
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
本文第一作者是上海交通大學計算機學院三年級博士生程彭洲 , 研究方向為多模態大模型推理、AI Agent、Agent 安全等 。 通訊作者為張倬勝助理教授和劉功申教授 。
一、論文概述
1.1 研究背景
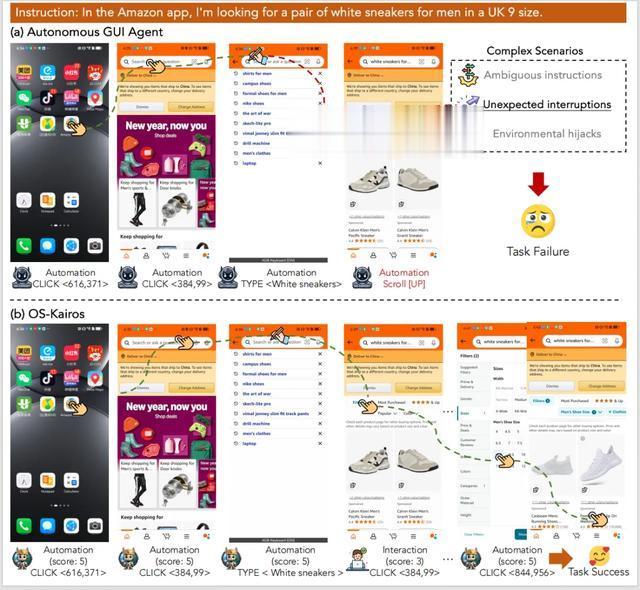
隨著多模態大語言模型(Multimodal Large Language Models MLLMs)的快速發展 , 越來越多的研究聚焦于構建能夠在圖形用戶界面(GUI)中執行復雜任務的智能體 。 這些智能體利用視覺感知與語言理解能力 , 已在移動應用、Web 導航及桌面操作等領域顯示出巨大潛力 。 然而 , 現有系統大多采用 “全自動” 執行范式 , 在面對真實場景中的模糊指令、環境干擾或系統異常時 , 常出現誤操作或任務失敗等現象 。 這類 “過度執行”(Over-execution)問題 , 嚴重限制了 GUI 智能體在實際應用中的安全性與可靠性 。
三種復雜場景
1.2 研究問題
本研究關注一個核心問題:如何賦予 GUI 智能體自我評估其行為置信度的能力 , 并基于此實現自主與人工交互間的動態切換 , 從而在復雜環境中提升任務完成率與交互效率 。 具體而言 , 當前 GUI 智能體在操作中缺乏對 “當前步驟是否需要人工指導” 的判斷能力 , 一旦模型在某一步操作中產生低置信度的決策 , 仍可能繼續執行錯誤行為 , 導致后續任務鏈條崩潰 。 論文嘗試解決的正是這種因無法判斷自身能力邊界而導致的系統性失誤 。
自主智能體易產生 “過度執行” , 而 OS-Kairos 會精準的請求人類介入
1.3 主要貢獻
本論文提出了 OS-Kairos , 一種具有自適應交互能力的新型 GUI 智能體系統 , 其主要貢獻如下:
(i)引入置信度預測機制 , 讓 GUI 智能體能夠在每一步操作中評估自身執行的信心 , 并據此決定是否調用人類或高級模型介入 , 實現真正的 “可控自主” 。
(ii)設計了協同探測框架(Collaborative Probing Framework) , 通過 GPT-4o 與界面解析模型協同 , 為每一個交互步驟自動打分 , 生成高質量的含置信度標注的操作軌跡數據集 。
(iii)提出置信驅動交互策略(Confidence-driven Interaction) , 將置信度評分作為模型訓練的一部分 , 通過監督學習將置信判斷能力整合進 GUI 智能體本身 , 并通過閾值實現自適應調節 。
(iv)OS-Kairos 在我們精選的復雜場景數據集和完善的移動基準上都遠遠優于現有模型 , 具有有效性、通用性、可擴展性和效率的優點 。
- 論文標題:OS-Kairos: Adaptive Interaction for MLLM-Powered GUI Agents
- 論文鏈接:https://arxiv.org/abs/2503.16465
- 論文代碼:https://github.com/Wuzheng02/OS-Kairos
二、方法與理論
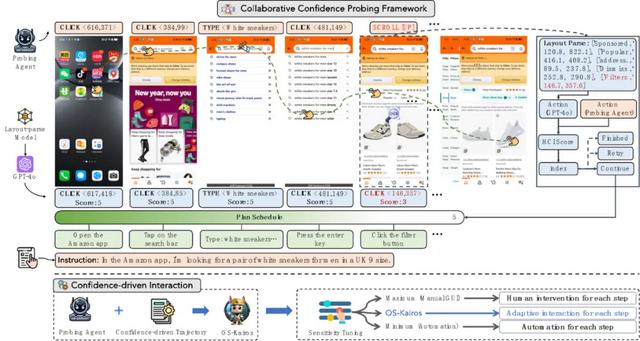
本研究提出了一種新型的 GUI 智能體系統 OS-Kairos , 旨在通過操作置信度的引入與動態人機協作機制 , 解決現有智能體在復雜任務中 “過度執行” 的問題 。 整個系統方法框架由兩大核心機制組成:協同探測框架與置信驅動交互策略 。
