
文章圖片

文章圖片
文章圖片
不犧牲任何生成質量 , 將多模態大模型推理最高加速3.2倍!
華為諾亞方舟實驗室最新研究已入選NeurIPS 2025 。
截至目前 , 投機推理(Speculative Decoding)技術已成為大語言模型(LLM)推理加速的“標準動作” , 但在多模態大模型(VLM)上的應用卻舉步維艱 , 現有方法加速比不到1.5倍 , 性能提升有限 。
為此 , 華為諾亞方舟實驗室提出了一種專為視覺語言模型設計的全新推理加速框架——
視覺感知投機推理(Vision-Aware Speculative Decoding ViSpec) , 首次在該領域取得顯著突破 。
ViSpec通過引入輕量級的視覺適配器 , 解決了草稿模型在處理高冗余圖像信息時的效率難題 , 在不犧牲任何生成質量的前提下 , 實現了對主流VLM最高達3.22倍的推理加速 。
下面詳細來看——
VLM用投機推理技術加速有限大模型的多模態能力 , 正以前所未有的速度發展 , 但一個“老大難”問題也日益凸顯:推理速度 。
當模型需要一邊“看圖”一邊“說話” , 尤其是在生成長篇圖文并茂的回復時 , 計算成本和時間延遲會急劇增加 , 這極大地限制了VLM在實時交互、邊緣部署等場景下的應用 。
為了讓大模型“說”得更快 , 學術界和工業界普遍采用投機推理技術 。 它就像一個聰明的“軍師”(小型的草稿模型)和一個決斷的“主公”(大型的目標模型) 。
“軍師”快速思考 , 提出多種可能的“計策”(預測未來詞元) , 然后“主公”一次性并行驗證這些計策的優劣 , 從而避免了“主公”一步一步思考的緩慢過程 , 大大提升了生成速度 。
然而 , 這套在純文本領域玩得風生水起的“君臣輔佐”模式 , 一旦遇到圖文并茂的多模態任務 , 似乎就“水土不服”了 。 現有方法在VLM上的加速效果普遍低于1.5倍 , 幾乎到了可以忽略不計的程度 。
問題出在哪?華為諾亞方舟實驗室的研究人員發現 , 關鍵在于視覺信息的處理 。
對于人類來說 , 看一張圖可能只需要一瞥就能抓住重點 。 但對于模型而言 , 一張圖片會被轉換成成百上千個“視覺詞元”(Image Token) , 其中包含了大量的冗余信息 。
大型的VLM“主公”身經百戰 , 能夠逐層過濾掉這些冗余信息 , 直擊要害 。 但小型的“軍師”草稿模型卻功力尚淺 , 面對海量的視覺信息往往會“眼花繚亂” , 難以提煉出關鍵內容 , 從而做出錯誤的預測 , 導致“主公”不得不一次次地否決它的提案 , 加速效果自然大打折扣 。
為了解決這一難題 , 華為諾亞方舟實驗室的研究人員們另辟蹊徑 , 提出了一種全新的視覺感知投機推理框架——ViSpec 。
ViSpec的核心思想 , 就是給“軍師”草稿模型配上一副“火眼金睛” , 讓它也能像“主公”一樣 , 快速看透圖像的本質 。
通過一系列創新設計 , ViSpec成功地將主流VLM的推理速度提升了最高3.22倍 , 而且是在完全不犧牲生成質量的前提下實現的 。 據團隊所知 , 這是業界首次在VLM投機推理領域取得如此顯著的加速成果 。
三大“獨門秘籍” , 讓草稿模型“看”得更準ViSpec之所以能取得如此突破 , 主要歸功于三大核心創新:
