
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
蘋果一篇論文 , 再遭打臉 。 研究員聯手Claude Opus用一篇4頁論文再反擊 , 揭露實驗設計漏洞 , 甚至指出部分測試無解卻讓模型「背鍋」的華點 。
幾天前 , 蘋果怒斥大模型根本不會推理論文 , 引發全網無數討論與爭議 。
在許多人看來 , 沒有站在AI前沿的人 ,卻質疑當今最領先推理模型o3-mini、DeepSeek-R1推理能力 , 實在沒有說服力 。
論文一出 , 備受質疑 。
一位研究員發文稱 , 其研究方法并不可靠 , 比如通過在數學題中添加無關內容測試模型的表現 。
最近 , Open Philanthropy研究人員聯手Anthropic發表的一篇論文——The Illusion of the Illusion of Thinking , 再次將矛頭指向蘋果 。
論文地址:https://arxiv.org/pdf/2506.09250
這篇僅4頁論文一針見血 , 揭露了蘋果論文在漢諾塔實驗、自動評估框架 , 以及「過河」基準測試中的三大缺陷 。
甚至 , 文中還指出部分測試用例在數學上無解 , 模型卻因此被誤判為「推理失敗」 。
更引人注目的是 , 論文作者之一 , 還有一個是AI——Claude Opus 。
論文中 , 具體指出了哪些問題 , 讓我們一探究竟 。
推理大模型失敗 , 是非戰之罪在The illusion of thinking中 , 作者給出了四個例子 , 說明當問題的尺度變大時 , 大模型的表現變得越來越差 。
他們據此得出結論:大模型實際上只是在進行著模式匹配 , 從訓練數據集中找出對該問題的已有解答 。
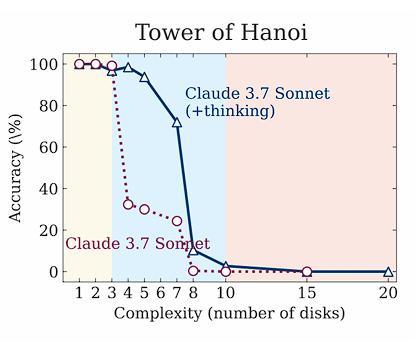
漢諾塔問題示例
然而Lawsen和Claude指出上述研究中 , 推理大模型失敗源頭在于token數超過了模型的上限 。
例如 , 在漢諾塔的任務中 , 模型必須打印指數級數量的步驟——僅15個盤子就需要超過32000次移動 , 這導致它們達到輸出上限 。
Sonnet 3.7的輸出限制是128k , DeepSeek R1是64K , 以及o3-mini是100k token 。
這包括他們在輸出最終答案之前使用的推理token , 所有模型在超過13個盤子的情況下都會出現0準確率 , 僅僅因為它們無法輸出那么多!
不同大模型能夠應對的漢諾塔盤子數 , 不考慮任何推理token , 大模型最大可解決規模為DeepSeek: 12個盤子 , Sonnet 3.7和o3-mini為13個盤子
在使用Claude測試時 , 作者觀察到當問題規模過大時 , 它們甚至不會進行推理 , 而是會說 , 「由于移動次數眾多 , 我將解釋解決方案方法」 , 而不是逐一列出所有32767次移動 。
針對非常小的問題(大約5-6個盤子)的 , 大模型會進行推理 。
