
文章圖片

文章圖片
文章圖片
機器之心報道
編輯:楊文、澤南
昨天 , 月之暗面發了篇博客 , 介紹了一款名為 Kimi-Researcher 的自主 Agent 。
這款 Agent 擅長多輪搜索和推理 , 平均每項任務執行 23 個推理步驟 , 訪問超過 200 個網址 。 它是基于 Kimi k 系列模型的內部版本構建 , 并完全通過端到端智能體強化學習進行訓練 , 也是國內少有的基于自研模型打造的 Agent 。
GitHub 鏈接:https://moonshotai.github.io/Kimi-Researcher/
在「人類最后一場考試」(Humanity's Last Exam) 中 , Kimi-Researcher 取得了 26.9% 的 Pass@1 成績 , 創下最新的 SOTA 水平 , Pass@4 準確率也達到了 40.17% 。
從初始的 8.6% HLE 分數開始 , Kimi-Researcher 幾乎完全依靠端到端的強化學習訓練將成績提升至 26.9% , 強有力地證明了端到端智能體強化學習在提升 Agent 智能方面的巨大潛力 。
Kimi-Researcher 還在多個復雜且極具挑戰性的實際基準測試中表現出色 。 在 xbench (一款旨在將 AI 能力與實際生產力相結合的全新動態、專業對齊套件)上 , Kimi-Researcher 在 xbench-DeepSearch 子任務上平均 pass@1 達到了 69% 的分數(4 次運行的平均值) , 超越了諸如 o3 等帶有搜索工具的模型 。 在多輪搜索推理(如 FRAMES、Seal-0)和事實信息檢索(如 SimpleQA)等基準測試中 , Kimi-Researcher 同樣取得了優異成績 。
舉個例子 。 我們想找一部外國動畫電影 , 但只記得大概劇情:
我想找一部外國的動畫電影 , 講的是一位公主被許配給一個強大的巫師 。 我記得她被關在塔里 , 等著結婚的時機 。 有一次她偷偷溜進城里 , 看人們縫紉之類的事情 。 總之 , 有一天幾位王子從世界各地帶來珍貴禮物 , 她發現其中一位王子為了得到一顆寶珠作為禮物 , 曾與當地人激烈交戰 。 她指責他是小偷 , 因為他從他們那兒偷走了圣物 。
隨后 , 一個巫師說服國王相信她在撒謊 , 說她被某種邪靈附體 , 并承諾要為她“凈化” , 作為交換條件是娶她為妻 。 然后巫師用魔法讓她變成一個成年女子 , 并把她帶走 。 他把她關進地牢 , 但她有一枚可以許三個愿望的戒指 。
由于被施了魔法 , 讓她失去了逃跑的意志 , 她把前兩個愿望浪費在了一些愚蠢的東西上 , 比如一塊布或者一張床之類的……然后她好像逃出來了……并且耍了那個巫師一把……她后來還找到了一塊可以生出水的石頭……我記得還有人被變成青蛙……
整部電影發生在一個有點后末日設定的世界里 , 是一個古老魔法文明崩塌幾百年之后的背景 。 如果有人知道這是什么電影 , 請告訴我 。 我一直在找這部電影 , 已經找了好久了 。
[ 上下滑動查看更多
Kimi-Researcher 就會根據給定的模糊信息進行檢索 , 最終識別出該電影為《阿瑞特公主》 , 并一一找出該電影與劇情描述之間的對應關系 。
此外 , 它還能進行學術研究、法律與政策分析、臨床證據審查、企業財報分析等 。
Kimi–Researcher 現已開始逐步向用戶推出 , 可以在 Kimi 內實現對任意主題的深入、全面研究 。 月之暗面也計劃在接下來的幾個月內開源 Kimi–Researcher 所依賴的基礎預訓練模型及其強化學習模型 。
端到端的智能體強化學習
Kimi–Researcher 是一個自主的智能體與思維模型 , 旨在通過多步規劃、推理和工具使用來解決復雜問題 。 它利用了三個主要工具:一個并行的實時內部搜索工具;一個用于交互式網頁任務的基于文本的瀏覽器工具;以及一個用于自動執行代碼的編碼工具 。
