【楊立昆親自發布:Meta最強世界模型開源】
文章圖片

文章圖片
文章圖片

文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

智東西
編譯 | 云鵬
編輯 | 漠影
智東西6月12日消息 , 剛剛 , Meta發布了最新的開源世界模型V-JEPA 2 , 稱其在物理世界中實現了最先進的視覺理解和預測 , 從而提高了AI agents的物理推理能力 。
Meta副總裁、首席AI科學家楊立昆(Yann LeCun)在官方視頻中提到 , 在世界模型的幫助下 , AI不再需要數百萬次的訓練才能掌握一項新的能力 , 世界模型直接告訴了AI世界是怎樣運行的 , 這可以極大提升效率 。
比如AI會預測我們舀出一勺東西是要放入另一個容器中:
AI甚至可以理解運動員的復雜跳水動作 , 并進行動作拆解:
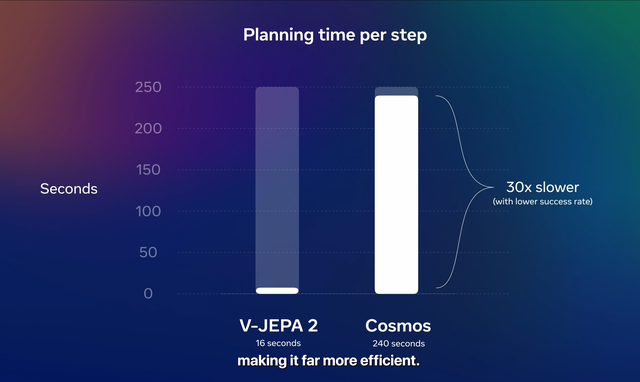
據Meta測試數據 , V-JEPA 2在測試任務中每一步的規劃用時縮短至英偉達Cosmos模型的三十分之一 , 同時成功率還更高 。 據稱V-JEPA 2使用了一百多萬小時的視頻來進行自監督學習訓練 。
在Meta看來 , 物理推理能力對于構建在現實世界中運作的AI agents、實現高級機器智能(AMI)非常重要 , 可以讓AI agents真正可以“三思而后行(Think Before Acts)” 。
此外 , Meta還發布了三個新的基準測試 , 用于評估現有模型從視頻中推理物理世界的能力 。
昨天Meta剛剛曝出要成立新AI實驗室、招攬28歲華裔天才少年 , 并豪擲148億美元(約合人民幣1061億元)收購Scale AI 49%股份的消息 , 今天Meta發布新世界模型 , 并讓楊立昆出來大講Meta AI重點研究方向和愿景做法 , 頗有些要為招兵買馬“打廣告”的意味 。
論文地址: https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
一、世界模型讓AI有“類人直覺” , 強化AI agents理解、預測、規劃能力理解世界物理規律聽起來并不復雜 , 但這是AI與人類差距非常大的一個方面 。
比如你把球拋向空中時 , 知道重力會將其拉回地面;當你穿過一個陌生的擁擠區域時 , 你會一邊朝目的地移動 , 一邊避免撞到沿途的行人或障礙物;打曲棍球時 , 你會滑向冰球即將到達的位置 , 而非它當前的位置 。
判斷籃球的運動軌跡
但AI很難掌握這種能力 , 很難構建這種理解物理世界的“心理模型” 。
Meta的世界模型 , 主要會強化AI agents的理解、預測、規劃三項核心能力 。
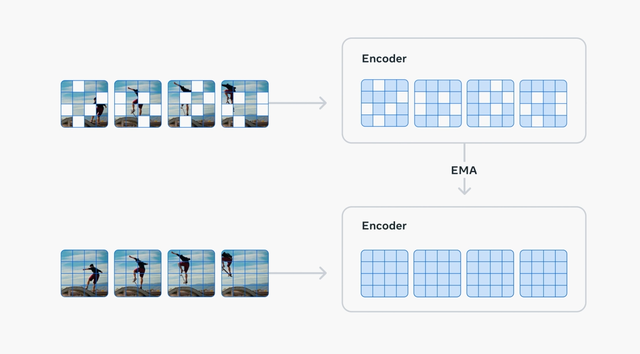
二、關鍵架構創新大幅提升學習效率 , 高性能同時兼顧準確率Meta使用視頻來訓練 V-JEPA 2 , 幫助模型學習物理世界中的重要規律 , 包括人類如何與物體互動、物體在物理世界中的運動方式 , 以及物體之間的相互作用 。
據稱V-JEPA 2通過自監督學習 , 訓練了超過1百萬小時的視頻 。
V-JEPA 2是一種聯合嵌入預測架構(Joint Embedding Predictive Architecture)模型 , 這也是“JEPA”的名稱由來 。
模型包括兩個主要組成部分:
一個編碼器 , 負責接收原始視頻 , 并輸出包含對于觀察世界狀態語義上有用的內容的嵌入(embeddings) 。
一個預測器 , 負責接收視頻嵌入和關于要預測的額外內容 , 并輸出預測的嵌入 。
V-JEPA 2跟傳統預測像素的生成式模型有很大性能差異 , 根據Meta測試數據 , V-JEPA 2執行任務時每個步驟的規劃用時縮短至Cosmos模型的三十分之一 , 不僅用時短 , V-JEPA 2的成功率還更高 。
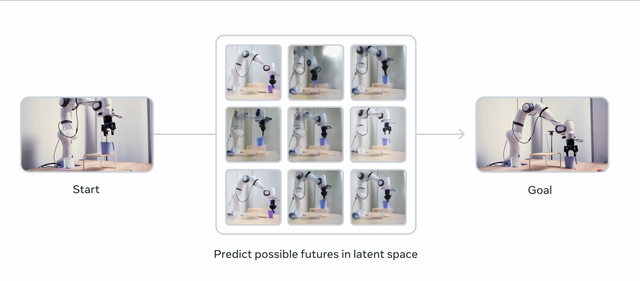
V-JEPA 2的能力對現實世界agents理解復雜運動和時間動態(temporal dynamics) , 以及根據上下文線索預測動作都非常關鍵 。
基于這種預測能力 , 世界模型對于規劃給定目標的動作順序非常有用 , 比如從一個杯子在桌子上的狀態到杯子在桌子邊上的狀態 , 中間要經歷怎樣的動作 。
如今大部分AI都需要專業的訓練去解決特定的任務 , 而V-JEPA這種自監督的方式 , 只需要為數不多的案例 , 就可以掌握新的能力 , 在不同的任務和領域中實現更高的性能表現 。
