
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
就在剛剛 , 清華大學的一項AI for Science研究不僅登上Nature , 而且還被Science深度報道了 。
這項來自清華大學李勇團隊的研究通過分析全球2.5億篇科學文獻 , 揭示了AI for Science領域存在的一個典型矛盾——
AI在助力科學家“個體加速”的同時 , 卻導致科學界的集體注意力窄化和趨同優化的“群體登山”現象 。
就是說 , 雖然AI幫助科學家發表了更多論文、更早成為項目負責人 , 但卻導致人們集體涌入少量適合AI研究的“熱門山峰” , 從而無形中削弱了科學探索的廣度 。
而且進一步分析表明 , 這一矛盾絕非偶然 , 而是由當前科學智能AI模型缺乏通用性導致的系統性影響 。
下面詳細來看這到底是一項怎樣的研究 。
第一步:尋覓AI for Science的演化蹤跡回到起點 , 團隊之所以進行這項研究 , 主要是發現AI for Science領域存在一個明顯矛盾——
在AI持續賦能科研的背景下 , 為何各學科的整體科學進展未見明顯加速?
一方面 , AI for Science研究已經產生了AlphaFold這樣的榮獲諾貝爾獎的成果;但另一方面 , 統計表明各學科領域的顛覆性研究成果在逐年下降 , 似乎未能獲得AI助力 。
這背后的原因到底是什么?到目前為止 , 業界仍然沒有明確答案 。
于是 , 團隊向著這一問題出發了 , 并最終發表了《Artificial Intelligence Tools Expand Scientists’ Impact but Contract Science’s Focus》這篇論文 。
在論文中 , 團隊進行的首項工作是:從浩如煙海的文獻中找出那些“AI賦能的研究” 。
這一步對后續定量刻畫AI對科學的影響至關重要 。
為此 , 團隊摒棄了停留在關鍵詞層面的淺層檢索方法 , 而提出了一條“高質量專家標注 + 大規模語言模型推理“相結合的技術路徑——
通過領域專家標注少量論文樣本 , 再讓語言模型大規模推理的迭代優化 , 逐步讓語言模型學會從標題和摘要中深層次的分析“那些是使用了AI工具的研究” 。
論文顯示 , BERT的識別準確率非常高 , 達到了0.875分(滿分為1) 。
靠著這套方法 , 他們掃描了近50年來的海量文獻(涵蓋1980-2025年) , 最終畫出了一張“AI賦能科研全景地圖” 。
這張地圖橫跨“機器學習、深度學習、生成式AI”三個時代 , 涵蓋4130萬篇論文、覆蓋2857萬研究者 , 被團隊視為研究“AI如何系統性影響科研”的首個基準數據集 。
