文章圖片

文章圖片
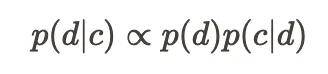
文章圖片
文章圖片

機器之心報道
編輯:冷貓
數月前 , 蘋果基礎模型團隊負責人、杰出工程師龐若鳴(Ruoming Pang)離職加入 Meta 。 扎克伯格豪擲兩億美元招攬龐若鳴加入超級智能團隊 。
根據龐若鳴的領英信息 , 他已在 Meta 工作了大約三個月的時間 。
但令我們出乎意料的是 , 這兩個多月來 , 龐若鳴在蘋果參與的工作還在不斷發表中 , 其中仍不乏一些高價值研究 。
在蘋果期間 , 龐若鳴領導著蘋果基礎模型團隊 , 主要負責開發 Apple Intelligence 及其他 AI 功能的核心基礎模型的工作 。 龐若鳴的工作在推動基礎大模型進步的領域中具有很高的影響力和研究價值 。
就比如我們即將介紹的這一個:
論文標題:Synthetic bootstrapped pretraining 論文鏈接:https://arxiv.org/html/2509.15248v1我們知道 , 大規模的語言模型是以海量的互聯網文本作為基礎進行訓練的 , 受到規模效應「Scaling Law」的影響 , 數據量越大 , 多樣性越強 , 模型的能力也會有相應的提升 。
但從互聯網上獲取的數據不可能無限制的增加 。 準確的說 , 我們已經達到了真實數據規模的瓶頸:高質量文本數據已經在迅速枯竭 。 我們已經觸及到了「規模壁壘」 , 因此在大模型訓練中亟需重新思考如何更高效地利用現有數據 。
在大模型訓練中 , 預訓練的成功主要依賴于文檔內部 token 之間豐富的因果關聯 。 然而 , 這并不是預訓練數據集中唯一存在的相關性來源 。 例如:
一個實現注意力機制的代碼文檔 , 往往源自 Transformer 論文的 arXiv 預印本; 《哈利?波特》的小說在結構上與其電影劇本存在相似性 。這些現象表明 , 除了文檔內部的強相關性之外 , 還存在一種較弱的跨文檔相關性 , 它來源于預訓練文檔的某種潛在聯合分布 。
【龐若鳴還有蘋果論文?改善預訓練高質量數據枯竭困境】根據以上發現 , 研究團隊提出了假設:
這種額外的信號在標準預訓練過程中被忽視 , 而它可以通過合成數據加以捕捉 。 這為提升模型性能提供了一條尚未被充分探索的路徑 。
為充分利用這一潛在機會 , 研究者們提出了 Synthetic Bootstrapped Pretraining (SBP) , 一種新的語言模型預訓練流程 , 分為三個步驟:
相似文檔對識別:SBP 首先在預訓練數據集中識別語義上相似的文檔對 d1 , d2 , 例如 Transformer 論文及其代碼實現 。條件建模:SBP 接著對 d2|d1 的條件概率進行建模 , 從而構建一個「數據合成器」 , 該模型能夠在給定種子文檔的情況下生成新的、相關文檔 。數據擴展:最后 , SBP 將訓練好的條件合成器應用于整個預訓練語料庫 , 從而生成一個大規模的新文本語料 。 該語料顯式編碼了原始預訓練中未被利用的跨文檔相關性 。通過直接從預訓練語料庫中訓練數據合成器 , SBP 避免了依賴外部教師語言模型來「拔高」性能的陷阱 , 從而保證了改進來源于對同一預訓練數據的更優利用 。
SBP 的三步流程:(1) 通過最近鄰搜索識別語義相似的文檔對 , (2) 訓練一個合成器模型來生成相關內容 , 以及 (3) 擴展合成以創建用于與原始數據聯合訓練的大型語料庫 。
核心問題
