
文章圖片
文章圖片
文章圖片
編輯|Panda
生物智能與人工智能的演化路徑截然不同 , 但它們是否遵循某些共同的計算原理?
最近 , 來自帝國理工學院、華為諾亞方舟實驗室等機構的研究人員發表了一篇新論文 。 該研究指出 , 大型語言模型(LLM)在學習過程中會自發演化出一種協同核心(Synergistic Core)結構 , 有些類似于生物的大腦 。
- 論文標題:A Brain-like Synergistic Core in LLMs Drives Behaviour and Learning
- 論文地址:https://arxiv.org/abs/2601.06851
研究團隊利用部分信息分解(Partial Information Decomposition PID)框架 , 對 Gemma、Llama、Qwen 和 DeepSeek 等模型進行了深度剖析 。
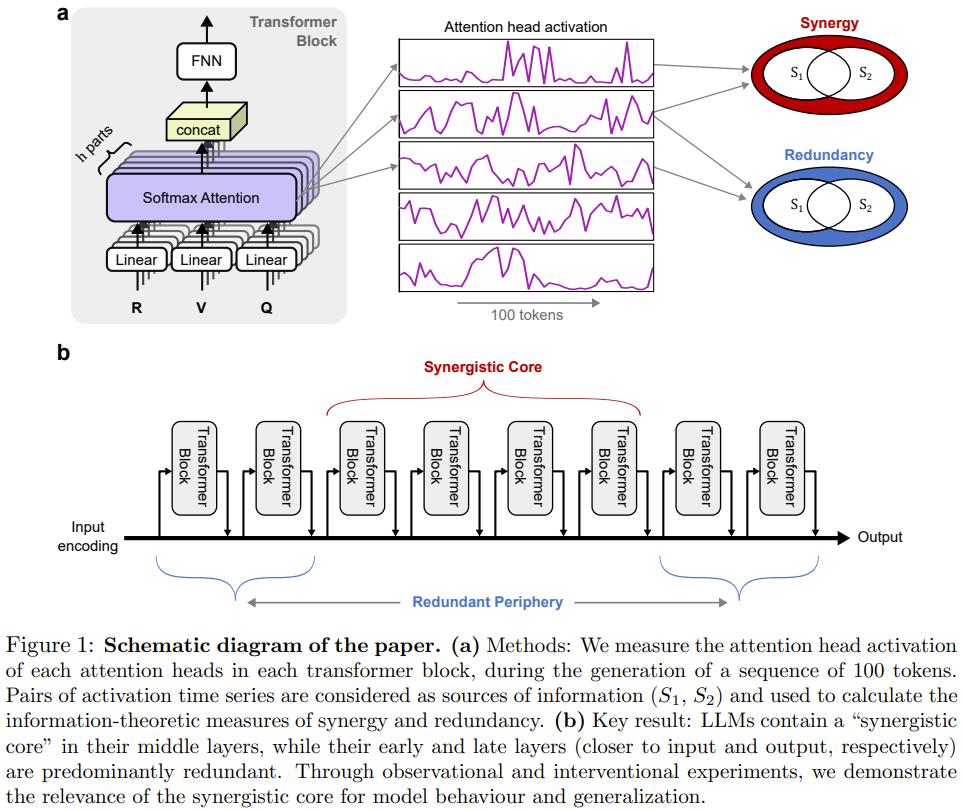
他們發現 , 這些模型的中層表現出極強的協同處理能力 , 而底層和頂層則更偏向于冗余處理 。
協同與冗余:LLM 的內部架構
研究團隊將大型語言模型視為分布式信息處理系統 , 其核心實驗設計旨在量化模型內部組件之間交互的本質 。 為了實現這一目標 , 研究者選取了 Gemma 3、Llama 3、Qwen 3 8B 以及 DeepSeek V2 Lite Chat 等多種具有代表性的模型系列進行對比分析 。
實驗方法與量化指標
在實驗過程中 , 研究者向模型輸入了涵蓋語法糾錯、邏輯推理、常識問答等 6 個類別的認知任務提示詞 。
針對每一個提示詞 , 模型會生成一段 100 個 Token 的回答 , 實驗設備則同步記錄下每一層中所有注意力頭或專家模塊的激活值 。
具體而言 , 研究人員計算了這些輸出向量的 L2 范數 , 以此作為該單元在特定時間步的激活強度數據 。
基于這些時間序列數據 , 研究團隊應用了整合信息分解(Integrated Information Decomposition ID)框架 。
