
文章圖片
文章圖片
文章圖片
文章圖片
騰訊微信 AI 團隊提出 WeDLM(WeChat Diffusion Language Model) , 通過在標準因果注意力下實現擴散式解碼 , 在數學推理等任務上實現相比 vLLM 部署的 AR 模型 3 倍以上加速 , 低熵場景更可達 10 倍以上 , 同時保持甚至提升生成質量 。
引言
自回歸(AR)生成是當前大語言模型的主流解碼范式 , 但其逐 token 生成的特性限制了推理效率 。 擴散語言模型(Diffusion LLMs)通過并行恢復多個 mask token 提供了一種替代方案 , 然而在實踐中 , 現有擴散模型往往難以在推理速度上超越經過高度優化的 AR 推理引擎(如 vLLM) 。
問題的關鍵在于:大多數擴散語言模型采用雙向注意力機制 , 這與標準的 KV 緩存機制不兼容 , 導致并行預測的優勢無法轉化為實際的速度提升 。
近日 , 騰訊微信 AI 團隊提出了 WeDLM(WeChat Diffusion Language Model) , 這是首個在工業級推理引擎(vLLM)優化條件下 , 推理速度超越同等 AR 模型的擴散語言模型 。
論文標題:WeDLM: Reconciling Diffusion Language Models with Standard Causal Attention for Fast Inference 論文作者:劉璦瑋、何明樺、曾少勛、張思鈞、張林昊、武楚涵、賈巍、劉源、周霄、周杰(騰訊微信 AI) 項目主頁:https://wedlm.github.io GitHub:https://github.com/tencent/WeDLM 模型權重:https://huggingface.co/collections/tencent/wedlm