模型可以部署在機械臂上 , 去執行物體操作類的任務 , 比如觸碰(Reach)、抓?。 ℅rasp)、選擇和擺放物體(Pick-and-place) , 而不需要大量的機器人數據或者針對性的任務訓練 。
根據測試數據 , V-JEPA 2在執行這三類任務時的成功率分為別100%、45%和73% 。
三、楊立昆展示世界模型應用場景 , 首發三個專項基準測試世界模型可能會有哪些應用場景 , 楊立昆也給大家做了一些展示 。
世界模型加持下的AI agents , 可以幫助視障人群更好的認知世界;
MR頭顯中的AI agents可以給更復雜的任務提供指導 , 比如讓教育更加的個性化;
AI編程助手可以真正理解一行新的代碼會如何改變程序的狀態或變量;
世界模型對自動化系統同樣非常重要 , 比如自動駕駛汽車和機器人;
Meta認為世界模型會為機器人開啟一個新的時代 , 讓現實世界中的AI agents不需要學習天文數字的訓練數據就可以做家務或體力勞動 。
除了發布V-JEPA 2 , Meta還分享了三個新基準測試 , 用來幫助研究界評估現有模型通過視頻學習和推理世界的能力:
1、IntPhys 2:用于測試模型在復雜合成環境中的直觀物理理解能力(Benchmarking Intuitive Physics Understanding In Complex Synthetic Environments) 。
2、一種基于最小視頻對的、感知捷徑的物理理解視頻問答基準測試(A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs) 。
3、CausalVQA:面向視頻模型的物理基礎因果推理基準測試(A Physically Grounded Causal Reasoning Benchmark for Video Models) 。
基準測試地址:
IntPhys 2: https://ai.meta.com/research/publications/intphys-2-benchmarking-intuitive-physics-understanding-in-complex-synthetic-environments/
CausalVQA : https://ai.meta.com/research/publications/causalvqa-a-physically-grounded-causal-reasoning-benchmark-for-video-models/
Shortcut-aware Video-QA Benchmark: https://ai.meta.com/research/publications/a-shortcut-aware-video-qa-benchmark-for-physical-understanding-via-minimal-video-pairs/
結語:AI認知世界提速 , AI從數字世界加速走向物理世界Meta二代世界模型的發布進一步優化了模型的性能和準確率 , 讓物理世界的AI agents可以更高效地執行任務 , 而不需要海量的數據訓練 , 這一方向可以說是目前AI圈關注的焦點賽道之一 。
隨著數據瓶頸問題越來越凸顯 , 如何在底層技術層面實現突破顯得更為關鍵 , Meta在模型架構層面的創新是其世界模型的核心優勢 。
隨著如今越來越多的視頻模型發布 , AI逐漸從文本、圖像走向動態的視頻 , AI理解世界、認識世界的速度不斷加快 , 從英偉達、Meta、谷歌這樣巨頭到各路創企 , 都對打造世界模型饒有興致 , 世界模型之戰 , 或許將成為后續AI產業技術競爭的關鍵看點 。
來源:Meta官網
推薦閱讀















- AMD MI350 AI加速器本周發布:推理能力提升35倍,直指NVIDIA
- 小米新機入網:6月份,正式發布
- 華為Pure 80系列發布,Pro版本6499元起售,產品配置、價格匯總
- 首款OLED電競小平板發布,12GB+256GB賣3499元,可以嗎?
- 華為FreeBuds 6悅彰耳機玫瑰金新色發布,時尚與實用價值兼備的隨身單品
- 華為新品震撼發布 鴻蒙5全面覆蓋手機、平板、電腦、穿戴等全場景
- AirPods 迎來史詩級更新!新款終于即將發布
- OpenAI發布新推理模型o3-pro,并下調o3價格
- 6月首批新機官宣:6月11日/12日,正式發布
- 華為新品震撼發布 鴻蒙5全面覆蓋手機、平板、電腦、穿戴等全場景多終端