
文章圖片
文章圖片

文章圖片

文章圖片
論文第一作者譚宇喬來自中國科學院自動化研究所的自然語言處理和知識工程研究組 , 導師為何世柱老師 。 目前研究方向主要在利用大語言模型參數知識增強大模型能力 。
1 跨規模參數知識遷移 PKT 的全面分析
【傳統符號語言傳遞知識太低效?探索LLM高效參數遷移可行性】人類的思維是非透明的 , 沒有繼承的記憶 , 因此需要通過語言交流的環境來學習 。 人類的知識傳遞長期依賴符號語言:從文字、數學公式到編程代碼 , 我們通過符號系統將知識編碼、解碼 。 但這種方式存在天然瓶頸 , 比如信息冗余、效率低下等 。
現如今 , 大語言模型(LLM)就主要模仿這一套范式來學習和傳遞知識 。 然而 , 與人腦不可知和不透明的特性不同 , 開源 LLM 的可訪問參數和信息流則像一個透明的大腦 , 直接編碼了事實知識 , 已有的研究對其進行了系統分析、精確定位和有效轉移 。 因此研究人員提出疑問:大模型能否像《阿凡達》中的人類和納威人之間建立傳遞知識的練習?其中在天然存在的較大 LLM 和較小 LLM 對之間展開 , 將參數知識作為媒介 。
最近 , 中國科學院自動化所提出對 Parametric Knowledge Transfer (PKT , 參數知識遷移) 的全面分析 。 一句話總結:跨規模大模型之間的表現相似和參數結構相似度都極低 , 這對實現有效的 PKT 提出了極大的挑戰 。
- 論文標題:Neural Incompatibility: The Unbridgeable Gap of Cross-Scale Parametric Knowledge Transfer in Large Language Models
- 論文地址:https://arxiv.org/abs/2505.14436
- Github 地址:https://github.com/Trae1ounG/Neural_Incompatibility
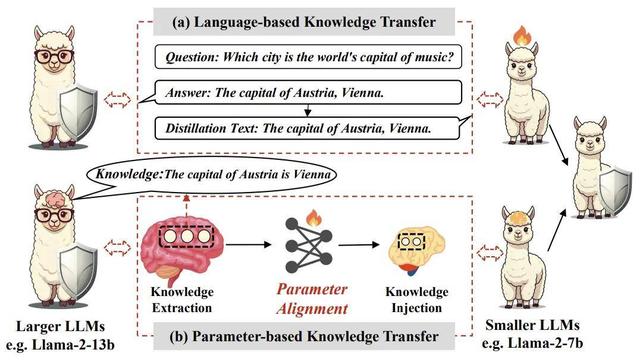
論文首先通過簡單的前置實驗 , 挖掘出參數空間的對齊是實現參數知識遷移的必要條件 。 現有的參數對齊方法 Seeking 通過梯度定位部分較大 LLM 參數以適配較小 LLM 張量形狀 , 將其初始化為 LoRA 矩陣通過后續微調實現遷移 , 稱之為后對齊參數遷移方法(Post-Align PKT) 。 論文為了更全面探索 PKT 是否可行 , 根據對齊時機提出先對齊知識遷移(Pre-Align PKT)新范式 , 采用定位后對齊(Locate-then-Align , LaTen)方法實現參數對齊 。
圖表 1:展示了基于語言的知識遷移和基于參數的知識遷移范式的差異
該方法的核心理念是首先通過神經元級別的歸因分析 , 識別出與特定任務相關的參數 , 然后利用訓練得當的超網絡 , 將較大 LLM 的知識映射到較小 LLM 上 。
具體而言 , LaTen 方法分為兩個階段:
- 知識提?。 和ü治齟竽P偷牟問?, 識別出與目標任務相關的知識 。 這一過程利用靜態神經元歸因方法 , 計算出每個神經元在任務中的重要性 , 從而選擇出最具信息量的參數進行遷移 。
- 參數對齊:一旦確定了重要參數 , 接下來通過輕量級的超網絡進行對齊 , 確保這些參數能夠有效整合到小型模型中 。
- 參數注入:這一過程強調在對齊后直接注入參數 , 減少了后續訓練所需的資源和時間 。
3 對齊實驗分析
在實驗部分 , 研究者針對多個基準數據集 , 涵蓋世界知識(MMLU) , 數學推理(GSM8K)和代碼能力(HumanEval 和 MBPP)進行了詳細評估 。
圖表 2:展示 Post-Align PKT 和 Pre-Align PKT 在不同數據集上的性能表現
實驗結論:
- 對于 Post-Align PKT , 論文將其同利用 SVD 從模型自身獲取 LoRA 的 PiSSA 方法對比 , 結果發現 PiSSA 在相同設置下優于 Seeking , 證明從較大模型抽取的參數知識不如利用模型自身知識作為 LoRA 初始化 , 進一步懷疑其可行性 。
