
文章圖片
文章圖片

文章圖片

作者介紹:盛舉義 , 北京大學在讀博士研究生 , 研究方向為機器人操作技能學習方法研究;王梓懿、李培銘 , 北京大學在讀碩士研究生 , 研究方向為視頻理解分析;劉勇 , 浙江大學控制科學與工程學院教授 , 研究領域為自主機器人與智能系統;劉夢源 , 北京大學深圳研究生院助理教授 , 研究領域為人類行為理解與機器人技能學習 。
【北大提出機器人學習新范式MP1,實現速度與成功率雙SOTA】在目前的 VLA 模型中 , 「A」— 動作生成模型決定了動作生成的質量以及速度 。 具體而言 , 生成式模型在推理速度與任務成功率之間存在 「根本性權衡」 。
其中 , Diffusion Models(如 Diffusion Policy 和 DP3)通過多步迭代生成高質量動作序列 , 但推理速度較慢 , 難以滿足實時控制要求;而 Flow-based 模型(如 FlowPolicy)盡管能提供快速推理 , 但需要額外的架構約束或一致性損失(consistency loss)來保證軌跡的有效性 , 這增加了設計復雜性并可能限制性能和泛化能力 。
此外 , 機器人操作面臨另一個挑戰 , 即數據高效的少樣本泛化 。 標準模仿學習策略容易出現 「特征坍塌(feature collapse)」 , 即將需要不同動作的關鍵狀態錯誤地映射到相似的潛在表征 latent representation)上 , 導致模型在新情境下無法做出準確反應 。 因此 , 提升模型對不同狀態的區分能力是提高策略泛化性的關鍵 。
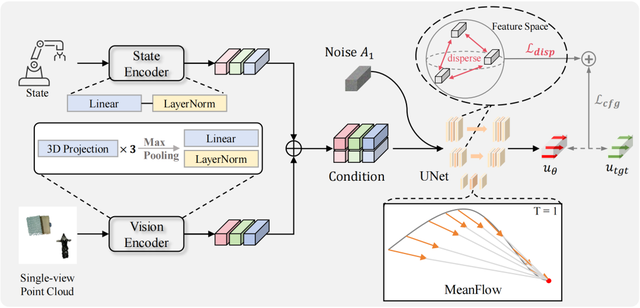
為應對上述挑戰 , 來自北大的研究團隊提出名為 MP1 的全新機器人學習框架 。 該框架首次將近期在圖像生成領域取得突破的 MeanFlow 范式引入機器人學習 , 實現毫秒級推理速度 , 為 VLA 動作生成模型打下基礎 。
- 論文標題:MP1: Mean Flow Tames Policy Learning in 1-step for Robotic Manipulation
- 論文鏈接:https://arxiv.org/abs/2507.10543
- 代碼鏈接: https://github.com/LogSSim/MP1
MP1 的核心引擎 ——Mean Flow 范式
MP1 的核心創新在于其生成范式的根本轉變 。 傳統 Flow Matching 學習的是一個瞬時速度?。 ╥nstantaneous velocity field) , 在推理時需要通過迭代式求解常微分方程(ODE)來積分生成軌跡 , 這一過程不僅耗時 , 且會引入并累積數值誤差 。 與之相反 , MP1 直接學習從初始噪聲到目標動作的區間平均速度?。 ╥nterval-averaged velocity field) 。
技術上 , MP1 利用了 「MeanFlow Identity」 , 使模型能夠直接對平均速度場進行建模 , 而無需在推理時進行任何積分求解 。 這一設計帶來了兩大核心優勢:
- 真正的單步生成(1-NFE):模型僅需一次網絡前向傳播 , 即可從隨機噪聲直接生成完整動作軌跡 , 徹底擺脫了對迭代式 ODE 求解器的依賴 。
- 無約束的簡潔性:得益于其數學形式的完備性 , MP1 天然保證了軌跡質量 , 無需引入 FlowPolicy 等方法所依賴的外部一致性約束 , 使模型設計更為簡潔、優雅 。
這種從數學原理上解決問題的方式 , 而非依賴工程技巧進行修補 , 使得 MP1 不僅實現了速度的飛躍 , 更重要的是 , 其單次、確定性的前向傳播過程保證了推理時間的高度穩定 , 這能夠保證機器人操作任務中的實時性 。
分散損失提升少樣本泛化能力
在解決軌跡生成的動態問題后 , MP1 針對機器人學習中的 「表征坍塌」 問題進行了改進 。 該問題指的是策略網絡將需要不同動作的關鍵狀態錯誤地映射到相近的潛在空間位置 , 從而導致模型在少樣本學習中泛化能力下降 。
