
文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
本論文由新加坡國立大學、A*STAR 前沿人工智能研究中心、東北大學、Sea AI Lab、Plastic Labs、華盛頓大學的研究者合作完成 。 劉博、Leon Guertler、余知樂、劉梓辰為論文共同第一作者 。 劉博是新加坡國立大學博士生 , 研究方向為可擴展的自主提升 , 致力于構建能在未知環境中智能決策的自主智能體 。 Leon Guertler 是 A*STAR 前沿人工智能研究中心研究員 , 專注于小型高效語言模型研究 。 余知樂是東北大學博士生 , 研究方向為語言模型的對齊和后訓練 。 劉梓辰是新加坡國立大學和 Sea AI Lab 的聯合培養博士生 , 主要研究語言模型的強化學習訓練 。 通訊作者 Natasha Jaques 是華盛頓大學教授 , 在人機交互和多智能體強化學習領域有深厚造詣 。
近年來 , OpenAI o1 和 DeepSeek-R1 等模型的成功證明了強化學習能夠顯著提升語言模型的推理能力 。 通過基于結果的獎勵機制 , 強化學習使模型能夠發展出可泛化的推理策略 , 在復雜問題上取得了監督微調難以企及的進展 。
【SPIRAL:零和游戲自對弈成為語言模型推理訓練的「免費午餐」】然而 , 當前的推理增強方法面臨著根本性的可擴展性瓶頸:它們嚴重依賴精心設計的獎勵函數、特定領域的數據集和專家監督 。 每個新的推理領域都需要專家制定評估指標、策劃訓練問題 。 這種人工密集的過程在追求更通用智能的道路上變得越來越不可持續 。
來自新加坡國立大學、A*STAR、東北大學等機構的聯合研究團隊提出了 SPIRAL(Self-Play on zero-sum games Incentivizes Reasoning via multi-Agent multi-turn reinforcement Learning) , 通過讓模型在零和游戲中與自己對弈 , 自主發現并強化可泛化的推理模式 , 完全擺脫了對人工監督的依賴 。
論文標題: SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning 論文鏈接:https://huggingface.co/papers/2506.24119 代碼鏈接:https://github.com/spiral-rl/spiral游戲作為推理訓練?。 捍悠絲說絞У木絲繚?
研究團隊的核心洞察是:如果強化學習能夠從預訓練語言模型中選擇出可泛化的思維鏈(Chain-of-Thought CoT)模式 , 那么游戲為這一過程提供了完美的試煉?。 核峭ü溆峁峁┝邸⒖裳櫓さ慕崩?, 無需人工標注 。 通過在這些游戲上進行自對弈 , 強化學習能夠自動發現哪些 CoT 模式在多樣化的競爭場景中獲得成功 , 并逐步強化這些模式 , 創造了一個自主的推理能力提升系統 。
最令人驚訝的發現是:僅通過庫恩撲克(Kuhn Poker)訓練 , 模型的數學推理能力平均提升了 8.7% , 在 Minerva Math 基準測試上更是躍升了 18.1 個百分點!要知道 , 在整個訓練過程中 , 模型從未見過任何數學題目、方程式或學術問題 。
SPIRAL 框架:讓競爭驅動智能涌現
多回合零和游戲的獨特價值
SPIRAL 選擇了三種具有不同認知需求的游戲作為訓練環境:
井字棋(TicTacToe):需要空間模式識別和對抗性規劃 。 玩家必須識別獲勝配置、阻止對手威脅并規劃多步策略 。 研究團隊假設這些技能會遷移到幾何問題求解和空間可視化任務 。 庫恩撲克(Kuhn Poker):一個最小化的撲克變體 , 只有三張牌(J、Q、K) , 玩家在隱藏信息下進行下注 。 成功需要概率計算、對手建模和不確定性下的決策 。 這些能力預期會遷移到涉及概率、期望值和戰略不確定性的問題 。 簡單談判(Simple Negotiation):一個資源交易游戲 , 兩個玩家交換具有相反估值的木材和黃金以最大化投資組合價值 。 成功需要多步規劃、心智理論建模和通過提議與反提議進行戰略溝通 。自對弈的魔力:永不停歇的進化
與固定對手訓練相比 , 自對弈具有獨特優勢 。 研究發現:
對抗強大的固定對手(Gemini-2.0-Flash-Lite):初始勝率為 0%(無學習信號) , 最終停滯在 62.5%(開發出固定的對抗策略) 。 對抗隨機對手:完全崩潰 , 由于「回合詛咒」使得完成有效游戲變得極其困難 。 自對弈:始終保持 50-52% 的勝率 , 確認對手與學習者完美同步進化 。這種自適應的難度調整是關鍵所在 。 隨著模型改進 , 它的對手也在改進 , 創造了一個自動調整的課程體系 。
