
文章圖片
近日 , 博通發布了高性能交換芯片 , 宣布開始出貨Tomahawk 6 系列交換機 , 并將其稱為“全球首款 102.4Tbps 交換機” 。 國外科技網站All About Circuits 采訪了博通數據中心交換機產品線經理皮特·德爾·維奇奧(Pete Del Vecchio) , 以便更直接地了解這款產品 。
Tomahawk 6——102.5 Tbps 交換芯片
隨著AI 工作負載持續突破數據中心邊界 , 博通報告稱 , 計劃于 2025 年部署的每一個大規模 AI 網絡都將采用基于以太網的架構 , 而非 InfiniBand 。
德爾·維奇奧表示:“回顧過去一年半到兩年間的情況 , 從 InfiniBand 到以太網的轉變十分顯著 。 如今 , 最大的 AI 集群正在采用以太網部署 , 其性能可與 InfiniBand 相媲美 , 甚至更優 。 ”
在此背景下 , 博通的Tomahawk 6 是一款 102.4 Tbps 交換芯片 , 旨在鞏固以太網作為超大規模 AI 集群統一架構的地位 。
Tomahawk 6-100G(左)與 Tomahawk 6-200G(右)
Tomahawk 6 在前代產品(即 Tomahawk 5 的 51.2 Tbps)的基礎上進行了升級 , 并融入了專為 AI 驅動通信模式設計的新功能 。 此次升級的核心在于支持 100G 和 200G PAM4 串行器/解串器(SerDes) , 包括 1024 條 100G 通道或 512 條 200G 通道的選項 , 并提供電可插拔和共封裝光學模塊 。 這種靈活性使系統架構師無需更改核心芯片 , 即可為傳統基礎設施和前沿光學拓撲結構調整互連配置 。
【全球首款 102.4T 以太網交換機芯片!】支持規模擴展與橫向擴展的AI 工作負載
博通在設計Tomahawk 6 時 , 明確旨在滿足 AI 基礎設施中規模擴展和橫向擴展網絡的不同需求 。 規模擴展互連將緊密耦合計算節點內的擴展處理單元(XPU)連接起來 , 以實現高吞吐量內存訪問和低延遲模型并行 。 為此 , Tomahawk 6 在規模擴展域中支持多達 512 個 XPU 的單跳連接 , 其規模是現有解決方案的七倍多 。
通過集成博通的規模擴展以太網(SUE)框架 , 該芯片支持通過標準以太網在 XPU 之間進行基于內存語義的通信 , 從而減少對 NVLink 等專有互連的依賴 。 在解釋 Tomahawk 6 規模擴展支持的設計理念時 , 德爾·維奇奧表示:“使用 Tomahawk 6 , 你可以擴展至 512 個 GPU 或 XPU……出于延遲原因 , 以及通信和擁塞管理方面的考慮 , 你希望實現單跳 , 即僅通過一個交換機跳轉 。 ”
Tomahawk 6 支持開放的規模擴展以太網
在橫向擴展部署中 , 該交換機提供了構建扁平化兩層拓撲所需的帶寬和端口密度 , 每個集群可支持100000 個或更多 XPU 。 而端口速度較低的競爭性交換機則需要三層拓撲才能達到相同的覆蓋范圍 , 這會導致光學模塊數量增加 67% , 由于額外的跳轉而增加延遲 , 以及網絡功耗大約翻倍 。 Tomahawk 6 的 102.4 Tbps 帶寬支持使用更少組件構建大型 Clos 架構 , 從而降低基礎設施開銷和總擁有成本 。
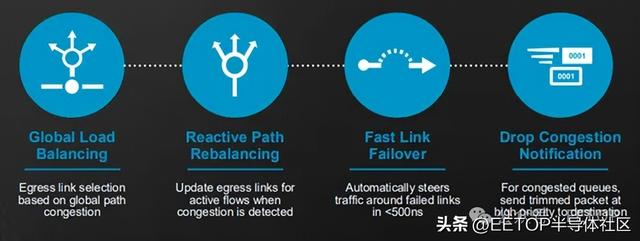
全負載下的Cognitive Routing與負載均衡
傳統數據中心交換機通常在70% 以下的利用率下運行 , 以緩解擁塞并減少尾部延遲 。 然而 , AI 網絡必須將架構利用率提高到 90% 以上 , 以滿足大規模模型訓練和推理的需求 。 為了在這種高強度下保持性能 , Tomahawk 6 集成了博通的下一代自適應路由和遙測套件——Cognitive Routing 2.0 。
