
文章圖片

文章圖片
文章圖片
為破解長期以來學界與業界難以對數據進行價值量化的困局 , 上海人工智能實驗室(上海 AI 實驗室)OpenDataLab 團隊在今年 8 月正式開源了首個全面、公正的后訓練數據價值評測平臺 ——OpenDataArena (ODA)。 該項目致力于將數據選擇從「盲目試錯」的煉丹術 , 轉變為一門可復現、可分析、可累積的嚴謹科學 。
在初版系統發布后的數月間 , 項目通過團隊內部及小范圍社區用戶的深度使用 , 完成了高強度的技術驗證與功能打磨 。 伴隨著評測規模、工具鏈和分析能力的持續擴展 , 近期 , 我們終于迎來了 ODA 的全面升級 —— 一個結論更系統、功能更完整、視角更多元的正式版本 , 該項目正式面向全體開發者開放 。
項目主頁: https://opendataarena.github.io/ 開源工具: https://github.com/OpenDataArena/OpenDataArena-Tool 數據集: https://huggingface.co/OpenDataArena/datasets 報告鏈接:https://arxiv.org/pdf/2512.14051
ODA 的核心理念非常明確:數據價值必須通過真實的訓練來檢驗 , 而非主觀的臆測 。 為此 , 我們立足于全新發布的正式版本 , 對平臺進行了體系化的深度重構 , 由四個相互支撐的核心模塊組成了這套完整的數據評測基礎設施 。 這標志著 ODA 已經從最初的功能驗證階段 , 發展成為可以對數據價值進行系統化評測的重要平臺 。
一、數據價值排行榜
首先 , ODA 項目打造了數據價值排行榜 。 通過構建一套統一的訓練與評測流程 , 讓數據在固定的模型規模(如 Llama3、Qwen2/3 7-8B)和訓練配置下 , 對來自不同領域的文本及多模態數據進行橫向評測 。
評測覆蓋通用、數學、代碼、科學與長鏈推理等能力維度 , 這使得數據價值能直接通過下游任務(如數學、代碼、推理等)的實際表現來量化 , 而非主觀判斷 。 目前 , ODA 平臺已經從初版僅僅只有文本數據的評測 , 擴展到了多模態數據集的質量評測 , 并以最先進的 Qwen3-VL 作為真實訓練的基準模型 。
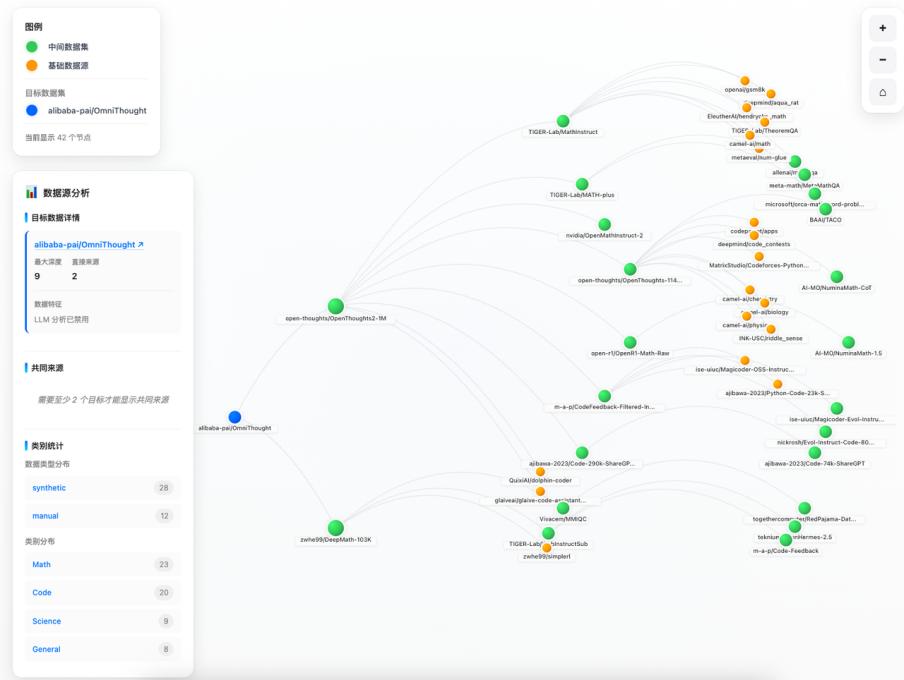
二、數據血緣探索器
其次 , 針對數據界常見的「近親繁殖」問題 , ODA 全新發布「數據血緣探索器」 。 它像繪制族譜一樣 , 清晰地刻畫出數據集之間的繼承、混合與蒸餾關系 。 通過結構化建模與可視化展示 , 研究者可以直觀地看到不同數據集之間的高度重疊與依賴關系 , 看到社區中被反復復用的核心數據源 , 以及更清晰的發現潛在的訓練–測試污染與「近親繁殖」問題 。 這一能力讓「為什么某些數據集長期霸榜」不再是經驗結論 , 而是可以被結構性解釋的現象 。
三、多維數據評分器
除了看模型結果 , ODA 還從數據本體出發 , 對數據質量進行細粒度刻畫 。 ODA 提供了一個細粒度的評分框架 , 基于模型評估、LLM-as-a-Judge 與啟發式指標等多種方法 , 從指令復雜度、響應質量、多樣性等維度對數據進行深度剖析 , 生成每份數據的專屬「體檢報告」 , 并已對千萬級樣本的評分結果進行開源 。這使得研究者不僅能判斷「哪份數據更有效」 , 還能進一步分析它為什么有效 。 值得一提的是 , 在初版的基礎上 , ODA 多維數據評分器目前已經擴展支持 80+ 種多維度的評分器 , 支持用戶一鍵方便的對所需要的數據維度進行打分 。
四、全開源評測工具箱
