文章圖片
文章圖片
文章圖片
「工程師正在瘋狂地分析 DeepSeek , 試圖從中復制任何可能的東西 。 」
DeepSeek 開源大模型的陽謀 , 切切實實震撼著美國 AI 公司 。
最先陷入恐慌的 , 似乎是同樣推崇開源的 Meta 。
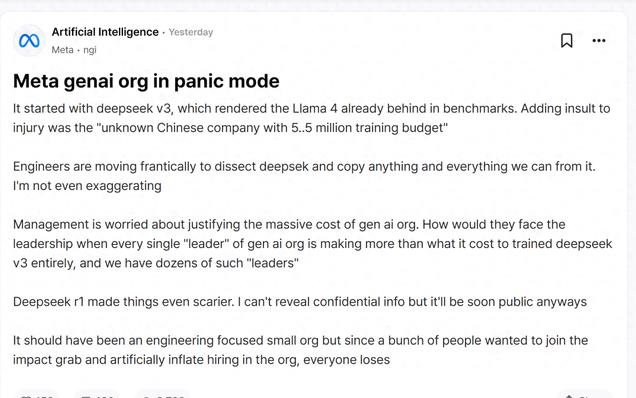
最近 , 有 Meta 員工在美國匿名職場社區 teamblind 上面發布了一個帖子 。 帖子提到 , 國內 AI 創業公司 DeepSeek 最近的一系列動作讓 Meta 的生成式 AI 團隊陷入了恐慌 , 因為在前者的低成本高歌猛進下 , 后者無法解釋自己的超高預算的合理性 。
原文如下:
這一切始于 DeepSeek-V3 , 它在基準測試中就已經讓 Llama 4 落后 。 更糟糕的是那個「擁有 550 萬訓練預算的不知名中國公司」 。
工程師們正在瘋狂地分析 DeepSeek , 試圖從中復制任何可能的東西 。 這一點都不夸張 。
管理層擔心如何證明龐大的生成式 AI 組織的成本是合理的 。 當生成式 AI 組織中的每個「領導」的薪資都比訓練整個 DeepSeek-V3 的成本還要高 , 而我們有好幾十個這樣的「領導」時 , 他們要如何面對高層?
DeepSeek-R1 讓情況變得更加可怕 。 雖然我不能透露機密信息 , 但這些很快就會公開 。
這本應該是一個以工程為重點的小型組織 , 但是因為很多人想要參與進來分一杯羹 , 人為地膨脹了組織的招聘規模 , 結果每個人都成了輸家 。
帖子中提到的 DeepSeek-V3 和 DeepSeek-R1 分別發布于 2024 年 12 月 26 日和 2025 年 1 月 20 日 。
其中 , DeepSeek-V3 在發布時提到 , 該模型在多項評測成績超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他開源模型 , 并在性能上和世界頂尖的閉源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲 。
不過 , 更引人關注的是 , 這個參數量高達 671B 的大型語言模型訓練成本僅 558 萬美元 。 具體來說 , 它的預訓練過程竟然只用了 266.4 萬 H800 GPU Hours , 再加上上下文擴展與后訓練的訓練 , 總共也只有 278.8 H800 GPU Hours 。 相較之下 , Meta 的 Llama 3 系列模型的計算預算則多達 3930 萬 H100 GPU Hours—— 如此計算量足可訓練 DeepSeek-V3 至少 15 次 。