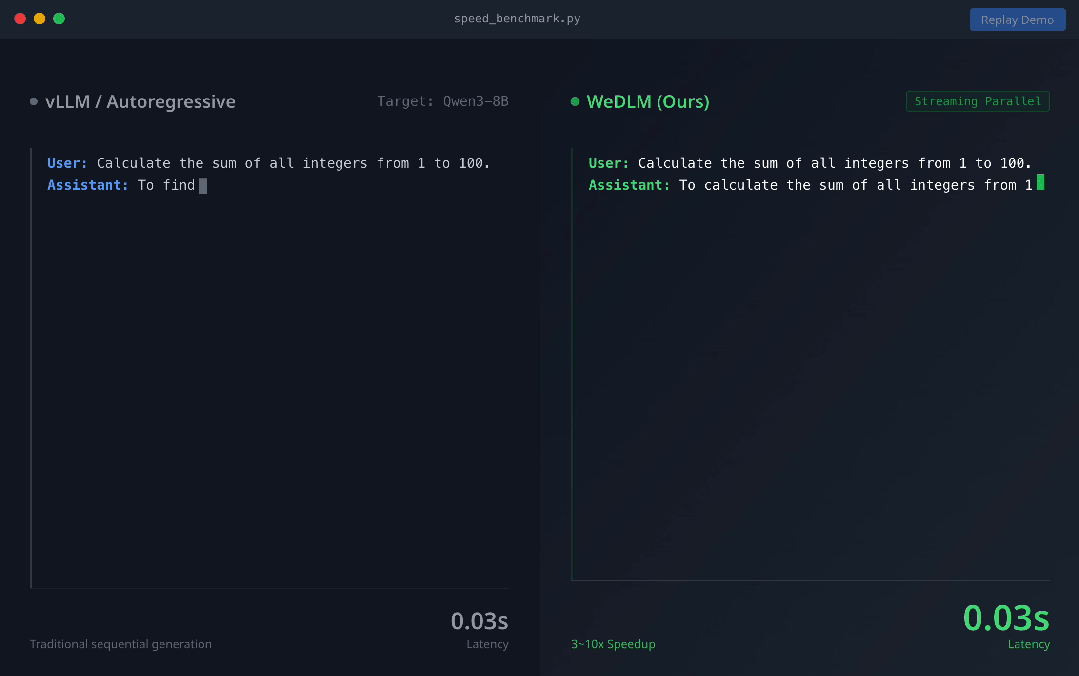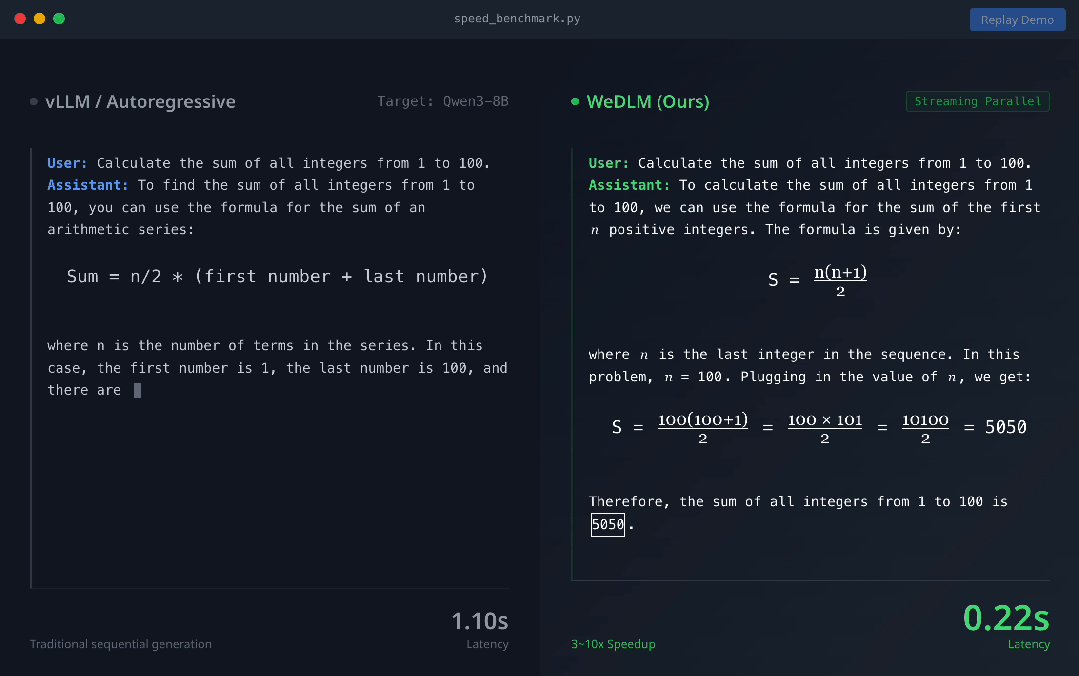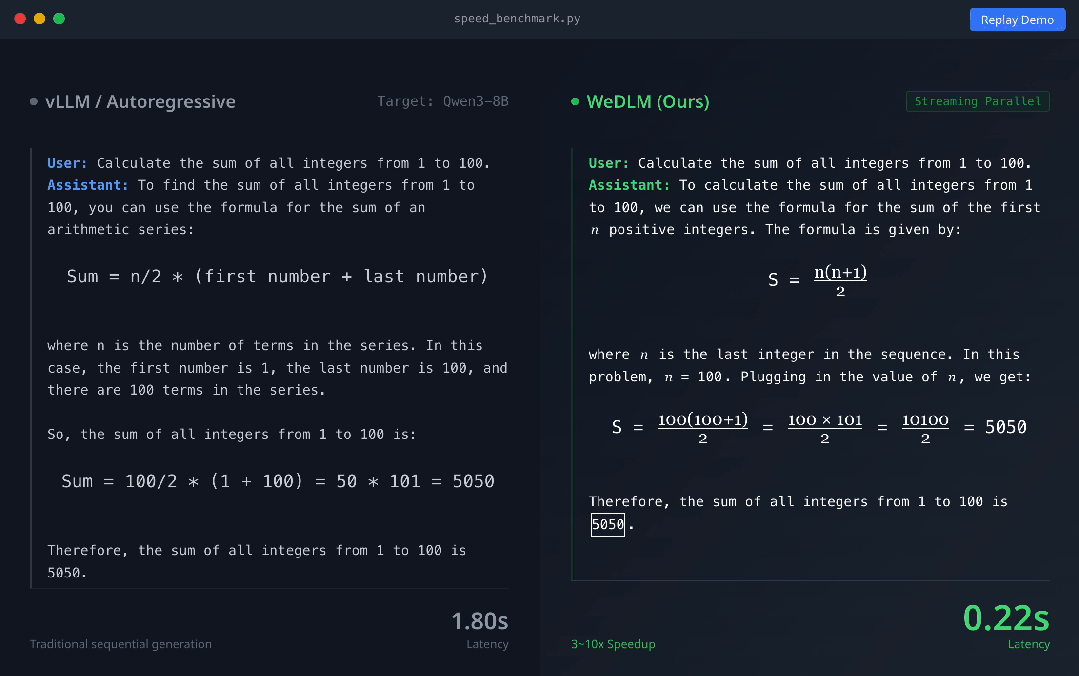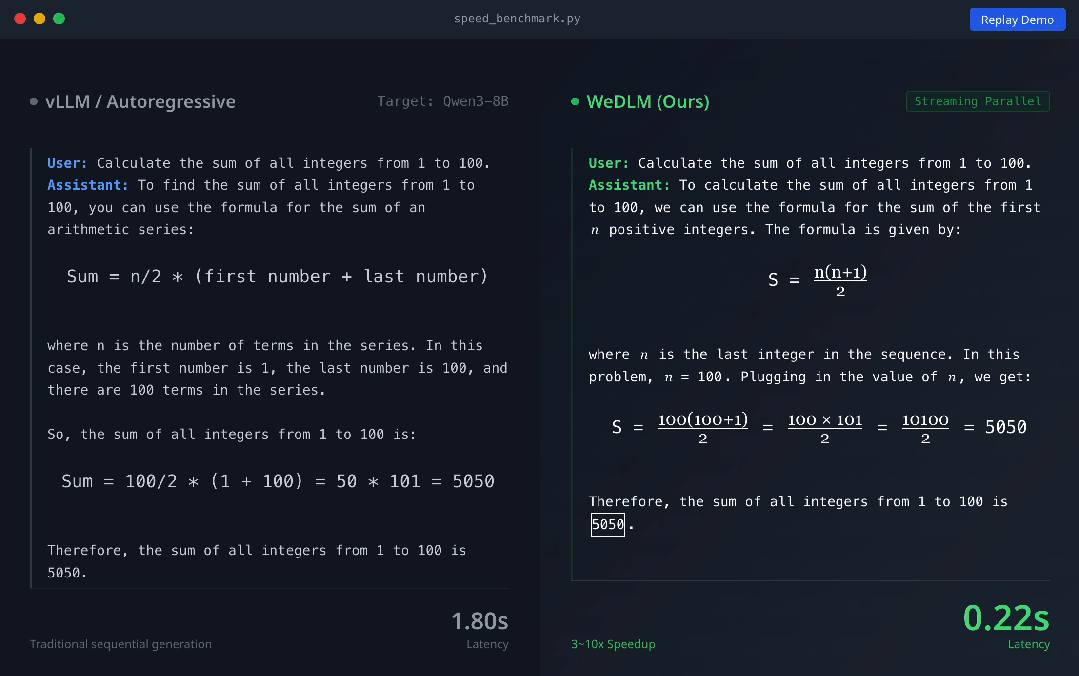
以下是模型效果:
上圖展示了vLLM 部署的 Qwen3-8B-Instruct(左) 與 WeDLM-8B-Instruct(右) 在相同 prompt 下的實時生成對比 。 可以直觀看到 , WeDLM 的生成速度明顯更快 。
核心思路:讓擴散解碼兼容 KV 緩存
WeDLM 的核心洞察是:mask 恢復并不需要雙向注意力 。 擴散式解碼只需要讓每個 mask 位置能夠訪問所有已觀測的 token , 這完全可以在標準因果注意力下實現 。
研究團隊提出了一個關鍵指標 —— 前綴可緩存性(Prefix Cacheability):在 KV 緩存解碼中 , 只有形成連續左到右前綴的 token 才能被緩存復用 。 因此 , 真正影響推理效率的不是「每步預測多少 token」 , 而是「有多少預測能夠轉化為可緩存的前綴」 。
圖:WeDLM-8B 在數學推理任務上實現約 3 倍加速 , 同時在準確率和推理速度上顯著超越 LLaDA、Dream 等擴散模型 。