此外 , 為了促進社區共建 , ODA 完全開源了其訓練、評分和可視化工具 , 覆蓋從模型微調到結果復現的完整流程 , 以及上述精細化的數據評價打分器 。 ODA 工具支持用戶一鍵復現結果 , 或對自己私有數據進行標準化評測 , 實現真正意義上的橫向對比 。
五、硬核發現:那些被忽視的數據真相
在對 120 多個主流數據集進行超過 600 次訓練和 4000 萬條數據的深度分析后 , OpenDataLab 團隊得出了一系列具有指導意義的「硬核」結論 , 足以重塑業界對高質量數據的認知 :
1. 解答質量比問題復雜度更關鍵: 實驗發現 , 單純增加問題的復雜度并不能有效預測數據價值 。 相反 , 解答的長度(推理過程的充分性)與最終質量呈強正相關 , 這在數學和科學類任務中尤為突出 。
2. 代碼數據的「異類」屬性: 搞代碼模型不能照搬數學的邏輯 。 代碼講究簡潔精準 , 長篇大論反而會損害效果 。 這意味著通用的評分標準在代碼領域經常失效 , 必須建立針對性的評估體系 。
3. 開源數據「近親繁殖」嚴重: ODA 的數據血緣分析顯示 , 社區反復依賴的核心數據源比較有限(例如 GSM8K 被多次復用) , 由此造成了嚴重的數據同質化 。 借助數據血緣分析 , 更極端的發現是 , 數據污染越來越嚴重:大量訓練樣本直接與測試集發生重疊 。
4.「少即是多」的局限性: 盡管 LIMA 等研究曾宣稱少量精選數據即可成功 , 但 ODA 的實驗證明這極度依賴模型底座的先天能力 。 如果底座一般 , 過少的數據量會導致性能崩塌 。 真正穩健的路徑是追求「高質量且具規模(High-Density Volume)」 的數據配方 。
5. 為什么有些數據集能霸榜? 以 AM-Thinking-distilled 為代表的超大規模聚集型數據集 , 能夠同時在數學與代碼任務上取得明顯的優勢 , 關鍵原因在于其跨領域融合能力 。 它通過遞歸方式整合了 435 個數據節點 , 顯著提升了數據分布的多樣性與互補性 。
6. 數據可以彌補底座差距: 這是一個令人振奮的發現 。 即使 Llama 3.1 和 Qwen 2.5 之間存在顯著的底座分差 , 只要用上如 OpenThoughts3-1.2M 這樣的高質量微調數據 , 這個差距幾乎可以被抹平 。 可以說 , 好的數據配方真的能讓模型「逆天改命」 。
未來展望
OpenDataArena 的遠景 , 絕不不滿足于僅僅建立一個排行榜 , 更致力于將數據研發從「玄學」推向可復現、可分析的「科學」 。 未來 , ODA 將持續進化 , 探索智能體數據 , 金融、醫療等垂直領域的深層價值 。
【OpenDataArena升級版正式上線,四大核心模塊重構數據價值評估】在這個數據決定 AI 上限的時代 , 唯有手握科學的標尺 , 才能精準丈量每一份數據的真實「重量」 。
推薦閱讀















- iOS 26.3正式版即將發布,除了支持安卓設備,新功能幾乎掛零?
- 華為再領先!低軌衛星通信二季度正式開放,Mate X6典藏版率先支持
- 年輕人第一臺徠卡! 小米17 Ultra徠卡版正式開售:7999元起
- 安卓微信發布8.0.67正式版,設置、存儲空間等功能進行優化
- 1月又一款新機官宣:1月8日,正式發布
- 臺積電2nm正式量產!你猜第一家首發是誰?
- 榮耀WIN系列已正式發布:兩款版本之間,到底有多少區別?
- 蘋果不滿反壟斷裁決正式提起上訴,欲推翻英國法院15億英鎊處罰決定
- 人形機器人標委會正式成立,國內現存機器人相關企業超102萬家
- 臺積電2nm工藝N2正式量產:AMD打破蘋果首發慣例,Zen6處理器搶得先機