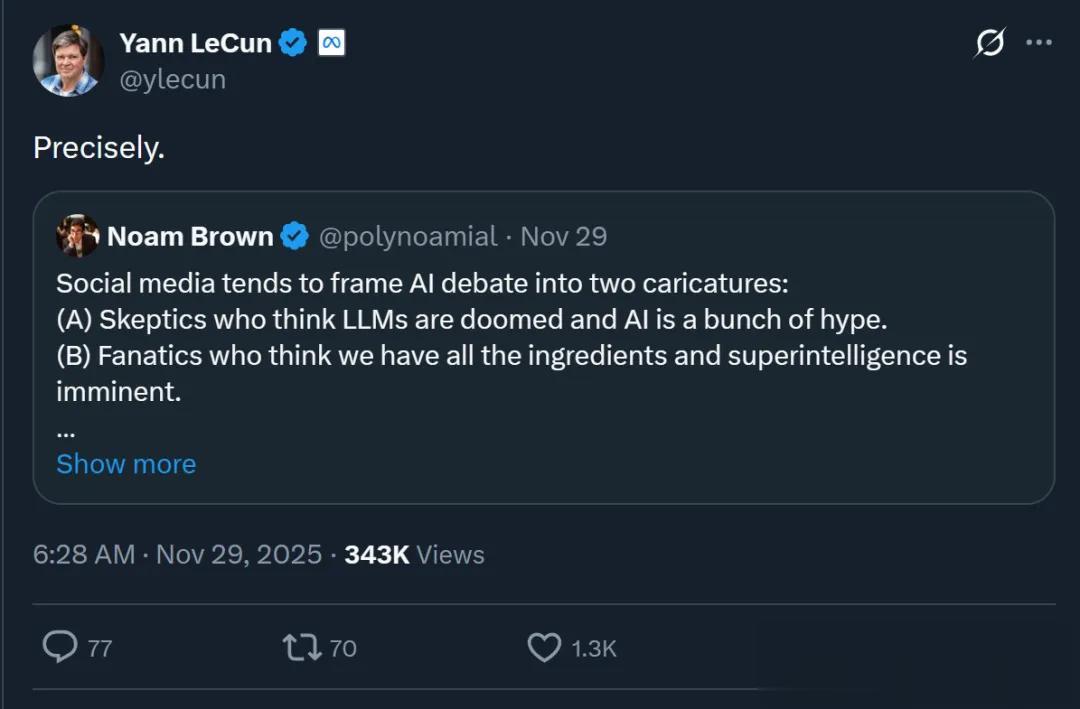
但這時Noam Brown又站出來了(前面提到的o1核心成員) , 他表示:
如今的社交媒體往往會把AI辯論簡化成兩種夸張的刻板印象:
(A)懷疑派 , 認為大語言模型沒戲 , AI純屬炒作 。 (B)狂熱派 , 認為萬事已經俱備 , ASI(超級人工智能)指日可待 。
但如果去看看頂尖研究人員實際上說了什么 , 就會發現他們的觀點有著驚人的共識:
(1)當前的范式即便沒有進一步的研究突破 , 也可能足以帶來巨大的經濟和社會影響;(2)要實現AGI或ASI , 或許還需要更多的研究突破(比如常提到的持續學習和樣本效率);(3)沒人覺得ASI是天方夜譚 , 永遠不會實現 , 分歧主要在于那些“突破”會是什么 , 以及它們來得會有多快 。
這一總結也得到了LeCun的認同:
因此 , 此時回過頭看Hinton和Ilya的分歧 , 其本質或許并不在于要不要Scaling , 而在于——
我們到底在Scaling什么?
參考鏈接:[1
https://www.businessinsider.com/ai-Scaling-debate-geoffrey-hinton-ilya-sutskever-alexandr-wang-lecun-2025-12[2
https://x.com/ilyasut/status/1994424504370581726[3
https://x.com/ylecun/status/1994533846885523852
推薦閱讀














- 富士通加入軟銀牽頭的下一代AI存儲項目
- 消息稱蘋果基礎模型團隊超半數員工來自谷歌 大部分在近2到4年加入
- 北航提出大模型 Scaling Laws:編程語言差異與多語言最優配比策略
- 智源研究院王仲遠:訓練仍有巨大的Scaling空間 | MEET2026
- 我們和田淵棟做了一次年末總結:關于Scaling、頓悟及AGI還有多遠
- 谷歌發布智能體Scaling Law:180組實驗打破傳統煉金術
- 前字節視覺模型AI平臺負責人潘欣已加入美團
- 谷歌豪擲千萬賀壽!Hinton預言OpenAI要輸,CS學位最香
- 哈薩比斯:DeepMind才是Scaling Law發現者,現在也沒看到瓶頸
- Hinton最新預言刷屏:谷歌必贏,而且「早該贏了」!