技術方案
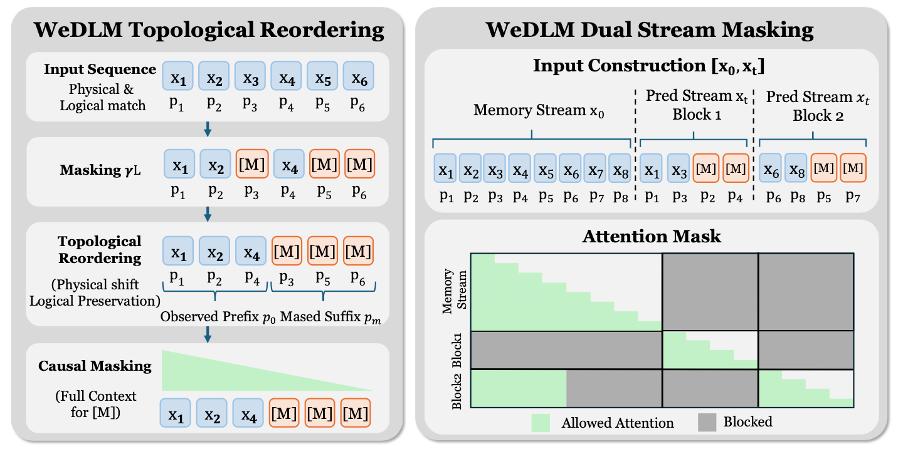
拓撲重排序(Topological Reordering)
WeDLM 通過拓撲重排序在保持因果注意力的同時 , 讓 mask 位置能夠訪問完整的觀測上下文 。 具體而言 , 將所有已觀測 token 移動到物理序列的前端 , 同時通過 RoPE 位置編碼保留其邏輯位置 。 這樣 , 在標準因果 mask 下 , 每個待預測位置都能看到所有已知信息 。
雙流掩碼(Dual-Stream Masking)
為縮小訓練與推理的分布差異 , WeDLM 設計了雙流訓練策略:構建一個干凈的「記憶流」和一個帶 mask 的「預測流」 , 兩者共享位置編碼 。 預測流中的每個 block 從記憶流獲取干凈的歷史上下文 , 而非可能帶噪的中間預測結果 。
流式并行解碼(Streaming Parallel Decoding)
推理階段 , WeDLM 采用流式并行解碼策略:
距離懲罰機制:優先解碼靠左的位置 , 促進左到右的前綴增長 即時緩存:在因果注意力下 , 已解碼 token 立即成為有效緩存 動態滑動窗口:持續填充新的 mask 位置 , 避免 block 邊界的等待開銷 【微信煉出擴散語言模型,vLLM部署AR模型3倍加速,低熵場景超10倍】
圖:傳統 block 解碼需要等待整個 block 完成才能提交 , 而 WeDLM 的流式解碼可以即時提交已解析的前綴 。
實驗結果
生成質量
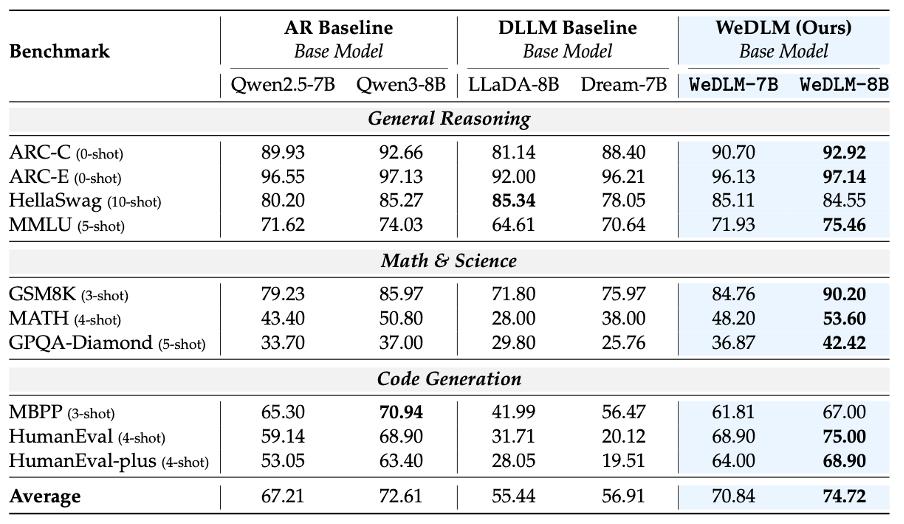