這一框架能夠將注意力頭對之間的交互分解為「持續性協同」和「持續性冗余」等不同原子項 。
通過對所有注意力頭對的協同值和冗余值進行排名并求差 , 研究者得到了一個關鍵指標:協同-冗余秩(Synergy-Redundancy Rank) 。 該指標能夠清晰地標示出模型組件在處理信息時 , 究竟是傾向于進行獨立的信號聚合 , 還是在進行跨單元的深度集成 。
跨模型的空間分布規律
實驗數據揭示了一個在不同架構模型中高度一致的空間組織規律 。 在歸一化后的模型層深圖中 , 協同分布呈現出顯著的「倒 U 型」曲線 :
- 冗余外周(Redundant Periphery):模型的早期層(靠近輸入端)和末期層(靠近輸出端)表現出極低的協同秩 , 信息處理以冗余模式為主 。 在早期層 , 這反映了模型在進行基本的解詞元化(Detokenization)和局部特征提?。 歡諛┢誆?, 則對應著 Token 預測和輸出格式化的過程 。
- 協同核心(Synergistic Core):模型的中層則展現出極高的協同秩 , 形成了核心處理區 。 例如 , 在對 Gemma 3 4B 的熱圖分析中 , 中間層的注意力頭之間表現出密集且強烈的協同交互 , 這正是模型進行高級語義集成和抽象推理的區域 。
架構差異與一致性
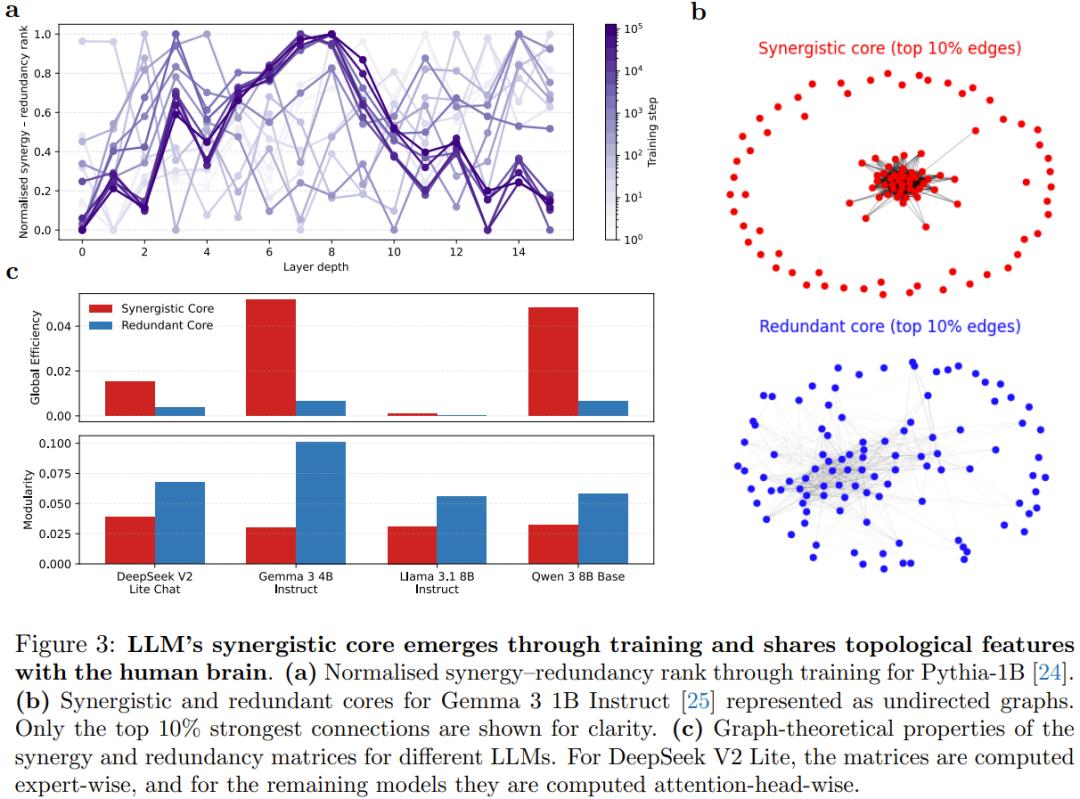
值得注意的是 , 這種「協同核心」的涌現并不依賴于特定的技術實現 。
在 DeepSeek V2 Lite 模型中 , 研究者即使是以「專家模塊」而非「注意力頭」作為分析單位 , 依然觀察到了相同的空間分布特征 。
這種跨架構的收斂性表明 , 協同處理可能是實現高級智能的一種計算必然 , 而非單純的工程巧合 。
這種組織模式與人腦的生理結構形成了精確的映射:人腦的感官和運動區域同樣表現出高冗余性 , 而負責復雜認知功能的聯合皮層則處于高協同的「全局工作空間」中心 。
智能的涌現:學習驅動而非架構使然
一個關鍵的問題在于:這種結構是 Transformer 架構自帶的 , 還是通過學習習得的?