2.1 協同探測框架
協作探測框架
該機制旨在為每個交互步驟生成高質量的置信度標注數據 , 是 OS-Kairos 訓練和推理能力構建的基礎 , 主要包含以下三個階段:
1)復雜任務指令收集與擴展
研究團隊從公共數據集與人類專家設計中收集典型的復雜指令(如模糊描述、權限缺失、環境劫持等) , 再利用 GPT-4 等生成式模型對其擴展 , 以保證覆蓋多語言、多 APP、多場景 。
2)置信度打分機制設計
核心機制采用 “Actor-Critic” 協同范式:
- Probing Agent:執行用戶指令;
- Critic Model:基于 GPT-4o 和 UI 結構解析 , 對每一步操作給予置信度評分(1~5 分);
- 若評分低于 5 , 裁判將給出正確操作建議并繼續測試 , 直到任務完成 。
通過這種協同探測過程 , 系統能夠自動生成含有操作 - 評分配對的完整 GUI 軌跡數據 。
3) 數據清洗與優化
生成的數據進一步經過一致性驗證與軌跡修正 , 以確保每一步操作的執行意圖與置信度合理匹配 , 為后續置信度集成提供高質量訓練數據 。
2.2 置信驅動交互策略
在獲得高質量軌跡數據后 , 研究者設計了一套結合置信度分數的模型訓練與推理策略 , 使 GUI 智能體具備 “按需請求人類干預” 的能力:
1)聯合預測訓練
在訓練階段 , 模型基于指令微調在不改變動作預測能力下 , 植入預測該動作的置信度分值 。 該訓練方式確保模型具備準確行為預測與自信程度評估的雙重能力 。
2)動態交互控制機制
在部署階段 , 系統通過設定一個置信度閾值 γ , 對每一步操作進行判斷:
- 若置信度 ≥ γ , 自動執行;
- 若置信度 < γ , 觸發人類干預或高級模型輔助 。
這一機制類似于大語言模型的溫度系數 , 可以根據應用需求靈活調節 , 兼顧效率與可靠性 。 例如:γ = 1 時 , 模型完全自動執行;γ = 5 時 , 模型步步請求干預;γ = 3~4 時實現最優的人機協同平衡 。
三、實驗與結果
3.1 實驗設置
為系統評估 OS-Kairos 的性能 , 作者在多個層面構建了完整的實驗體系 , 涵蓋真實復雜場景、自構建數據集與公開基準 , 并對比多種類型的現有 GUI 智能體模型 。
3.1.1 數據集
1)復雜場景測試集(自構建):作者利用真實 Android 設備、12 個常見 App(如 Amazon、微信、設置等)與 12 類任務主題(如購物、登錄、搜索等)構建了 1000 條復雜任務指令 , 涵蓋類型包括:
a) 任務類型涵蓋:模糊指令(如省略主語、目標不明確)
b) 環境干擾(如彈窗、網絡斷連)
c) 異常狀態(如登錄過期、權限不足)
每條任務指令被逐步執行并由 GPT-4o 輔助評分 , 生成具有置信度標注的完整 GUI 軌跡數據 。
2)公開基準數據集
a) AITZ(Android In The Zoo):包含復雜鏈式操作 , 強調 reasoning 和 action planning 。
b) Meta-GUI:結合多模態對話和 GUI 控制 , 支持任務引導與精細指令執行 。
數據集被劃分為訓練集(80%)和測試集(20%) , 用于模型訓練與評估 。
3.1.2 評估指標