- 對于 Pre-Align PKT , 結果顯示 , 只需要極少的訓練步數和數據開銷 , LaTen 能有效取得性能提升 。 但是 Pre-Align PKT 通過訓練實現參數對齊的方式受到極大限制 , 無法超越較大 LLM 的能力上界 , 同時訓練不太穩定 , 沒有明顯收斂 。
圖表 3:基于更強的較大 LLM 向較小 LLM 傳遞知識 , 左圖為 Post-Aligh PKT 實驗結果 , 右圖為 Pre-Align PKT 實驗結果
實驗結果證明了兩種 PKT 在這種設置下的失敗 , 讓人疑惑為什么跨規模 PKT 無法有效實現?
4 為什么跨規模 PKT 失敗?
PKT 的核心任務在于對齊(Align) , 不管是通過后續訓練還是提前通過超網絡實現 , 是否能有效實現對齊是 PKT 成功的關鍵 。 從現有實驗結果來看 , PKT 并沒有有效實現對齊 , 那么阻礙的關鍵在哪?
論文從表現相似度(representation similarity)和參數相似度(parametric similarity)出發 , 分析跨規模大模型在行為方式和內部參數結構的相似度是否會導致跨規模 PKT 的失敗 , 稱為神經不兼容性(Neuron Incompatibility) 。
圖表 4:跨規模大模型之間的表現相似度分析
對于表現相似度的分析 , 論文采用了中心核對齊(Centered Kernel Alignment CKA)方法 , 該方法基于 Hilbert-Schmidt 獨立性準則(HSIC) , 用于計算神經網絡中特征表示的相似性 。 該指標評估了兩個模型之間行為的相似性 , 可以視為大語言模型的行為相似性 。
如圖 4 所示 , Llama2-7B 和 13B 之間的相似性較低 , 尤其是在多頭自注意力(MHSA)模塊中 , 該模塊在信息整合中扮演著至關重要的角色 。 有趣的是 , 上投影層的相似性較高 , 這可能是因為它們作為關鍵記憶 , 捕捉特定的輸入模式 , 而這些模式通常在不同模型間是一致的 。 跨規模大模型之間的低相似性也解釋了為何從同一模型衍生的 LoRA 表現更好 , 因為它與模型的內在行為更為貼合 。 證明跨規模大語言模型之間的表示相似性較弱是導致神經不兼容性的關鍵因素之一 , 這使得理想的參數知識轉移成功變得困難 。
5 總結與展望:理想的 PKT 尚待實現
人類從牙牙學語到學貫古今 , 通過語言和文字在歷史長河中不斷汲取知識 , 通過吸收和迭代實現知識的傳承 。
然而 , 我常幻想能實現 , 類似科幻小說中三體人直接通過腦電波傳遞所有知識 , 或利用一張鏈接床就能把人類的意識輸入到納威人體內 , 這是一種更理想的知識傳遞方式 , 而開放的大模型參數正有可能實現這一點 。
通過將 PKT 根據 Align 進行劃分 , 我們完成了對現有階段 PKT 的全面研究 , 找出了實驗結果欠佳的背后是不同規模大模型之間參數知識本質上的行為和結構的差異 。
但仍期望 , 在未來大模型之間的交流不再局限于語言這種有損的壓縮方式 , 而去嘗試更高效直接的遷移方法 。
語言 , 或許是人類知識的起點 , 但不一定是大模型的終點 。
推薦閱讀












- 最新發現!每參數3.6比特,語言模型最多能記住這么多
- 實測 8 種編程語言內存消耗:選對語言能省一半服務器成本!
- 小米汽車從傳統車廠挖來的高管文飛離職,出任奇瑞汽車副總裁
- 拋開傳統固化思維,索尼、佳能、尼康三家微單相機優劣之分與選擇
- C++創始人:需要改變的不是語言,而是開發者的思維方式!
- 中國造出無CPU計算機
- Meta、Cisco 將開源大語言模型置于下一代 SOC 工作流核心
- REDMITurbo4Pro:徹底顛覆了人們對千元機的傳統認知!
- 海豚語言被谷歌模型破譯!實現跨物種交流,哈薩比斯:下一個是狗
- 雷軍宣布小米SU7產能翻倍!傳統車企高管集體沉默,網友:狼來了