之后 , 它只是:重復問題 , 重復算法 , 打印步驟 , 然后到了9-10個盤子時 , 這時模型遇到了其輸出的上限 , 這時 , 模型也許應該給出回復 , 「我寫不下2^n_圓盤-1步 , 這超過了我的輸出上限」 。
不同尺度的問題 , 大模型輸出的token數在9-10個盤子時達到峰值
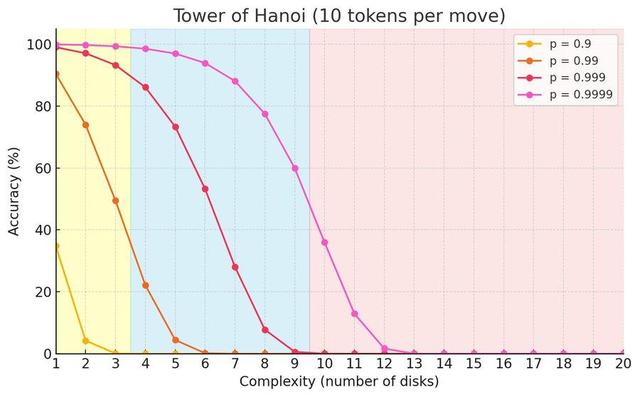
此外 , 大模型給出的解答之所以是錯誤的 , 可能的原因是在每一步推理過程中 , 大模型由于其是概念模型 , 會忘記之前選定的盤子 。
即使大模型每一步選對正確盤子的概率是99.99% , 當盤子數超過11%個時 , 大模型給出正確回答的概率 , 也會呈現指數衰減 。
這意味著即使大模型能夠進行推理 , 但由于其在推理過程中 , 某漢諾塔盤頂的盤子編號從A記錯成了B , 也會導致其給出的指令無法執行 。
而當前的評價要求大模型給出的回答完全沒有錯誤 , 這樣的評價標準 , 未免有些過于嚴苛了 。
大模型不同觀察準確性下 , 隨著問題復雜度增長其回答準確性的變化
至于The illusion of thinking文中列出的另一案例過河問題(River Crossing) , 當問題變為n=6時 , 問題在數學上就是無解的 , 這樣的不可解的問題數目并不少 。 將大模型面對這些不可解問題的失敗 , 當做大模型缺少推理能力的證據 , 這樣做無疑是不妥的 。
除了指出The illusion of thinking中的評價缺陷 , 最新論文也指出對大模型推理能力對正確評價方法 。
即不是讓大模型逐行編寫每個步驟時 , 而是其給出一個Lua程序去解答問題 , 然后運行大模型給出的程序 , 再判斷程序的輸出否是正確的解答 。
結果顯示 , Claude-3.7-Sonnet , Claude Opus 4 , OpenAIo3 , Google Gemini 2.5都能夠在5000個token的限制下 , 輸出能得到正確解答的程序 , 準確率極高 。
這完全消除了所謂的推理能力崩潰現象 , 表明模型并非未能進行推理 。 它們只是未能遵循一個人為的、過于嚴格的評分標準 。
LLM推理能力引熱議蘋果發布「思考的幻覺」論文的時間 , 恰逢WWDC之前 , 這進一步加劇了其影響力 , 使得其被廣泛討論 。
這其中就包含不少批評的聲音 , 比如有人暗示蘋果在大模型方面落后于OpenAI和谷歌等競爭對手 , 可能試圖降低人們的期望 。
他們戲稱 , 提出了一些關于「這一切都是假的 , 毫無意義」的研究 , 可以挽救蘋果在Siri等表現不佳的AI產品上的聲譽 。
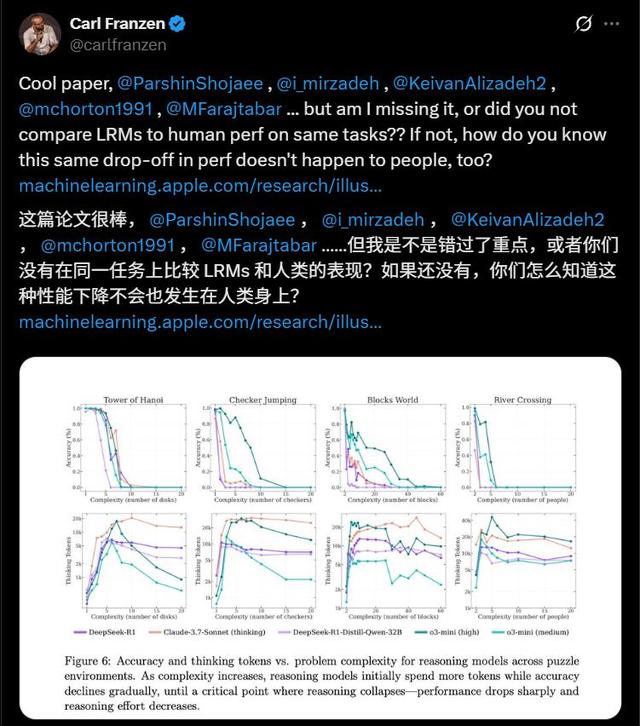
還有人批評道 , 即使是人類 , 也大多無法準確無誤的寫出針對13個盤子的漢諾塔問題的一步步解法 , 如果沒有進行這樣的比較 , 蘋果又如何知道這樣隨著問題規模變大而遇到的準確性下降 , 不會出現在人類身上 。
而法國高效能AI初創公司Pleias的工程師Alexander Doria指出思考的幻覺一文略了細微差別 , 認為模型可能在學習部分啟發式方法 , 而不是簡單地匹配模式 。