為了全面評價 GUI 智能體的表現 , 作者采用了以下多個指標:動作類型準確率(Type)、步驟級成功率(SR)、任務完成率(TSR)、人機介入成功率(HSR)、干預精度(IP)等 。
3.1.3 比較模型設置
實驗的設置分為 Fine-tuning 和 Zero-shot 模式 , 對比的模型涵蓋三類:
1) API 接口型模型
a) GPT-4o
b) GPT-4V-Plus
c) Qwen-VL-MAX
2) 開源多模態模型
a) Qwen2-VL-7B
b) OS-Atlas-Pro-7B
c) Auto-UI
3.1.4 模型與訓練設置
為了確保實驗的公平性 , 每個數據集的任務軌跡被隨機劃分為 80% 用于訓練數據 , 20% 用于測試數據 。 在 Zero-shot 中 , 模型直接通過 prompt 學習進行評估 , 不依賴任何額外的微調 。 在 Fine-tuning 設置下 , 模型在對應的數據集上進行 8 輪訓練 , 學習率為 1e-5 。 在交互模式下 , OS-Kairos 使用一個默認的置信度閾值 γ=4 , 當當前步驟的置信度低于此閾值時 , 系統會請求人工干預 。 在整個過程中 , GPT-4o 被用作裁判模型對每一步的動作進行評分 , 確保評估的一致性和可靠性 。
3.2 實驗結果
3.2.1 主要實驗結果
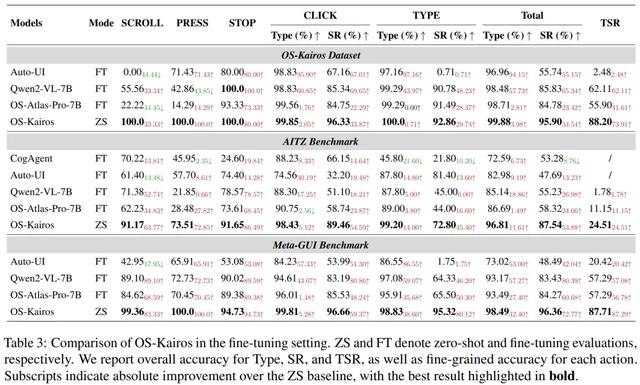
表 1: Zero-shot 設置下 OS-Kairos 與基線比較的結果
1)在 Zero-shot 設置下 , OS-Kairos 無需改變模型能力 , 僅通過引入置信度驅動的自適應交互機制 , 就顯著優于多個基線模型 。 在三個數據集上均表現出色 , 復雜場景下實現了 95.90% 的步驟成功率和 88.20% 的任務完成率 。 相比之下 , 現有 API 模型雖具備通用性 , 但因無法識別關鍵復雜步驟 , 易出現過度執行而導致任務失敗 , 凸顯了 OS-Kairos 在可靠性 。
表 2: Fine-tuning 設置下 OS-Kairos 與基線比較的結果
2)盡管 Fine-tuning 在一定程度上緩解了 GUI 智能體的過度執行問題 , 但是 OS-Kairos 依然表現出更強的性能 , 尤其在復雜場景中 , 其任務完成率(TSR)帶來 26.09% 到 85.72% 的絕對提升 。 通過識別如 SCROLL 等關鍵復雜步驟 , OS-Kairos 實現了更精準的優化 , 而傳統微調方法則可能引入操作偏差或面臨優化瓶頸 。
三種數據集下介入精度分析
3)OS-Kairos 的置信度評分機制實現了高效的人機交互(HSR) 。 在復雜場景與 Meta-GUI 中 , 其對自主執行步驟的判斷高度準確 , AP 指標分別達到 96.44% 和 93.18% , 同時在人為干預步驟中保持 70% 以上的干預精度(IP) 。 這表明 OS-Kairos 能有效區分何時應請求幫助、何時應獨立執行 , 避免不必要的干預 。 研究還指出 , 結合高質量采樣 , 系統在如 AITZ 等數據集中的表現有望進一步提升 。
3.2.2 實驗分析
3.2.2.1 動態評估