傳統 agent 開發存在以下幾個關鍵限制:
- 基于工作流的系統:多智能體工作流將角色分配給特定智能體 , 并使用基于提示的工作流進行協調 。 雖然有效 , 但它們依賴于特定的語言模型版本 , 并且在模型或環境發生變化時需要頻繁手動更新 , 從而限制了系統的可擴展性和靈活性 。
- 帶監督微調的模仿學習(SFT):模仿學習能使模型很好地對齊人類演示 , 但在數據標注方面存在困難 , 尤其是在具有長時間跨度、動態環境中的智能體任務中 。 此外 , SFT 數據集通常與特定工具版本強耦合 , 導致隨著工具的演變 , 其泛化能力會下降 。
OpenAI 的 Deep Research 等先前研究也展示了這種方法的強大性能 , 但它也帶來了新的挑戰:
- 動態環境:即使面對相同的查詢 , 環境結果也可能隨時間發生變化 , 智能體必須具備適應不斷變化條件的能力 。 目標是實現對分布變化的魯棒泛化能力 。
- 長程任務:Kimi–Researcher 每條軌跡可執行超過 70 次搜索查詢 , 使用的上下文窗口長度甚至達數十萬 token 。 這對模型的記憶管理能力以及長上下文處理能力提出了極高要求 。
- 數據稀缺:高質量的用于智能體問答的強化學習數據集非常稀缺 。 該研究團隊通過自動合成訓練數據的方式解決這一問題 , 從而實現無需人工標注的大規模學習 。
- 執行效率:多輪推理和頻繁工具調用可能導致訓練效率低下 , GPU 資源利用不足 。 優化 rollout 效率是實現可擴展、實用的智能體強化學習訓練的關鍵 。
Kimi–Researcher 是通過端到端的強化學習進行訓練的 。 研究團隊在多個任務領域中觀察到了智能體性能的持續提升 。 圖 2-a 展示了 Kimi–Researcher 在強化學習過程中整體訓練準確率的變化趨勢;圖 2-b 則呈現了模型在若干內部數據集上的性能表現 。
訓練數據
為了解決高質量智能體數據集稀缺的問題 , 研究團隊在訓練語料的構建上采取了兩種互補的策略 。
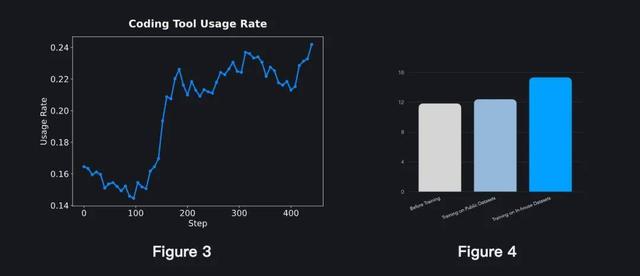
首先 , 他們設計了一套具有挑戰性的、以工具使用為核心的任務 , 旨在促進智能體對工具使用的深入學習 。 這些任務提示被刻意構造為必須調用特定工具才能解決 —— 從而使得簡單的策略要么根本無法完成任務 , 要么效率極低 。 通過將工具依賴性融入任務設計中 , 智能體不僅學會了何時調用工具 , 也學會了在復雜的現實環境中如何高效協同使用多種工具 。 (圖 3 展示了在這些訓練數據中 , 模型對工具的調用頻率 。 )
其次 , 他們策劃并整合了一批以推理為核心的任務 , 旨在強化智能體的核心認知能力 , 以及其將推理與工具使用結合的能力 。 該部分進一步細分為以下兩類:
- 數學與代碼推理:任務聚焦于邏輯推理、算法問題求解和序列計算 。 Kimi–Researcher 不僅依賴思維鏈進行解題 , 還能結合工具集解決這類復雜問題 。
- 高難度搜索:這類任務要求智能體在上下文限制下進行多輪搜索、信息整合與推理 , 最終得出有效答案 。 案例研究表明 , 這些高難搜索任務促使模型產生更深層的規劃能力 , 以及更健壯、工具增強的推理策略 。
此外 , 他們還設計了嚴格的過濾流程 , 以剔除歧義、不嚴謹或無效的問答對;其中引入的 Pass@N 檢查機制 , 可確保僅保留具有挑戰性的問題 。 圖 4 展示了基于兩項實驗結果的合成任務效果評估 。
強化學習訓練
該模型主要采用 REINFORCE 算法進行訓練 。 以下因素有助于提升訓練過程的穩定性:
- 基于當前策略的數據生成(On-policy Training):生成嚴格的 on-policy 數據至關重要 。 在訓練過程中 , 研究團隊禁用了 LLM 引擎中的工具調用格式強制機制 , 確保每條軌跡完全基于模型自身的概率分布生成 。
