文章圖片

文章圖片
文章圖片
文章圖片
打開字節、阿里們的多模態能力地圖 , 每塊寶藏都標著\"語音” 。
近期 , 就在阿里通義千問團隊發布翻譯模型Qwen-MT的同一天 , 字節跳動旗下的火山引擎正式對外發布了豆包·同聲傳譯模型 Seed LiveInterpret 2.0 , 后者的模型在多個Benchmark測試中都獲得了大幅度領先 , 但其實該模型的首版發布已經是去年的事了 。
時隔一年 , 字節再次將這個模型端出來 , 并花大力氣更新換代了一次 , 字節想做什么?
我們可以把時間線串聯起來看:字節豆包團隊于 2024 年推出了旗艦語音生成基礎模型 Seed-TTS , 今年1月發布了豆包 Realtime Voice Model(首個端到端語音理解與生成模型) , 4月開源了中英雙語TTS模型MegaTTS3 , 1個月前則發布了豆包播客語音模型 。
作為豆包多模態能力中的重要一環 , 字節將同聲傳譯補足到了語音能力之中 。 反觀阿里 , 去年也曾高調推出了新一代端到端語音翻譯大模型 Gummy , 這回在翻譯能力上又進一步 。 如果將視野再打開 , 環顧國內外 , 我們能看到阿里巴巴、字節、科大訊飛、Grok、OpenAI、Meta都在向語音類賽道瘋狂投入資源 。
吸引一眾AI廠商紛紛加碼語音模型的背后 , 則是行業對新一代“語義交互”方式的競爭 。
一旦突破“實時語音+實時翻譯+實時輸出”的技術體驗屏障 , 其將直接打開AI產品的商業化想象空間 。
譬如AI硬件 。 新一代AI硬件浪潮正對語音翻譯技術產生著強烈的需求牽引 。 尤其是國內正在打響的“百鏡大戰” 。 翻譯模型Qwen-MT亮相兩天后 , 阿里在WAIC上正式推出了首款AI眼鏡 。 字節也被爆將在年內發布自家的AI眼鏡 。
不同于電腦和手機等終端硬件的文字交互方式 , 沒有鍵盤的眼鏡 , 天然便適合語音交互這一新形式 。 不過 , 當下阻礙AI眼鏡普及的一大難點 , 也恰恰在語音交互體驗的不完備上 。
從這個角度來說 , 字節和阿里對語音模型的押注 , 頗有點給自家AI眼鏡打好前站的意思 。
A那么 , 語音類賽道到底正在發生著什么?豆包同傳2.0表現如何?
讓我們先來看看這個產品的實際能力 。
同聲傳譯已經是各種圈子內的“老需求”了 , 并不新鮮 。 不過此模型 , 仍然吸引了全網不小的注意 。 這主要在于大家通過這次模型的升級 , 意識到了其背后的“泛商業價值” 。
這款語音模型已經能夠以極低的延遲、更絲滑的效果 , 輸出與用戶音色相一致的英語翻譯 。 一邊接收源語言語音輸入 , 一邊 0 樣本聲音復刻用戶聲音 , 直接輸出目標語言的翻譯語音 。
我們來試一試 。 字節官方提供了體驗地址 , 登錄該網址后 , 每日有20次體驗同聲翻譯的機會 。
【豆包上新同聲傳譯,順便狙擊阿里AI眼鏡?】我們以在WAIC2025上進行的AI教父Geoffrey Hinton的演講為例 。
該同傳大模型目前僅支持中英間轉錄 , 我們先來試試中文 , Hinton談論大語言模型的一段中文翻譯:
今天的大語言模型(LLM)可以看作是當年我所構建的小型語言模型的后繼者 , 是自 1985 年以來語言技術演進中的一個重要里程碑 。 它們以更長的詞序列作為輸入 , 采用更復雜的神經網絡結構 , 并在特征學習中建立了更精妙的交互機制 。
正如我當初設計的小模型那樣 , LLM 的基本原理與人類理解語言的方式本質一致:將語言轉化為特征表示 , 并在多個層次上對這些特征進行精密的整合與重構 。 這正是 LLM 在其各個神經網絡層中所執行的核心任務 。
因此 , 我們有理由說 , LLM 確實在某種意義上“理解”了它們所生成的語言 。