MP1 引入了來自表征學習領域的最新方法 —— 分散損失(Dispersive Loss) 。 這是一種輕量級、僅在訓練階段生效的正則化項 , 旨在直接優化策略網絡的內部表征空間 。 其核心思想是在訓練的每個 mini-batch 中 , 對不同輸入樣本的潛在表征施加一種 「排斥力」 , 強制它們在特征空間中相互分散 。 該損失可以被理解為一種 「無正樣本的對比損失」:策略網絡主要的回歸目標負責將每個狀態 「拉向」 其對應的專家動作 , 而分散損失則負責將不同狀態的表征相互 「推開」 , 從而塑造出一個更具辨識度的特征空間 。
分散損失的關鍵優勢在于它是一個僅在訓練時生效的正則化器 , 在不增加任何推理開銷的前提下 , 顯著提升了模型區分細微場景差異的能力 , 完美保留了 MP1 標志性的毫秒級響應速度 。 在數據采集成本高昂的機器人領域 , 這種能從極少量(如 5-10 個)示教中高效學習的能力至關重要 。
MP1 的仿真測試表現
MP1 的性能優勢在涵蓋 37 個復雜操作任務的 Adroit 與 Meta-World 基準測試中得到了驗證 。
出色的任務成功率與穩定性
在任務成功率方面 , MP1 平均成功率達到 78.9% , 相較于當前先進的流模型 FlowPolicy (71.6%) 和擴散模型 DP3 (68.7%) , 分別實現了 7.3% 和 10.2% 的顯著提升 。
尤為關鍵的是 , MP1 的優勢在更高難度的任務中愈發凸顯 。 在 Meta-World 的 「中等」、「困難」 及 「非常困難」 任務集上 , MP1 相較于 FlowPolicy 的成功率增幅分別高達 9.8%、17.9% 和 15.0%。 此外 , MP1 展現出極高的性能穩定性 。 在多次隨機種子實驗中 , 其成功率的平均標準差僅為 ±2.1% , 遠低于其他基線方法 , 證明了其結果的高度可靠性與可復現性 。
卓越的推理效率與實時控制能力
在實現更高成功率的同時 , MP1 的推理速度同樣刷新了紀錄 。 在 NVIDIA RTX 4090 GPU 上 , 其平均推理耗時僅為 6.8ms 。
這一速度比當前最快的流模型 FlowPolicy (12.6 ms) 快了近 2 倍 , 更比強大的擴散模型 DP3 (132.2 ms) 快了 19 倍 。 如此低的延遲意味著 MP1 的決策環路完全滿足機器人領域典型的實時控制頻率(通常為 20-50 毫秒) 。
少樣本學習能力驗證
為了進一步驗證分散損失在提升模型數據效率上的作用 , 研究團隊還進行了少樣本學習的消融實驗 。
實驗結果表明 , MP1 在所有數據量級上均一致地優于 FlowPolicy , 尤其是在示教數據極為稀少(如 2-5 個)的極端少樣本場景下 。 這有力地證明了分散損失通過優化內部表征空間 , 能夠有效提升策略少樣本學習的泛化能力 , 這可以降低真機部署時大量數據的需求 。
MP1 的真機驗證
研究團隊將 MP1 部署于一臺 ARX R5 雙臂機器人上 , 并在五個真實的桌面操作任務中進行了測試 。
實驗結果進一步印證了 MP1 的性能 。 在所有五項任務中 , MP1 均取得了最高的成功率和最短的任務完成時間 。 以 「Hummer」 任務為例 , MP1 的成功率高達 90% , 遠超 FlowPolicy 和 DP3 的 70%;同時 , 其平均任務耗時僅 18.6 秒 , 顯著快于 FlowPolicy(22.3 秒)和 DP3(31.1 秒) 。
推薦閱讀











- 清華醫工平臺提出大模型「全周期」醫學能力評測框架MultiCogEval
- 北京機器人公司攻陷歐美家庭!三年營收翻7倍,獨家對話創始人
- 具身智能機器人公司逐際動力LimX Dynamics獲京東戰略領投
- 智元、宇樹扎堆上市,半年 300 億融資背后,機器人賽道「太火了」?
- 近億元機器人大單,優必選拿下
- 機器人的GPT時刻?豐田研究院悄悄做了一場最嚴謹的VLA驗證實驗
- 近億元機器人大單,優必選拿下!
- 告別“機器人”朗讀,我的耳朵終于被華為閱讀精品音色3.0拯救了
- 人形機器人市場再掀熱潮,五大科技巨頭齊入場加速技術驗證步伐!
- ICML 2025 Oral!北大和騰訊優圖破解AI生成圖像檢測泛化難題