研究人員通過分析 Pythia 1B 模型的訓練過程發現 , 在隨機初始化的網絡中 , 這種「倒 U 型」的協同分布并不存在 。 隨著訓練步數的增加 , 這種組織架構才逐漸穩定形成 。
這意味著 , 協同核心是大模型獲得能力的標志性產物 。
在拓撲性質上 , 協同核心具有極高的「全局效率」 , 有利于信息的快速集成;而冗余外周則表現出更強的「模塊化」 , 適用于專門化處理 。 這種特征再次與人類大腦的網絡架構形成了精確的平行關系 。
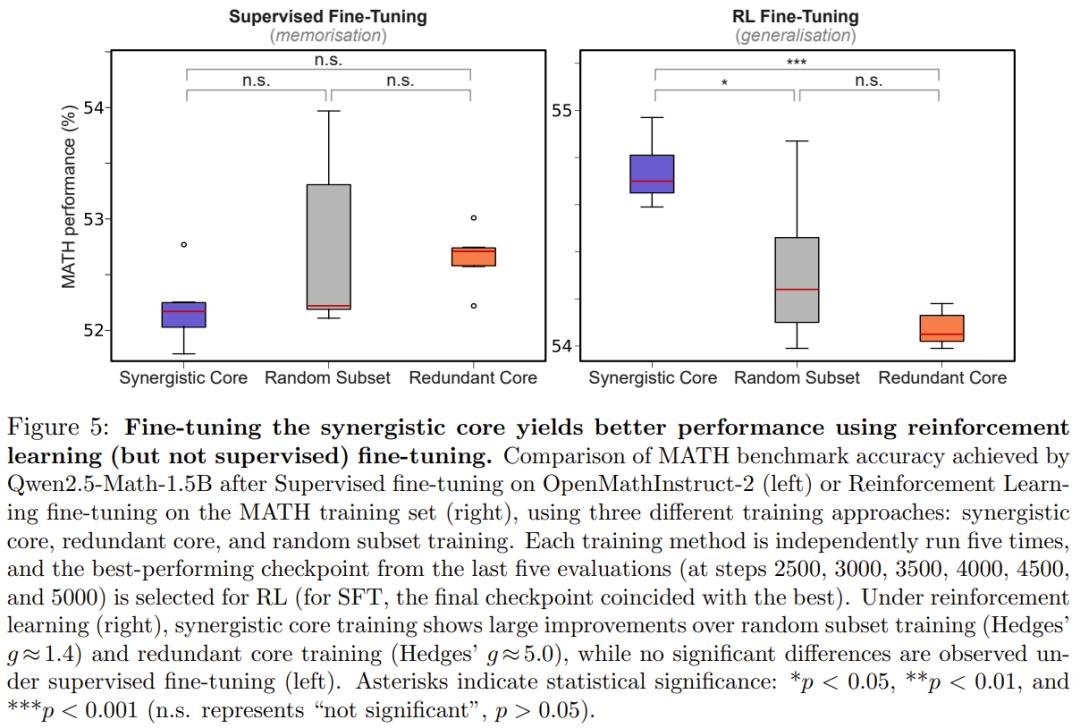
協同核心的功能驗證
為了驗證協同核心是否真的驅動了模型行為 , 研究團隊進行了兩類干預實驗:消融實驗和微調實驗 。
消融實驗:研究發現 , 消融那些高協同性的節點 , 會導致模型出現災難性的性能下降和行為背離 , 其影響遠超隨機消融或消融冗余節點 。 這證明協同核心是模型智能的核心驅動力 。
微調實驗:在強化學習微調(RL FT)場景下 , 僅針對協同核心進行訓練 , 獲得的性能提升顯著優于針對冗余核心或隨機子集的訓練 。 有趣的是 , 在監督微調(SFT)中這種差異并不明顯 。 研究者認為 , 這反映了 RL 促進通用化而 SFT 更多傾向于記憶的特性 。
結語
這項研究為大模型的可解釋性開辟了新路徑 。 它表明 , 我們可以從「自上而下」的信息論視角來理解模型 , 而不僅僅是「自下而上」地尋找特定的電路 。
對于 AI 領域 , 識別協同核心有助于設計更高效的壓縮算法 , 或者通過更有針對性的參數更新來加速訓練 。 對于神經科學 , 這提供了一種計算上的驗證 , 預示著協同回路在強化學習和知識遷移中可能扮演著至關重要的角色 。
大模型雖然基于硅基芯片和反向傳播算法 , 但在追求智能的過程中 , 它們似乎不約而同地走向了與生物大腦相似的組織模式 。 這種智能演化的趨同性 , 或許正是我們揭開通用智能奧秘的關鍵線索 。
【大模型長腦子了?研究發現LLM中層會自發模擬人腦進化】更多詳情請參閱原論文 。
推薦閱讀














- 廣東聯通空芯光纖集采結果出爐 長飛光纖、亨通光電中標
- 折疊屏 iPhone 模具首次曝光,外觀長這樣
- 高管將AI和自動化視為長期戰略投資
- 用AI驅動業務增長的5種方式:讓人類始終參與其中
- 蘋果Mac去年四季度出貨超過700萬 但同比增長率不及主要競爭對手
- AP2O-Coder 讓大模型擁有「錯題本」,像人類一樣按題型高效刷題
- IDC2025:OPPO第四季度國內雙位數增長,安卓唯一
- 百川智能宣布開源全球最強醫療大模型Baichuan-M3,能力超GPT-5.2
- 潛望長焦+大底傳感器!不足3000塊,實力做年輕人「真香機」
- 華為Pura 90 Ultra配置曝光:2億長焦+一英寸可變光圈