大規模語言模型正面臨所謂的 「規模壁壘」:可用于預訓練的高質量、獨特文本語料正在迅速枯竭 。 現有的標準預訓練方法主要依賴 下一詞預測 , 學習單個文檔內部的 token 級依賴關系 。 雖然這種方法在實踐中取得了顯著效果 , 但它基本忽視了一類潛在的、極其豐富的信號 —— 語料中不同文檔之間的關聯關系 。
例如 , 一篇研究論文及其對應的代碼庫 , 或者一部小說及其影視改編 , 本質上存在深層的概念聯系 , 盡管它們在形式和風格上迥異 。 現有的預訓練范式將它們視為完全無關的樣本 , 從而丟棄了這些跨文檔關系所蘊含的價值 。
合成自舉預訓練(Synthetic Bootstrapped Pretraining SBP) 正是為了解決這一問題 , 通過將文檔間的相關性轉化為新的訓練信號 。
SBP 通過三個順序執行的步驟 , 將跨文檔關系轉化為合成訓練數據:
步驟 1:最近鄰配對
首先 , 在原始預訓練語料中識別語義相似的文檔對 。 具體而言 , 每個文檔都通過一個較小的外部模型(Qwen3-Embedding-0.6B)編碼為 1024 維向量 。 隨后 , 系統使用 ScaNN 并結合 8-bit 量化 來進行近似最近鄰搜索 , 以保證計算效率 。
當文檔對的相似度分數高于 0.75 閾值時 , 認為其足夠相關并選入候選集合 。 為避免語料冗余 , 一個關鍵的過濾步驟是基于 「shingles」 (13-token 滑動窗口) 檢查重疊情況 , 移除近似重復的文檔對 , 從而確保配對結果具備真正的新穎性 , 而不是簡單的重復 。
步驟 2:合成器調優
基于已識別的文檔對 , SBP 訓練一個條件語言模型 , 以學習相似文檔之間的關系模式 。 值得注意的是 , 這一「合成器」與主語言模型使用相同的 Transformer 架構 , 并且從已有的預訓練檢查點初始化 , 從而繼承了基礎語言理解能力 。
合成器的目標是最大化如下條件概率: 。 其中 , d1 是種子文檔 , d2 是與之相關的文檔 。 這一訓練過程促使模型理解同一概念如何能夠在不同的文檔類型、寫作風格和語境中被表達出來 。
步驟 3:大規模數據合成
訓練完成的合成器會應用到整個原始語料庫 , 以生成一個龐大的新語料集 。 具體來說 , 對于原始語料庫中采樣得到的每一個種子文檔 d1 , 合成器都會通過溫度采樣(temperature = 1.0 top_p = 0.9)生成一個新的文檔 d2 。
在生成之后 , 系統會對合成結果進行過濾 , 去除存在過多內部重復的文檔 , 以確保合成語料的質量 。 最終 , 合成語料與原始數據集結合 , 用于主語言模型的聯合訓練 。 一個核心原則是:合成文檔在訓練過程中不會被重復使用 。
理論基礎
作者們從貝葉斯視角解釋了 SBP 的有效性 。 他們將文檔生成建模為對潛在概念的后驗分布進行采樣:
其中 , c 表示潛在概念 , d 表示文檔 。 合成器在隱式學習過程中會從種子文檔中推斷這些潛在概念 , 然后生成新的文檔 , 以不同的方式來表達同一概念 。
這種方式使得語言模型能夠在訓練中以多樣化的形式多次接觸相同的知識 , 從而獲得更強的泛化能力和表達能力 。
實驗結果
這項研究使用基于 Llama 3 架構的 3B 參數 Transformer 模型 , 并在包含 5.82 億文檔和 4820 億 token 的 DCLM 數據集的定制版本上進行訓練 , 在多個規模和評估指標上驗證了 SBP 。
測試損失曲線表明 , SBP(紅色)始終優于基線重復方法(黑色) , 并接近于擁有大量獨特數據的「Oracle」模型(灰色虛線)的性能 。