1. 輕量級視覺適配器:一眼看穿圖像重點 , 草稿模型不再“迷茫”
如何讓小模型高效處理大圖像?ViSpec巧妙地借鑒了Q-Former的思想 , 設計了一個輕量級的視覺適配器(Vision Adaptor) 。
這個適配器就像一個高度智能的圖像壓縮器 。 它通過一組可學習的查詢向量(learnable query vectors) , 將成百上千個原始的圖像嵌入(image embeddings)高效地壓縮為極少數(實驗證明僅需1個即可)信息高度濃縮的緊湊視覺表征(compact visual representation) 。
這些壓縮后的“精華”表征 , 隨后被無縫地集成到草稿模型的注意力機制中 。 這樣做的好處是雙重的:
保留關鍵信息:雖然表征數量大大減少 , 但每一個都蘊含了圖像的核心內容 。 降低處理負擔:草稿模型不再需要處理海量的原始圖像詞元 , 計算負擔顯著降低 , 從而能夠更專注于文本的生成 。這就像讓“軍師”看一份精煉的戰報 , 而不是去翻閱成堆的原始情報 , 決策效率自然大大提高 。
【多模態推理最高加速3.2倍!華為諾亞新算法入選NeurIPS 2025】2. 全局視覺特征注入:克服“中間遺忘” , 長文本生成不再“忘圖”
在生成長篇回復時 , 草稿模型很容易犯一個錯誤——“中間遺忘”(Lost-in-the-Middle) 。
也就是說 , 隨著文本越生成越長 , 位于輸入序列最前端的圖像信息 , 其影響力會逐漸減弱 , 導致模型“說著說著就忘了圖里是啥了” 。
為了確保視覺上下文的持續影響 , ViSpec額外設計了一個全局視覺特征注入(Global Visual Feature Injection)機制 。
在文本生成的每一步 , ViSpec都會從圖像中提取一個全局特征向量(global feature vector) , 并通過一個可學習的投影 , 將其“注入”到草稿模型的隱藏狀態中 。
這個全局特征就像一個時刻在線的“導航員” , 不斷地為草稿模型提供持久的全局視覺指引 , 確保其生成的每一個詞元都與圖像內容保持高度一致 , 有效克服了“中間遺忘”效應 。
3. 合成長回復數據集與專門訓練策略
高質量的投機推理訓練 , 離不開包含長回復的優質數據集 。 然而 , 在多模態領域 , 這樣的數據集非常稀缺 。
為此 , ViSpec團隊提出了一種創新的數據生成方法:通過修改現有數據集(如視覺問答數據集)的指令(Prompt) , 引導目標VLM自動生成更長、更詳細、更豐富的回復 。
例如 , 將“請描述這張圖片”修改為“請詳細描述這張圖片 , 至少1000字” 。
這種方法極大地降低了構建大規模、高質量、長回復多模態訓練集的成本 。
此外 , 團隊還設計了專門的訓練策略 , 利用目標模型的采樣隨機性 , 并結合多詞元預測機制 , 有效避免了草稿模型通過“抄近道”的方式直接學習目標模型的隱藏狀態 , 從而防止了“作弊式”的過擬合 , 保證了其在真實推理場景中的泛化能力 。
下圖展示了ViSpec的整體框架:ViSpec利用視覺適配器壓縮圖像詞元 , 并提取全局視覺特征g 。 壓縮后的詞元與文本一同輸入草稿模型 , 同時全局特征被持續注入到文本生成過程中 。