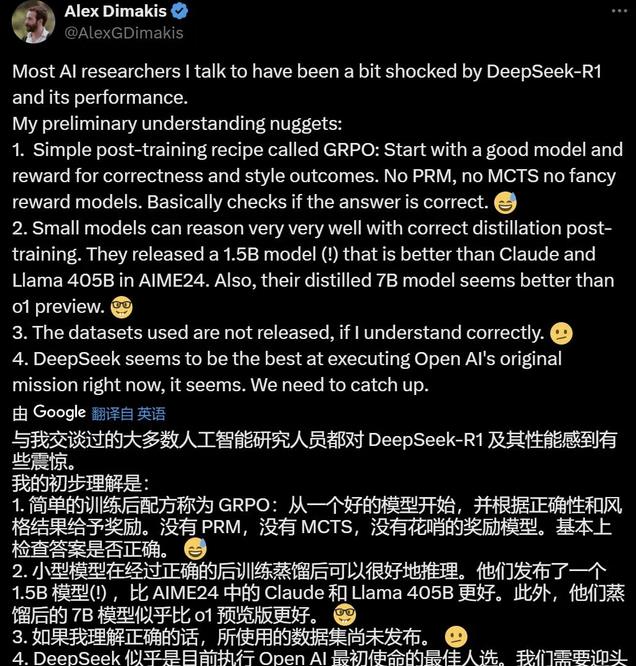
而最近發布的 DeepSeek-R1 性能更猛 —— 在數學、代碼、自然語言推理等任務上 , 它的性能比肩 OpenAI o1 正式版 。 而且模型在發布的同時 , 權重同步開源 。 很多人驚呼 , 原來 DeepSeek 才是真正的 OpenAI 。 UC Berkeley 教授 Alex Dimakis 則認為 ,DeepSeek 現在已經處于領先位置 , 美國公司可能需要迎頭趕上了 。
看到這里 , 我們不難理解為何 Meta 的團隊會陷入恐慌 。 如果今年推出的 Llama 4 沒有點硬本事 , 他們「開源之光」的地位岌岌可危 。
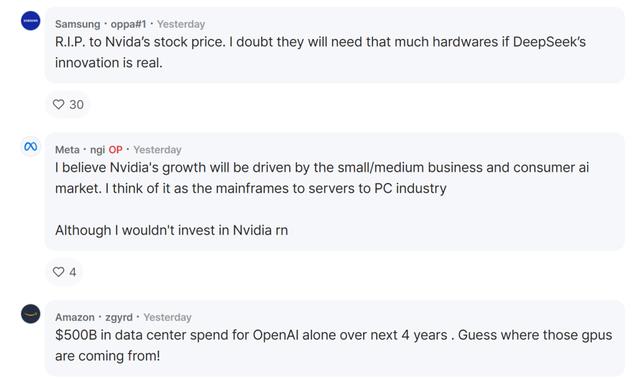
有人指出 , 其實該慌的不止 Meta , OpenAI、谷歌、Anthropic 又何嘗沒有受到挑戰 。 「這是一件好事 , 我們可以實時看到公開競爭對創新的影響 。 」
還有人擔心起了英偉達的股價 , 表示「如果 DeeSeek 的創新是真的 , 那 AI 公司是否真的需要那么多顯卡?」
不過 , 也有人質疑 , DeepSeek 究竟是靠創新還是靠蒸餾 OpenAI 的模型取勝?有人回復說 , 這可以從他們的發布的技術報告中找到答案 。
目前 , 我們還無法確定帖子的真實性 。
【Meta陷入恐慌內部爆料在瘋狂分析復制DeepSeek, 高預算難以解釋】不知道 Meta 后續將如何回應 , 即將到來的 Llama 4 又會達到怎樣的性能 。
推薦閱讀












- 平臺發起大量退款,亞馬遜一類目陷入震蕩!
- Meta智能眼鏡火爆
- 近期存儲市場陷入低谷
- AI年末“狂歡”!OpenAI、谷歌、Meta、李飛飛發布重磅產品
- 歐盟將強制禁用華為5G,華為損失超2500億,專家:華為要陷入危機
- 美國芯片制裁讓臺積電陷入兩難,“芯片戰”升級引發市場不小風波
- 美國專家:中國芯片大擴產,或卷死全世界,美國已感到恐慌
- 日本研發6G成功,引發國內專家恐慌,卻無意中撕下5.5G的遮羞布
- 日本研發成功,引發國內專家恐慌,卻無意中撕下遮羞布
- 220億美元的賭注,Meta的新現金奶牛:WhatsApp