在這段視頻中 , 你能非常清晰地聽到 , 該語音模型對于用戶輸入的自然語言短句的識別能力非常強 , 也非常迅速 。 即便只是一個很短的間隔 , 模型也能夠準確識別到 , 并根據這種間隔判斷如何翻譯 。
像是下圖 , 模型會自動根據語境 , 而選擇不更改主語 , 在翻譯過程中 , 模型會根據上下文自動判斷是否需要重復主語:
除此之外 , 當我輸入語音的同時 , 它也在實時克隆我的音色 , 當然效果稱不上很好 , 但也確實有一些相似度 。
我又測試了一段魯迅語錄 , 其中可能會有一些語病 , 你會更明顯地發現該模型在同傳過程中的延遲非常低 。 像是“有一份熱 , 便發一份光”“無窮的遠方 , 無數的人們”中間的簡短時間非常的短 , 幾近于連讀 , 而模型也依然覺察出來了 。
我們再來試一試Hinton的英文講座 , 這回我們非常明顯地發現同傳模型對于音色的克隆效果大幅下降了 , 幾乎沒有相似度 。 但是在翻譯場景下的表現 , 包括低延遲、準確度、自然的斷句等等 , 依然比較好 。
目前該模型主要聚焦中英文對話 , 這點上與 Meta 的SeamlessStreaming 等跨語種模型相比仍有差距。 Meta 在2023年12月發布 Seamlessstreaming 時 , 就已經能夠涵蓋近 100 種輸入語言和 36 種語音輸出語言 。 從\"語言覆蓋面\"這個角度 , 字節確實還有很長的路要走 。
除此之外 , 在用戶體驗上雙方之間的差距已急劇縮小 。
字節同步發布了基準測試成績 , Streamlessstreaming仍舊停留在這張表上 , 不過SeedLiveInterpret 2.0成績很不錯 。 中英互譯平均翻譯質量的人類評分達到 74.8(滿分 100 , 評估譯文準確率)
相比之下 , 其他大多廠商的語音同傳翻譯產品基本不支持實時的語音復刻 , 在體驗上基本維持在語音輸入文字輸出的交互方式 , 我們也就不再多進行類比 。
客觀地說 , 體驗下來 , 目前的模型技術還存在一些明顯的局限 。在不同語言方向上的音色克隆表現差異較大 , 技術的一致性還需要改進 。對于特定領域的專業詞匯 , 翻譯準確度還有提升空間 。 不過 , 語音復刻雖然略顯稚嫩 , 但也確實帶來了更有意思的交互體感 。
B同傳語音模型相對于單純語音生成來說 , 難度可能已經是Next Level了 。 同傳模型需要同時做三件事:聽懂你說的話(語音識別)、翻譯成另一種語言(機器翻譯)、再用自然的聲音說出來(語音合成) 。
因此 , 這波字節語音翻譯模型的升級并不只是為了做一個“翻譯軟件” 。 它的核心價值在于\"語音交互\"能力已經宣告成熟 , 翻譯只是其中一個應用場景 。
這是關于“語義交互”方式的競爭 。
豆包同傳模型2.0的推出 , 實際上是字節跳動在AI大模型生態布局中的重要一步 。 回顧一下時間線:早在2024年 , 豆包就發布了初代同傳模型 , 但那時只能輸出文字翻譯結果 。
當然 , 除了字節之外 , 無論是國內還是國外 , 幾乎所有基礎大模型廠商都把目光投向了語音模型這個賽道 。 然而 , 生成語音很簡單 , 難的是“實時語音+實時翻譯+實時輸出” , 許多大廠都正在攻堅 。
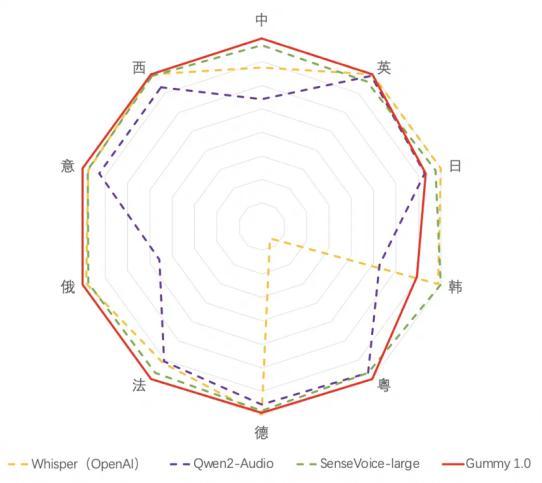
比如 , 只談及“純血同傳翻譯”模型的話 , 大家自然會把目光轉向阿里巴巴 。 在2024年云棲大會上 , 阿里高調推出了新一代端到端語音翻譯大模型 Gummy , 雖然無法實時語音復刻 , 但也可實時流式生成語音識別與翻譯結果 。
其在多個維度中都獲得了SOTA級別的表現 , 翻譯延遲甚至降到了0.5s以下:
\"賣體驗\"比\"賣翻譯功能\"要更吸引人 。
同傳翻譯模型2.0背后 , 大家的關注點更多的還是在于語音類模型背后的潛力 , 而非垂直翻譯能力 , 大家的興奮點并不在于它能把中文翻譯成英文有多準確 。
如果 , 我們繼續將目光放寬一點 , 會發現專攻語音交互模型賽道的選手 , 已經遍布整個市場了 , 它們正在從各個角度撬動用戶應用場景 。
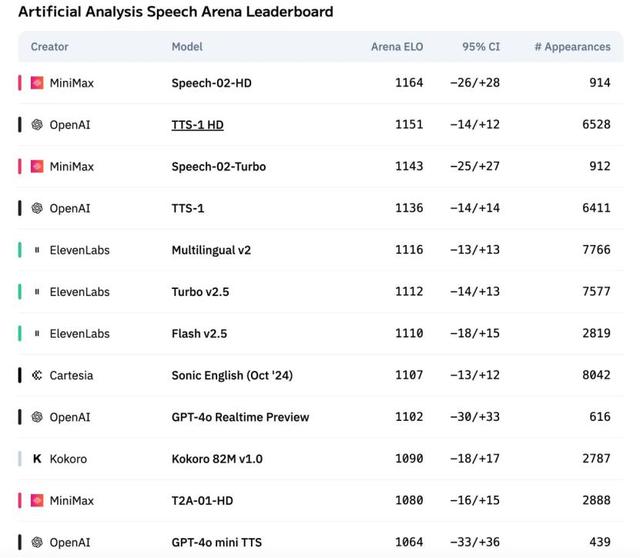
像是最近 , 在輿論場和資本場拿回一點聲量的“AI六小龍”之一—— MiniMax , 也不甘示弱連續發布了MiniMax-Speech系列模型 , 特別是2025年5月推出的 Speech-02 模型 , 號稱是\"全球第一的TTS語音模型\" 。
其在社交場上獲得聲量并引起關注的原因 , 追其根本 , 在于它單次輸入支持 200K 字符 , 支持 30 多種語言 , 擁有超逼真的語音克隆體驗 。
OpenAI的高級語音模式就更不用提了 , 如果你翻看各種社媒產品 , 就會發現幾乎所有領域的用戶都在抱怨“Plus用戶的語音限額有點少的可憐” , 這說明低延遲、實時語音、擬人性的需求非常高 。
只不過 , OpenAI做產品確實有點慢 , 尚未將手伸向一些明確的應用場景 , 不過倒是投了一批初創企業 。 像是語言學習語音交互平臺 Speak , 2024 年年底OpenAI曾參與其 7800 萬美元融資 , 并將自身語音技術模型融入進去 , 現在這家公司估值已經突破 10 億美元了 。
Elon Musk也早早布局 , 他xAI旗下的Grok模型最近也卷入了語音賽道:7月中旬 , Grok應用新增了\"伴侶模式\" , 上線了一位可互動的3D虛擬AI少女形象 Ani 。 這個虛擬角色可以用甜美的動漫嗓音與用戶對話 , 在日本網友中迅速走紅 , 被戲稱為\"AI女友\" 。
Grok對語音能力的意識顯然要比其他大廠商超前一點 , 像是ElevenLabs等初創企業與Grok在腦機接口上的合作 , 為漸凍癥患者替換聲音的操作 , 自然而然為這類模型打了一個大大的廣告 。
C多方動向背后 , 說明業界對于實時語音在AI產品商業化中的價值形成了共識 。
首先讓我們回顧下AI產品的發展軌跡 , 在多模態交互中 , 構建從“語音到語音”的閉環體驗在過去兩年就被認為是下一個關鍵目標 。 過去的AI產品(無論是Chatbot還是AI 硬件)更多停留在文字和圖像處理層面 , 但在人類日常交流中 , 語音才是最自然、最高效的溝通方式 。 所以 , 語音交互能帶給用戶更好更佳更AI的體驗過程 , 而這正好意味著一片“痛點藍海” 。
各大廠搶攻語音模型 , 正是為了搶占這一未來的藍海市場 , 其第一步就是搶占入口 。
相信從過去一年的“Chatbot”入口界面爭奪戰中 , 許多基礎模型廠商都悟得了一個道理:單純文字對話的用戶體驗每上升1分 , 背后可能是100分的模型能力提升 , 10000分的算力、算法、架構的投入 。
因為語音交互不像搜索引擎那樣存在一個絕對的入口 , 用戶可能從任何一個點開始接觸 , 然后逐漸習慣這種交互方式 , 這背后的商業價值可以說高到難以想象 。
這場語音賽道的集體押注 , 實際上是各大廠商對未來AI應用場景的一次集體下注 。
從進入2025年以來 , AI硬件產品已經進入“井噴式領域” 。 各種形態的智能設備如雨后春筍般涌現 。
從最原初的純剛需來看 , 跨國出海或者是會議場景是始終繞不過的一關 。 各種翻譯企業從機器翻譯、神經網絡翻譯再到AI翻譯 , 已經走過了一關又一關 , 商業成果進展緩慢 , 蛋糕做大困難 。 相比之下 , 如果實時語音同傳成熟化 , 這種體驗的商業價值是巨大的 。