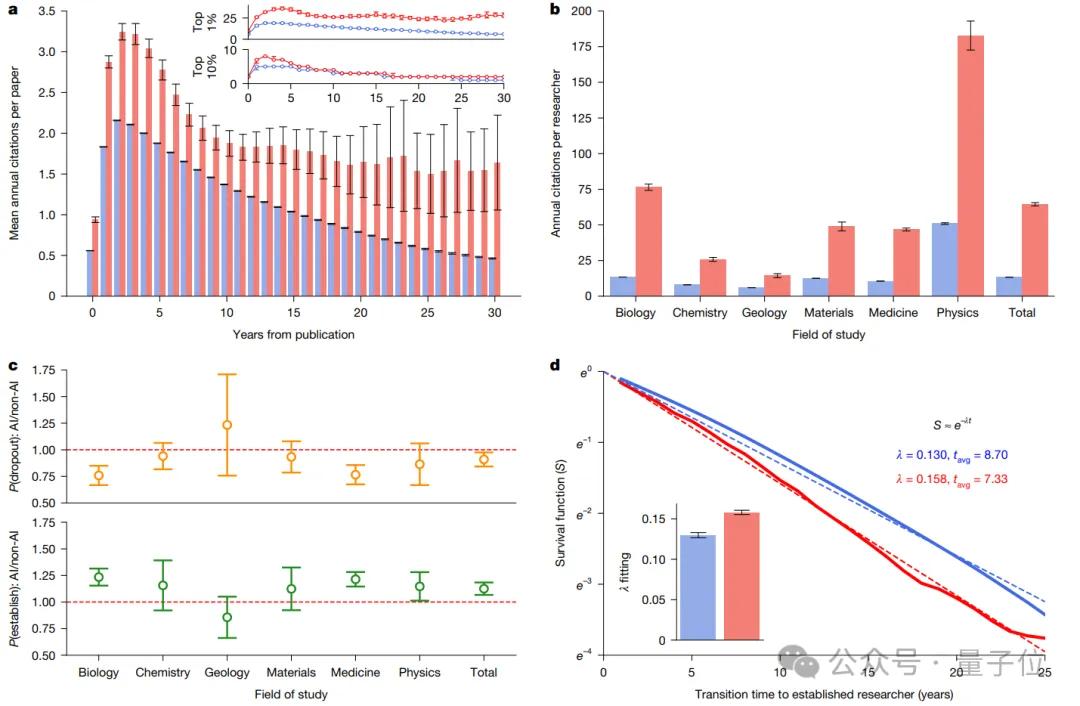
然后…發現AI for Science領域的矛盾效應基于該數據集 , 團隊系統性分析了AI在自然科學六大領域(生物、醫學、化學、物理、材料科學和地質學)的影響 。
所采用的分析方法大致可分為以下三個階段:
step 1:構建“科學語義地圖” step 2:定義衡量“廣度”的指標 step 3:進行比較分析簡單來說 , 團隊想要回答一個關鍵問題——
有了AI的幫助后 , 科學家探索的領域到底是變寬了 , 還是變窄了?
為了客觀衡量這種看不見、摸不著的“認知版圖” , 他們提出了基于隱藏變量的科學學分析方法 。
該方法和傳統科學學的區別在于 , 它不再僅僅依賴論文的標題、關鍵詞、作者、引用關系等“表面”數據 , 而是深入到論文的“思想”和“內容”本身 , 從而能更精細地度量像“知識廣度”這樣抽象的概念 。
具體到第一步 , 他們把每篇論文中最能代表其內容的標題和摘要作為核心文本 , 通過一個深度嵌入表征模型轉換成一個由768個數字組成的、固定長度的數學向量 。
這個向量就是每篇論文在高維數字空間中的“坐標”——理論上 , 語義相似的論文 , 其向量距離也會更接近 。
而當所有論文都找到自己的“坐標”后 , 團隊主要通過“直徑”和熵值這兩個指標來測量知識廣度 。
前者用來衡量探索的“最遠邊界” 。
比如對于某個領域一年的AI論文 , 先計算它們所有坐標點的幾何中心 , 然后找出離中心點最遠的那篇論文 , 測量它們之間的歐氏距離 。
這個距離就是研究中定義的“直徑” , 用于衡量這批論文的主題覆蓋廣度 。 直徑越大 , 說明探索的范圍越廣 。
后者用來衡量分布的“均勻度” 。
這是指分析同一批論文坐標點在空間中的分布狀態——如果均勻分散在空間各處則熵值高 , 反之 , 如果它們緊密地聚集在少數幾個熱點周圍 , 則熵值低 。
然后就用這些指標去分別測量兩類科學家群體的論文:一類是使用AI進行研究的 , 另一類是不使用AI的 。
以此判斷AI究竟是在擴張還是收縮科學的認知邊界 。
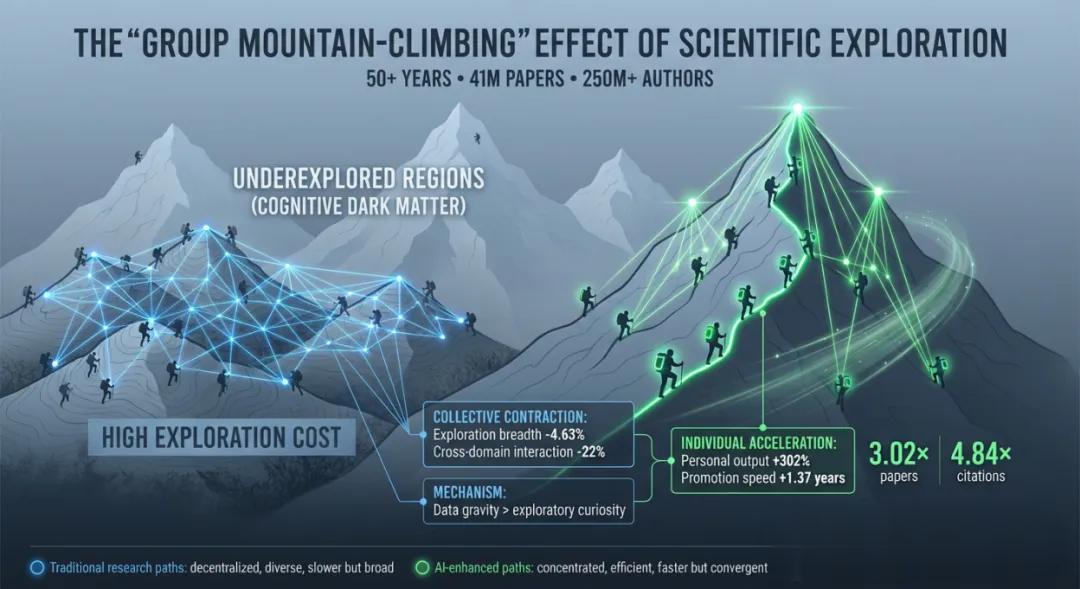
結果發現 , 在微觀個體層面 , 使用AI的科學家比不使用的多發表3.02倍論文 , 獲得4.84倍引用量 。
而且前者更是提早1.37年成為研究項目負責人(以末位作者為標志) 。
然而 , 個體科研加速的背后 , 卻是人類整體科學版圖的異常收縮 。
在集體層面上 , 與AI結合的科研項目的知識廣度下降了4.63%、不同領域科學家間的跨界互動減少了22% , 而且AI論文引用呈現“星型結構”——