以往的基準評估一般基于靜態分析 , 難以反映 GUI 智能體在真實環境中的自主規劃與泛化能力 。 為此 , 論文在移動設備上報告了實際任務完成率(TSR) 。 結果顯示 , 現有基線模型的 TSR 僅為 4% 和 26% , GPT-4o 為 36% , 而 OS-Kairos 在介入時通過引入 GPT-4o 決策 , 達到了這一上限 。 在引入人工干預后 , OS-Kairos 的 TSR 從 32% 提升至 70% , 充分證明自適應交互機制在真實場景中具有顯著優勢 , 是實現高效 GUI 智能體的有效范式 。
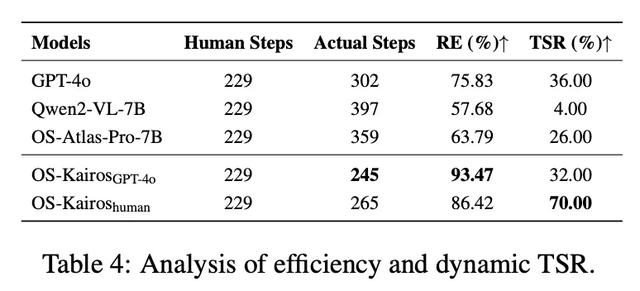
3.2.2.2 效率評估
表 4 還展示了 OS-Kairos 在真實環境中的執行效率 。 基于 50 條指令統計 , 人工執行的最優步驟數約為 429 步 。 在最大操作步數限制為 10 的條件下 , 基線模型在遇到復雜步驟時普遍存在過度執行現象 。 而 OS-Kairos 更貼近人類的操作行為 , 其相對效率(RE)分別達到 86.42% 和 93.47% , 顯著優于基線 , 體現了其高效且穩健的交互能力 。
3.2.2.3 置信度集成范式評估
表 5 對比了 OS-Kairos 與基于 prompt 的交互模型 , 結果顯示 OS-Kairos 的交互機制顯著優于 prompt 驅動范式 , 尤其在介入成功率(HSR)上超越了 prompt 模式下的 OS-Atlas-Pro-7B 。 盡管 GPT-4o 和 GLM-4V-Plus 具備較強的感知和定位能力 , API 型 GUI Agent 仍表現出不穩定性 , 易出現過度執行 , 影響整體效果 。 在開源模型中 , Qwen2-VL-7B 的表現相對更穩定 , 而 OS-Atlas-Pro-7B 在 prompt 模式下指令執行能力被嚴重干擾 。
3.2.2.4 模型和數據分析
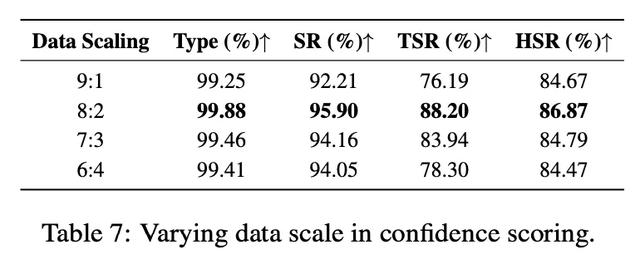
盡管基于 7B 模型構建 , OS-Kairos 通過置信度評分與數據蒸餾 , 可有效遷移至 2B~7B 模型 。 在 Qwen2-VL-2B、4B 和 7B 上分別達到 85.09%、77.64% 和 76.40% 的 TSR , 表現出良好的精度與兼容性 , 適用于資源受限環境部署 。 OS-Kairos 在不同數據規模下依然保持穩定表現 , TSR 可達 76.19%~88.20% 。 即便使用少量探測數據 , 置信度機制也能有效支撐模型訓練 , 成本遠低于微調 。
3.2.2.5 交互敏感度分析
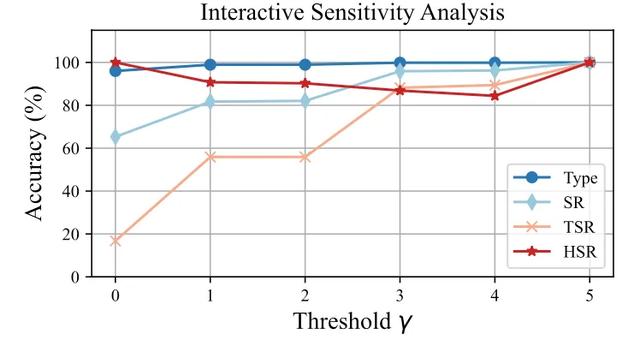
OS-Kairos 通過調節置信度閾值 γ 實現自適應交互 。 消融實驗表明 , γ 提高可顯著提升 TSR 和 SR , 而 HSR 與操作準確率保持穩定 , 說明其能有效識別復雜步驟 , 減少過度執行 。 在 γ = 2 時 , 僅需 19% 的人工干預即可達到接近微調的效果 , 展現出良好的靈活性與實用性 。
四、討論與啟示
4.1 主要發現總結
本研究通過全面的實驗評估 , 得出了以下主要發現:
1.OS-Kairos 在多個數據集上顯著優于 prompt-based 基線模型及微調模型 , 充分證明自適應交互機制對于提升 GUI Agent 任務完成的可靠性與魯棒性具有關鍵作用 。
2. 置信驅動交互高效穩定:OS-Kairos 能穩定區分何時需要干預 , 有效避免過度執行 。