無論是這些硬需求 , 還是滿足用戶對于AI未來交互體驗的“軟需求” , 都需要一個合適的載體 —— AI硬件 , 或許很多人對此嗤之以鼻 , 認為其全部是套殼產品 。 但現實是 , 新一代AI硬件浪潮對語音翻譯技術產生了強烈的需求牽引 。 硬件產品非常能夠激發市場去琢磨一個市場還存在哪些尚未被發現的隱秘機會 。
同時 , 在國外各個主力AI模型都已經開始開發不同的收費模式時 , 反觀國內 , 除了AI Agent帶來了較為成體系的價格結構之外 , AI基礎模型廠商幾乎是“一片噤聲” , 無人愿意提及 。 正如大家常說的:“光靠模型就能盈利 , 那是做夢” 。
AI也需要一個載體 。
2023年以來 , 從硅谷初創公司Humane推出的可佩戴顯示設備 AI Pin , 到國內創業團隊研發的 Rabbit R1, 年收入近1億美金的AI錄音硬件 Plaude、TicNote、再到字節推出的Ola Friend耳機 , 各種形態的可穿戴AI助手層出不窮 。 科大訊飛也推出了主打實時多語種同傳功能的會議耳機和翻譯耳機 , AI硬件已經事實上成為了各家廠商將AI商業化的“救命稻草” 。
OldFriend 這款勉強被稱為AI硬件的產品 , 可以通過喚醒詞 “豆包豆包” 激活其 AI 聊天助手豆包 , 從而將體驗的支撐角色轉移給豆包 。 但是 , 這種體驗缺乏真正的顛覆性使用場景 。
既然是AI硬件 , 還是要從AI下手 。
當字節宣布同傳大模型2.0發布時 , 同時提到了該模型將在8月迅速進入Old Friend耳機中 , 為其補足更多的語音交互能力 。 我們可以這么理解 , 語音翻譯模型帶來的\"實時語音交互\"體驗 , 正在成為AI硬件產品吸引用戶的新戰場 。
當然 , 在語音這個大領域內 , 還存在其他分支賽道 。 比如字節、MiniMax前段時間都火出圈的AI播客功能 , 以及專注情感陪伴的語音AI產品 。 各家AI創業公司正在瘋狂挖掘語音交互的潛力 , 大家逐漸發現了AI產品發展下半程的\"引爆點\"——語音交互市場 。
此次字節豆包同傳模型的發布、官方迅速宣布該模型將立刻接入硬件 , 以及前段時間字節投入大力氣打造的播客模型等等 , 都在宣告著國內“語音”市場的潛力才剛剛展現 。
“搶占下一代AI產品交互入口之前 , 先把硬件造出來”是國內普遍信奉的樸素商業道理 。 在此之上 , AI廠商們在看到不斷有初創企業通過“較差”或者只是開源的AI大模型技術就已經能發掘出這么多應用場景了 , 肯定會捫心自問:我何樂而不為呢?
尤其是AI實時語音交互賽道 , 尚且沒有將這項體驗完整融合到硬件市場的產品出現 。 作為擁有AI原生技術的字節——這個大廠的標桿之一 , 開始認真考慮:語音交互很可能成為下一個改變人機交互方式的關鍵技術 。
推薦閱讀













- 華為Mate80驚艷亮相:全新黑科技讓人眼前一亮
- 攝影愛好者的福音,vivoX200Pro降至新低,入手真香!
- 手機屏幕出現綠線,是換屏呢?還是換新機?你怎么看
- 首發頂級旗艦U+8000毫安大電池!離譜性價比新機又要賣爆?
- 6.9寸超大LCD屏+高通強U+7000大電池!這小米百元新機是真想買
- LCD屏+7000mAh,紅米即將登場的千元新機,爆款又穩了
- 紅米新品官宣:8月1日,正式開售
- Vibe Coding 開賽,阿里靠新模型贏麻了?
- 真我GT8系列與一加Ace6系列:均傳新消息,誰會更勝一籌?
- 買了新SD卡、U盤或SSD?以下4種方法助你在使用前檢測真偽