而賓夕法尼亞大學沃頓商學院專注于人工智能的教授Ethan Mollick認為 , 認為大語言模型正在「遇到瓶頸」的觀點為時過早 , 并將此比作那些未能應驗的關于「模型崩潰」的類似主張 。
上述爭議凸顯了一個日益增長的共識:設計合理的大模型評估方案 , 如今與模型設計同等重要 。
要求大模型枚舉每一步可能更多地考驗它們的輸出上限而非規劃能力 , 而輸出程序化答案或給予大模型外部臨時工作區則能更清晰地展現其實際推理能力 。
該案例還突出了開發者在部署自主系統時面臨的實際限制——上下文窗口、輸出預算和任務表述可能決定或破壞用戶可見的性能 。 對于在企業技術決策者構建基于推理大模型的應用而言 , 這場辯論不僅僅是學術性的 。 它提出了關于在生產工作流程中何時、何地以及如何信任這些模型的關鍵問題——尤其是在任務涉及長規劃鏈或需要精確的逐步輸出時 。
如果一個模型在處理復雜提示時看似「失敗」 , 問題可能不在于其推理能力 , 而在于任務如何被構建、需要多少輸出 , 或模型能訪問多少內存 。 這對于構建如協作者、自主代理或決策支持系統等工具的產業尤其相關 , 在這些產業中 , 可解釋性和任務復雜性都可能很高 。
理解上下文窗口、token預算以及評估中使用的評分標準對于可靠的系統設計至關重要 。 開發者可能需要考慮外部化內存、分塊推理步驟或使用函數或代碼等壓縮輸出 , 而不是完整的語言解釋 。
更重要的是 , 這篇論文的爭議提醒我們 , 基準測試與現實應用并不相同 。
企業團隊應謹慎避免過度依賴那些不能反映實際應用場景的合成基準測試——或者那些無意中限制模型展示其能力的基準測試 。 對機器學習研究人員來說 , 一個重要的啟示是:在宣稱一個人工智能里程碑或訃告之前 , 務必確保測試本身沒有將系統置于一個太小而無法思考的框框之中 。
參考資料https://arxiv.org/pdf/2506.09250
【Claude與人類共著論文,蘋果再遭打臉,實驗黑幕曝光】https://lawsen.substack.com/p/when-your-joke-paper-goes-viral
推薦閱讀













- 三星電子尋求與中國企業合作 降低OLED面板成本
- 消息稱亞馬遜云計算部門將與SK聯手 在蔚山打造韓國最大AI數據中心
- BOOST電路設計與工作原理講解
- 紅米K80至尊版突然官宣:與K Pad一起來襲,配置規格基本沒懸念
- REDMI K Pad圖賞:質感與便攜兼得,全金屬機身×窄邊設計
- 影像與性能的雙重巔峰:OPPOFindX8Ultra,帶來專業的拍攝體驗!
- 大唐電信小米將在德國“對簿公堂”,涉及3項4G與5G標準相關專利
- 配色與手感雙滿分,vivo S30 Pro mini帶來小屏魅力之美
- x86-64 CPU架構版本劃分與歷史演進全解析\uD83C\uDF1F
- 小米16 Pro與紅米K90 Pro:屏幕再次被敲定,配置規格也懸念不大了