該交換機利用全網智能 , 根據實時擁塞指標動態重新平衡流量 。 與靜態等價多路徑(ECMP)路由或基于哈希的方案相比 , Tomahawk 6 在全局了解路徑擁塞情況的基礎上進行出站鏈路選擇 。 在實際應用中 , 這可在負載下實現高達 50% 的吞吐量提升 , 且對鏈路故障的響應時間比標準以太網故障轉移機制快 10000 倍 。 該系統可將活躍流量從性能下降的路徑中轉移出去 , 并可修剪和重傳擁塞的數據包 , 以在不中斷的情況下保持性能 。
博通Cognitive Routing 2.0
Cognitive Routing 2.0 還增強了對任意拓撲的支持 , 包括 Clos、環形、軌道優化和規模擴展域 。 它集成了實時物理鏈路監控功能 , 通過在故障發生前識別性能下降的光學或銅纜通道 , 實現預測性維護 。
節能光學與靈活互連
功率密度限制仍然是超大規模AI 集群擴展的一個關鍵因素 。 在當今的 AI 數據中心中 , 光學模塊占網絡功耗的比例高達 70% 。 Tomahawk 6 通過實現原本需要三層設計的兩層架構來緩解這一問題 。 可插拔光學模塊和共封裝光學模塊(CPO)變體的可用性 , 使運營商能夠進一步控制熱包絡 。 對此 , 德爾·維奇奧解釋道:
“如果你需要使用其他技術 , 就無法在兩層架構中連接這些 GPU 。 你將不得不采用三層網絡架構 。 最終 , 你將使用 67% 更多的光學模塊 , 且網絡功耗幾乎翻倍 。 ”
博通的CPO 選項借鑒了前幾代 Tomahawk 的經驗 , 提供了更低的功耗和更少的鏈路抖動 。 該芯片還支持擴展距離的直連銅纜(DAC)和被動背板連接 , 利用了博通的 SerDes 設計 , 該設計在 200G PAM4 下可實現超過 45 dB 的信道覆蓋范圍 。 這些功能使超大規模數據中心能夠在不犧牲端口覆蓋范圍或無需高功耗、基于數字信號處理器(DSP)的光學模塊的情況下 , 部署高密度、低功耗的交換機互連 。
面向AI 基礎設施的統一開放平臺
最終 , 博通將Tomahawk 6 定位為垂直整合以太網平臺的一部分 , 該平臺涵蓋交換機、網絡接口卡(NIC)、光學模塊和軟件 。 該交換機本身可與博通的 Thor NIC 和 NIC 芯片組互操作 , 這些芯片組可集成到 XPU 中 , 以實現靈活的端點調度 。 它還符合超以太網聯盟(Ultra Ethernet Consortium)的規范 , 可與開源擁塞管理、遙測標準和 AI 模型傳輸協議兼容 。
這種開放標準導向有助于希望優化XPU 通用性的超大規模數據中心 。 無論接口是用于規模擴展還是橫向擴展網絡 , 運營商都可以根據工作負載需求動態重新配置它 。 綜合考慮 , 這種靈活性減少了硬件的分散性 , 使云提供商能夠優化 GPU 分配 , 而無需鎖定到特定的互連角色或拓撲結構中 。
行業展望
在AI 模型復雜性和硬件加速需求呈指數級增長的環境下 , 博通通過 Tomahawk 6 采取的方法反映了網絡在系統性能和效率中處于核心地位的更廣泛趨勢 。 正如德爾·維奇奧所說:“我們在這里所做的 , 實際上是讓網絡和所有訓練變得更加高效……這樣你就可以讓網絡不再成為障礙 , 讓 GPU 之間的流量盡可能快速地通過 。 ”
博通認為 , 在芯片和架構層面優化互連的競賽將決定AI 系統設計的下一階段 , 并希望 Tomahawk 6 能使其在這場競賽中占據領先地位 。
推薦閱讀













- 搭載全球首款102.4Tbps交換機芯片,博通 Tomahawk 6 正式出貨
- 首款鴻蒙5高端旗艦!華為Pura 80 Pro+來了
- 被網友認為快要倒閉的三星:4項全球第一,國產還不是對手
- DeepSeek R1完成升級,成為全球前二AI實驗室
- 京東方推出首款集成AES 3.0協議的OLED筆電顯示屏
- 450Wh/kg量產!陀普科技超高性能電池斬獲全球頭部無人機企業青睞
- AI眼鏡Rokid Glasses即將上市,全球訂單火爆
- 全球首款移動2nm芯片!蘋果A20重大飛躍:手機SoC史上第一次
- 韓媒:暴增93%,中國橫掃全球設備!
- 領先全球的第一架F-600重載共軸無人直升機江門起飛