WeDLM 基于 Qwen2.5-7B 和 Qwen3-8B 進行訓練 , 使用 100B token 進行繼續預訓練 , 10B token 進行 SFT 。
在 base 模型評測中 , WeDLM-8B 平均得分 74.72 , 超越 Qwen3-8B(72.61)2.1 個點 。 在數學推理任務上提升尤為顯著:GSM8K 提升 4.2 個點 , MATH 提升 2.8 個點 。
在 instruct 模型評測中 , WeDLM-8B-Instruct 平均得分 77.53 , 超越 Qwen3-8B-Instruct(75.12)2.4 個點 , 也領先于 SDAR-8B-Instruct(74.22)等擴散模型 。
推理速度
關鍵亮點:所有速度對比均基于 vLLM 部署的 AR 模型基線 , 而非未優化的實現 。
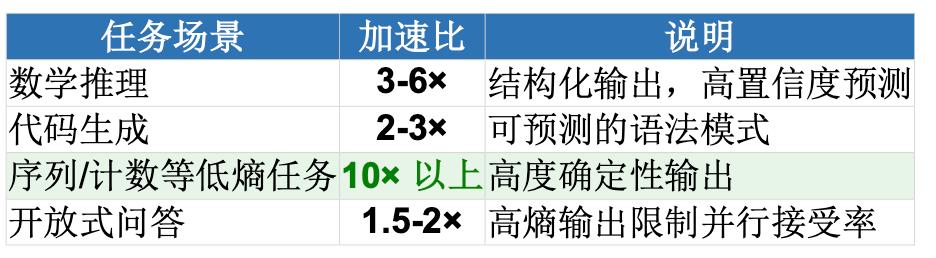
研究團隊在論文中展示了不同熵值場景下的速度差異:
低熵場景(如計數任務):由于輸出高度可預測 , 模型可以大膽并行預測并接受多個 token , 實測達到 1673.3 tokens/s 中熵場景(如數學推導):結構化的推理步驟仍然具有較好的可預測性 , 實測 745.2 tokens/s 高熵場景(如開放問答):語義多樣性高 , 并行接受率下降 , 實測 197.8 tokens/s
快速上手
安裝方式非常簡單 , 只需通過 pip 從 GitHub 安裝即可 。 安裝完成后 , 可使用 Python API 快速調用模型進行推理 。 詳細的使用文檔和示例代碼請參見項目 GitHub 主頁 。