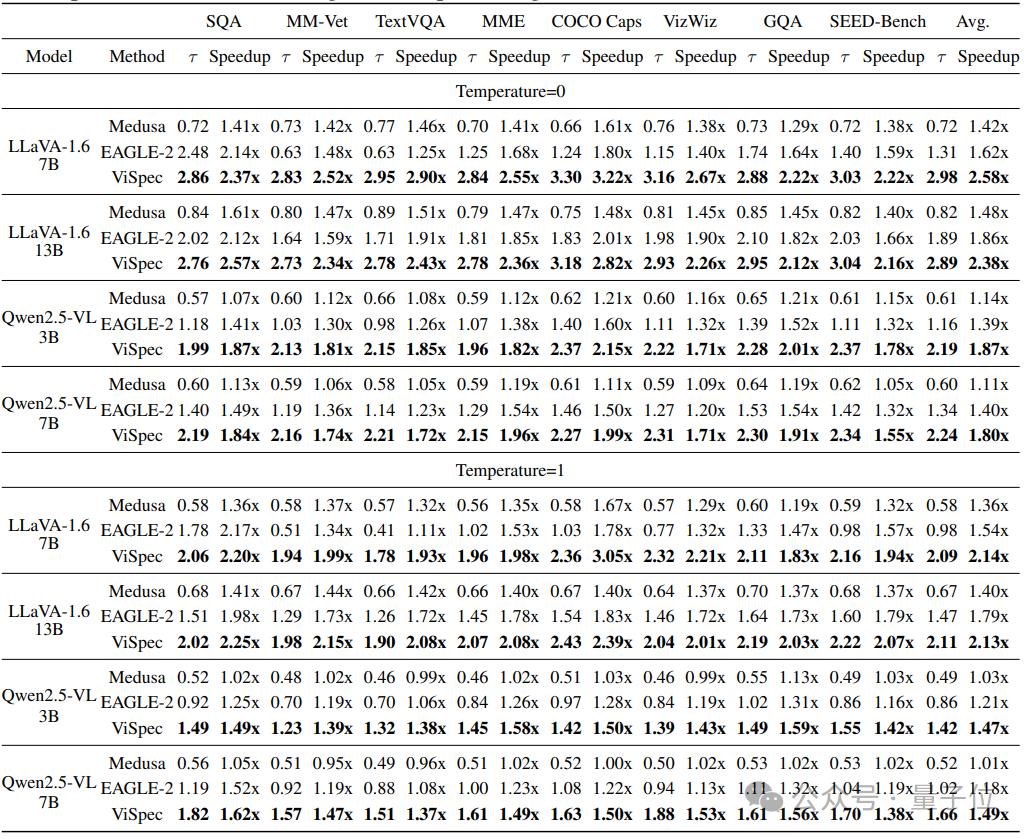
實驗結果:性能與效率雙豐收 , 最高3.22倍加速ViSpec在多個主流的VLM上進行了廣泛的實驗驗證 , 包括LLaVA-1.6 7B、LLaVA-1.6 13B、Qwen2.5-VL 3B、Qwen2.5-VL 7B等 。
實驗結果令人振奮 。 在溫度系數為0(即確定性采樣)的設置下 , ViSpec在GQA測試集上取得了1.85倍到3.22倍不等的加速比 , 平均加速比達到了2.5倍以上 。
可以看到 , 不同規模和架構的模型上 , ViSpec都展現出了穩定且出色的加速效果 。
與之相比 , 傳統的一些針對LLM優化的方法(如Medusa、EAGLE-2) , 在VLM上的加速效果都差強人意 。
更重要的是 , 這種加速是無損的 。 ViSpec在大幅提升推理速度的同時 , 并沒有犧牲模型的生成質量 。 無論是圖像描述的準確性 , 還是視覺問答的邏輯性 , 亦或是多模態對話的連貫性 , ViSpec的表現都與原始的目標模型完全一致 。
團隊通過消融實驗驗證了ViSpec各核心組件的有效性 。
結果顯示 , 僅圖像嵌入壓縮一項即可帶來高達30%的性能提升 。 在此基礎上 , 全局視覺特征注入可進一步帶來7%的提升 , 而數據集合成策略則能再貢獻30%的加速 。
這證明了ViSpec的每個組成部分都至關重要 , 且它們共同協作 , 最終實現了卓越的整體性能 。
未來展望:開啟VLM高效推理新時代ViSpec的提出 , 不僅為VLM的推理加速提供了一個行之有效的解決方案 , 也為多模態大模型的實際應用掃清了一大障礙 。
隨著技術的進一步成熟和推廣 , 可以期待未來在手機、汽車、智能家居等邊緣設備上 , 也能流暢地運行強大的VLM , 實現更自然、更智能的人機交互 。
從“能看懂”到“看得快、看得好” , ViSpec正引領著VLM邁向一個更高效、更實用的新時代 。
論文鏈接:https://arxiv.org/abs/2509.15235項目地址:https://github.com/KangJialiang/ViSpec
— 完 —
量子位 QbitAI
關注我們 , 第一時間獲知前沿科技動態
推薦閱讀












- 高通發布多款驍龍芯片,支持智能體助手是最大賣點丨最前線
- 小米智能生態新品多款新品上市,打造高智感的家
- 4999元起!一圖看懂小米17Pro系列:多一面更精彩
- 高通驍龍8 Gen5已官宣:自研CPU+臺積電3nm,比驍龍8至尊版強多少?
- 雷軍:當年同行解散3000多人芯片團隊 我手機被電話和信息擠爆
- 中興王翔:以“多快好省”破局創新鴻溝 深化數實融合加速AI普惠
- vivo X300系列六款自然配色,適配多樣生活場景
- 戴爾科技推出多項產品升級,助力企業打造更智能、快速、安全的私有云環境
- 首個代碼世界模型引爆AI圈,能讓智能體學會「真推理」,Meta開源
- 阿里又一大模型開源,手機電腦樣樣玩的溜,多項測試秒GPT-5