- 負樣本控制(Negative Sample Control):負樣本會導致 token 概率下降 , 從而在訓練中增加熵崩塌(entropy collapse)的風險 。 為應對這一問題 , 他們策略性地丟棄部分負樣本 , 使模型能夠在更長的訓練周期中持續提升表現 。
- 格式獎勵(Format Reward):如果軌跡中包含非法的工具調用 , 或上下文 / 迭代次數超出限制 , 模型將受到懲罰 。
- 正確性獎勵(Correctness Reward):對于格式合法的軌跡 , 獎勵依據模型輸出與標準答案(ground truth)之間的匹配程度進行評估 。
上下文管理
在長程研究任務中 , 智能體的觀察上下文可能會迅速膨脹 。 如果沒有有效的記憶管理機制 , 普通模型在不到 10 次迭代內就可能超過上下文限制 。 為了解決這一問題 , 研究團隊設計了一套上下文管理機制 , 使模型能夠保留關鍵信息 , 同時舍棄無用文檔 , 從而將單條軌跡的迭代次數擴展至 50 次以上 。
早期的消融實驗表明 , 引入上下文管理機制的模型迭代次數平均提升了 30% , 這使其能夠獲取更多信息 , 進而實現更優的任務表現 。
大規模智能體RL infra
為應對大規模智能體強化學習在效率與穩定性方面的挑戰 , 研究者構建了一套具備以下關鍵特性的基礎設施體系:
- 完全異步的 rollout 系統:實現了一個具備擴展性、類 Gym 接口的全異步 rollout 系統 。 基于服務端架構 , 該系統能夠高效并行協調智能體的軌跡生成、環境交互與獎勵計算 。 相較于同步系統 , 這一設計通過消除資源空轉時間顯著提升了運行效率 。
- 回合級局部回放(Turn-level Partial Rollout):在 Agent RL 訓練中 , 大多數任務可在早期階段完成 , 但仍有一小部分任務需要大量迭代 。 為解決這一長尾問題 , 研究者設計了回合級局部回放機制 。 具體來說 , 超出時間預算的任務將被保存至 replay buffer , 在后續迭代中以更新后的模型權重繼續執行剩余部分 。 配合優化算法 , 該機制可實現顯著的 rollout 加速(至少提升 1.5 倍) 。
- 強大的沙盒環境:研究者構建了統一的沙盒架構 , 在保持任務隔離性的同時 , 消除了容器間通信開銷 。 基于 Kubernetes 的混合云架構實現了零停機調度與動態資源分配 。 Agent 與工具之間通過 MCP(Model Context Protocol)進行通信 , 支持有狀態會話與斷線重連功能 。 該架構支持多副本部署 , 確保在生產環境中具備容錯能力與高可用性 。
在端到端強化學習過程中 , 研究者觀察到 Kimi–Researcher 出現了一些值得關注的能力涌現 。
- 面對多來源信息沖突時 , Kimi–Researcher 能通過迭代假設修正與自我糾錯機制來消除矛盾 , 逐步推導出一致且合理的結論 。
- 展現出謹慎與嚴謹的行為模式:即便面對看似簡單的問題 , Kimi–Researcher也會主動進行額外搜索 , 并交叉驗證信息后再作答 , 體現出高度可靠性與信息安全意識 。
推薦閱讀














- 「悄悄發育」的華為 AI,這次放了個「大招」
- 老羅數字人刷屏背后,AI導演正偷偷改寫直播「劇本」
- 支付寶突然整了個王炸級大招,「看一下支付」
- 蘋果官方大降價!額外還送 AirPods 4 降噪耳機「詳細版本」
- 7410mAh+100W快充+超324萬跑分,紅米兩臺新「性能猛獸」月底殺到
- 同一天開源新模型,一推理一編程,MiniMax和月之暗面開卷了
- 能「聽」見更能「聽」懂萬國語,Leion Hey2 什么水平?
- 「摸魚」被踢,GPT-4o真不行,30天籌款破萬,AI真人秀太上頭
- 挑戰一線品牌!七彩虹iGame M16 是否配得上「萬元旗艦守門員」?
- 月之暗面放王炸!開源Kimi新模型:超新版DeepSeek R1全球第一