總結
WeDLM 的貢獻可以歸納為:
因果擴散框架:在標準因果注意力下實現 mask 恢復 , 天然兼容 KV 緩存和現有推理基礎設施(FlashAttention、PagedAttention、CUDA Graphs 等) 流式并行解碼:通過距離懲罰和動態滑動窗口 , 最大化前綴提交率 首次在速度上超越工業級推理引擎部署的 AR 模型:在 vLLM 優化條件下的公平對比中 , 數學推理實現 3 倍以上加速 , 低熵場景超過 10 倍
研究團隊指出 , 這項工作表明「前綴可緩存性」應當作為并行文本生成的一等設計目標 。 未來的擴散語言模型應更多地被視為高效的多 token 預測機制 —— 并行生成 token 的價值 , 取決于這些 token 能多快地轉化為可緩存的前綴 。
推薦閱讀















- 微信 2026 首波更新,這功能終于改了
- 安卓微信發布8.0.67正式版,設置、存儲空間等功能進行優化
- 7B擴散語言模型單樣例1000+ tokens/s!上交大聯合華為推出LoPA
- 微信更新,又添一顆「后悔藥」!
- 微信回應關于占存儲空間的誤解:占用 40GB 以上的用戶,聊天記錄平均占比達 70%
- 微信安裝包10多年膨脹幾百倍!為何這么吃內存?官方終于說清楚了
- 清華朱軍團隊:多模態擴散模型實現心血管信號實時全面監測
- 安裝包10年膨脹數百倍,微信官方回應:在優化了
- 微信支付寶更新,適配 iOS 26
- 抖音推出長圖文功能,和微信公眾號類似