3. 真實設備測試表現優越:在移動設備上運行時 , OS-Kairos TSR 達 32%(無干預)至 70%(有干預) , 遠超現有開源和商用模型 , 接近 GPT-4o 的上限水平 。
4. 模型規模與數據成本友好:置信度機制可遷移至 2B~7B 模型 , 在資源受限場景中依然保持 76% 以上的 TSR , 僅需少量探測數據即可訓練 , 成本遠低于全量微調 。
4.2 啟示
4.2.1 對從業者的啟示
1. 增強系統可靠性:置信度驅動的自適應交互機制可顯著減少錯誤操作 , 提升系統在復雜真實場景中的穩定性與安全性 。
2. 支持人機協作設計:通過動態決策是否請求用戶干預 , 系統可靈活權衡自主性與可控性 , 適用于高風險任務如金融、醫療等場景 。
4.2.2 對研究社區的啟示
1. 拓展交互智能研究范式:本研究強調從 “全自主執行” 轉向 “置信度引導下的自適應協作” , 為多模態 GUI 智能體設計提供新思路 。
2. 提出具遷移性的框架設計:驗證了數據蒸餾與置信機制在不同模型規模下的一致性 , 鼓勵發展輕量級、可推廣的交互方法 。
3. 推動標準評估體系更新:指出靜態測試局限 , 倡導引入真實環境 + 交互能力評估的新標準 , 有助于更全面地衡量 GUI Agent 的實用性與可靠性 。
4.3 批判性分析
1. 適用范圍與可推廣性:目前系統主要驗證于移動 GUI 環境 , 對于桌面端、Web 端尚未進行測試 , 其泛化能力在更復雜的多模態交互系統中仍需驗證 。
2. 置信度分數:置信度分數是來自 Actor-Critic 探測架構下的 GPT-4o 給出 , 其準確性需要進一步驗證 。
五. 局限性與未來工作
5.1 局限性
1. 任務類型與應用場景有限:實驗主要集中在移動端單任務 GUI 環境 , 對于桌面端、多窗口、Web 或混合界面等復雜交互形式尚未驗證 。
2. 依賴外部大模型評分:當前系統在訓練與評估中使用 GPT-4o 作為置信度評分器 , 提升了標注質量 , 但其準確性需進一步優化 。
3. 過度介入:OS-Kairos 通過置信度分數評估是否需要人類介入 , 但過度介入會影響 GUI Agent 的自動化 。
【讓GUI智能體不再過度執行,上海交大、Meta聯合發布OS-Kairos系統】5.2 未來工作
1. 實現模型內部置信度量化:當前置信度依賴外部模型 , 未來可探索在智能體內部實現置信度量化 , 提升推理效率與部署實用性 。
2. 優化交互決策策略:為避免過度執行或頻繁干預 , 可引入動態閾值或強化學習策略 , 實現更靈活、高效的人機協作控制 。
3. 支持復雜任務與跨平臺部署:推動模型在桌面端和 Web 平臺的應用 , 增強其處理復雜任務和多模態語音輸入的能力 , 提升泛化性與實用性 。
推薦閱讀










- 李飛飛最新訪談:沒有空間智能,AGI就不完整
- “兄弟暢享印”創新升級,單打印機型變身智能工作站
- 蘋果老款旗艦價格下來以后,真的讓人很難不動心
- 2013年到底談了什么?貓王創始人VS小米,智能音箱羅生門
- 華為將憑借HBM芯片在AI智能手機競爭中領先蘋果
- UI不再花里胡哨,Android 16要讓你用得更安心
- 駕考寶典母公司木倉科技最新智能駕駛模擬器亮相 AI重塑智能駕培生態
- 全球智能手機銷量排名:vivo第四,小米第三,第一名意料之中
- 揭秘AI公司如何賺錢:快速看懂人工智能產業鏈的生意經
- 策略改寫「一戰歷史」,中科院開源全新博弈智能體框架DipLLM