幾乎都在引用同一篇或少數幾篇經典的、開創性的AI工作 , 這表明研究趨向集中和單一化 , 缺少創新活力 。
那么問題來了 , 這一矛盾現象究竟是什么導致的呢?
背后原因揭秘:當前模型缺乏通用性論文給出了一個明確結論——
這是由當前AI for Science模型缺乏通用性導致的系統性影響 。
團隊發現 , AI的高效率產生了一種強大的“科學智能引力”效應 。 它引導研究者集體涌向少量適合AI研究的“熱門山峰” , 即那些已有大量數據、適合用現有AI方法快速出成果的研究方向 。
這種“群體登山”模式 , 雖能加速對已知問題的解決 , 卻也在無形中固化了科學探索的路徑 , 系統性地削弱了科學家向“未知山峰”探索的廣度 。
最終就形成了“廣度讓位于速度”的現象 。
團隊表示 , 這一矛盾機制的發現是對AI賦能科研模式的深度反思:
現有的AI for Science雖然極大地促進了局部的效率提升 , 卻難以驅動全鏈條、多領域的科研創新 。
而為了突破這一局限 , 徐豐力、李勇教授團隊最終推出了全流程、跨學科的科研智能體系統—OmniScientist 。 (訪問網址:OmniScientist.ai)
該系統通過深入挖掘大模型智能體的通用推理能力 , 實現跨學科、全流程、多模態的系統性科研支持 , 從而讓AI從“輔助工具”進化為具備“主動提出假說、自主設計實驗、分析結果并形成理論”的“AI科學家” 。
最后 , 這項研究完成單位為清華大學電子工程系、芝加哥大學社會學系 , 通訊作者為徐豐力助理教授、李勇教授、James Evans教授 , 第一作者為清華大學電子工程系博士生郝千越 。
論文:
https://arxiv.org/abs/2412.07727
— 完 —
量子位 QbitAI
【清華新研究,Nature+Science雙殺!】關注我們 , 第一時間獲知前沿科技動態
推薦閱讀














- 已證實!清華姚班陳立杰全職加入OpenAI,保留伯克利教職
- 蘋果折疊屏要來了,傳蘋果拆解OPPO Find N5研究折痕方案
- 時空壺AI同傳耳機CES秀到老外,嘈雜環境中清晰實時翻譯,延遲低至2秒級
- 小米堅決清倉,16GB+1TB跳水3800元,頂配版旗艦降至“谷底價”
- 新研究讓大模型學會主動追問,人機協作效果大幅提升
- 室內戶外、清潔陪伴:科沃斯CES帶來「機器人全家桶」,野心藏不住了?
- 智能清潔卷向「具身智能」:中國軍團站上CES2026,完成全場景布局
- 一加果斷清倉!512GB降價1261元,驍龍8至尊+超窄直屏+輕薄機身
- ?CES觀察|智能眼鏡群雄逐鹿,清潔電器進化“具身智能”
- 英偉達CEO黃仁勛盛贊中國工程師與AI研究者:屬世界頂尖水平