性能提升
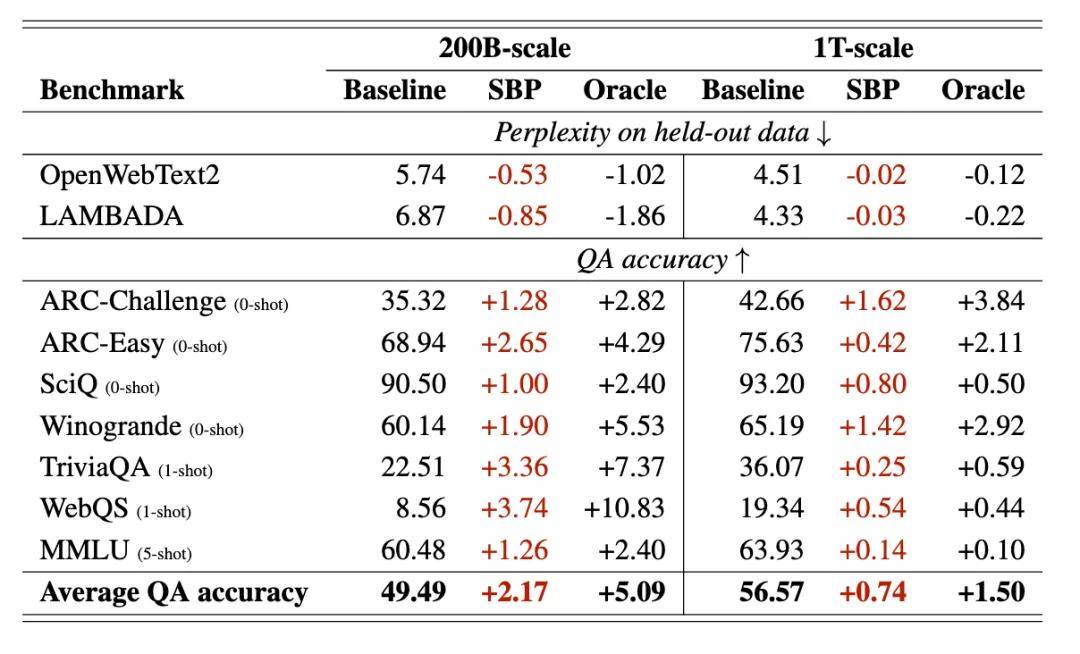
SBP 在 200B-token 和 1T-token 的訓練規模下 , 都比強大的基線模型表現出持續的改進 。
在 200B 規模下 , 該方法實現了擁有 20 倍以上獨特數據的「Oracle」模型所獲得性能增益的 42%;在 1T 規模下 , 則實現了 49% 。 這些結果表明 SBP 從固定數據集中提取了大量的額外信號 。
SBP 與 oracle 在重復基線上的性能增益對比 。 平均而言 , SBP 在問答準確率上的提升 , 大約相當于 oracle 在擁有 20 倍更多獨特數據時所能帶來的性能提升的 47% 。
訓練動態顯示 , 盡管 SBP 在初期可能略遜于基線 , 但隨著訓練的進行 , 其性能持續提升 , 而基線則趨于平穩 。 這表明合成數據提供了真正的新信息 , 而非簡單的重復 。
質量分析
對合成文檔的定性檢查表明 , SBP 超越了簡單的釋義 。 合成器從種子文檔中抽象出核心概念 , 并圍繞它們創建新的敘述 。 例如 , 一篇關于圣地亞哥咖啡館的種子文檔可能會生成關于濃縮咖啡機比較或咖啡文化散文的合成內容 , 在保持主題相關性的同時引入新的視角和信息 。
原始文本與合成文本變體的對比 。
定量分析證實 , 合成數據在多樣性和缺乏重復性方面保持了與真實數據相當的質量 , 而在更大的訓練規模下 , 事實準確性顯著提高 。
在 200B 規模和 1T 規模下從合成器采樣文檔的定量評估 。
意義與影響
SBP 通過將重點從獲取更多數據轉向從現有數據中提取更多價值 , 解決了大型語言模型可持續發展中的一個根本性挑戰 。 該方法提供了幾個關鍵優勢:
數據效率:通過學習文檔間的相關性 , SBP 使模型能夠從固定語料庫中獲取更豐富的訓練信號 , 從而可能延長現有數據集的有效壽命 。 自我改進:與依賴外部教師模型或人工標注的方法不同 , SBP 通過使用相同的架構和數據進行自我引導來實現性能提升 , 使其具有廣泛的適用性 。 理論基?。 罕匆端菇饈吞峁┝碩愿梅椒ㄎ斡行У腦硇岳斫?, 表明它實現了超越表面級 token 模式的概念級學習形式 。 互補效益:實驗表明 , SBP 的改進與模型規模擴展帶來的改進是正交的 , 這表明它可以整合到現有的擴展策略中以獲得額外的性能提升 。這項工作為數據高效訓練開辟了新的研究方向 , 并表明通過更復雜的利用策略 , 現有數據集仍可實現顯著改進 。 隨著該領域接近根本性數據限制 , SBP 等方法可能對語言模型能力的持續進步變得至關重要 。
更多信息 , 請參閱原論文 。
推薦閱讀















- 風口上的機器人,其實離“上班”還有點遠
- 雷軍重磅宣布!除了小米17系列登場,還有2025年度演講!
- 想買iPhone 17 Air?除了貴,還有這5大缺點,看完再買!
- 張一鳴黃仁勛,想到一塊兒了
- 劉強東“請客”菜單:一共15道菜,現場做“黃狗豬頭肉”,還有品鑒茅臺
- 60-180mm f/2.8、28-135mm f/2.8,森養還有大招在后
- 明日見!魅族22搭載Flyme AIOS 2,還有全新AI按鍵
- 想買iPhone Air?除了貴,還有這6大缺點,你能忍么?
- OPPO聯合哈蘇定制影像套裝,還有標準版的影像配件
- 主打的就是聽勸!紅米Turbo 5 Pro沖擊9K超大電池,還有超聲波指紋