從游戲到數學:推理模式的神奇遷移
三種核心推理模式的發現
通過分析數千個游戲軌跡和數學解題過程 , 研究團隊發現了三種在游戲中產生并遷移到數學推理的核心模式:
期望值計算:在游戲中從 15% 增長到 78% 的使用率 , 遷移到數學問題時保持 28% 的使用率 。 例如 , 在撲克中計算「跟注的期望值 = 獲勝概率 × 2 - 失敗概率 × 2」 , 這種思維直接應用于數學中的概率和優化問題 。 逐案分析:在撲克決策中出現率達 72% , 以 71% 的高保真度遷移到數學問題求解 。 游戲中的「情況 1:棄牌損失 1 籌碼;情況 2:跟注但失敗損失 2 籌碼」模式 , 完美對應數學中的分類討論方法 。 模式識別:展現出放大效應——游戲中 35% 的使用率在數學領域增長到 45% 。 這表明游戲訓練增強了模型本就存在的數學模式識別能力 。不同游戲培養不同技能
實驗發現 , 不同游戲確實培養了專門化的認知能力:
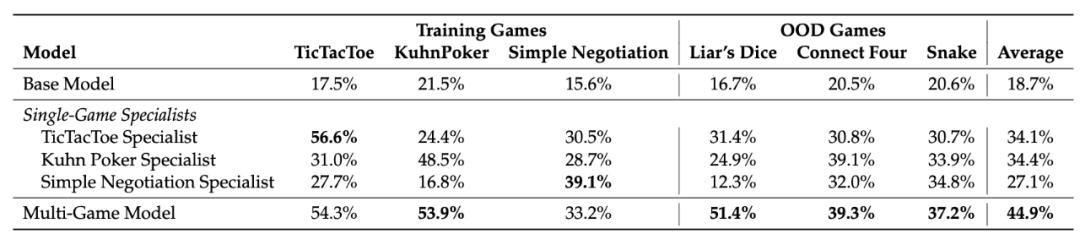
井字棋專家在空間推理游戲 Snake 上達到 56% 勝率 。 庫恩撲克大師在概率游戲 Pig Dice 上取得驚人的 91.7% 勝率 。 簡單談判專家在戰略優化游戲上表現出色 。
更有趣的是 , 當結合多個游戲訓練時 , 技能產生協同效應 。 在 Liar's Dice 上 , 單一游戲專家只能達到 12-25% 的勝率 , 而多游戲訓練模型達到 51.4% 。
技術創新:讓自對弈穩定高效
分布式在線多智能體強化學習系統
為了實現 SPIRAL , 研究團隊開發了一個真正的在線多智能體、多回合強化學習系統 , 用于微調大語言模型 。 該系統采用分布式 actor-learner 架構 , 能夠跨多個雙人零和語言游戲進行全參數更新的在線自對弈 。
角色條件優勢估計(RAE):防止思維崩潰的關鍵
研究中一個關鍵發現是 , 沒有適當的方差減少技術 , 模型會遭受「思維崩潰」——在 200 步后停止生成推理軌跡 , 收斂到最小輸出如「think/thinkanswerbet/answer」 。
角色條件優勢估計(RAE)通過為每個游戲和角色維護單獨的基線來解決這個問題 。 它考慮了角色特定的不對稱性(如井字棋中的先手優勢) , 確保梯度更新反映真正的學習信號而不是位置固有的優勢 。
實驗表明 , 沒有 RAE , 數學性能從 35% 崩潰到 12%(相對下降 66%) , 梯度范數趨近于零 。 RAE 在整個訓練過程中保持穩定的梯度和推理生成 。
廣泛影響:強模型也能受益
SPIRAL 不僅對基礎模型有效 。 在 DeepSeek-R1-Distill-Qwen-7B(一個已經在推理基準測試上達到 59.7% 的強大模型)上應用多游戲 SPIRAL 訓練后 , 性能提升到 61.7% 。 特別值得注意的是 , AIME 2025 的分數從 36.7% 躍升至 46.7% , 足足提升了 10 個百分點!
這表明競爭性自對弈能夠解鎖傳統訓練未能捕獲的推理能力 , 即使在最先進的模型中也是如此 。
深入分析:為什么游戲能教會數學?
研究團隊認為 , 這種跨領域遷移之所以可能 , 有三個關鍵因素:
競爭壓力剝離記憶依賴:自對弈對手不斷進化 , 迫使模型發展真正的推理能力而非模式匹配 。 在傳統的監督學習中 , 模型可能通過記憶特定模式來「作弊」 , 但在對抗不斷變化的對手時 , 只有真正的推理策略才能持續獲勝 。 游戲提供純凈的推理環境:游戲規則簡單明確 , 不需要復雜的領域知識 , 讓模型能專注學習基本的認知操作(枚舉、評估、綜合) , 這些操作能夠有效泛化 。 庫恩撲克中的「如果對手有 K , 我應該棄牌」的推理結構 , 與數學中的條件推理具有相同的邏輯框架 。 結構化輸出搭建領域橋梁:在游戲中學習的think格式提供了一個推理支架 , 模型在數學問題中會重用這種結構 。 這種格式化的思考過程成為了跨領域知識遷移的載體 。對強化學習研究的啟示
SPIRAL 的獨特貢獻在于展示了游戲作為推理訓練場的潛力 。 雖然 DeepSeek-R1 等模型已經證明強化學習能顯著提升推理能力 , 但 SPIRAL 走得更遠:它完全擺脫了對數學題庫、人工評分的依賴 , 僅憑游戲輸贏這一簡單信號就實現了可觀的推理提升 。
研究還揭示了多智能體強化學習在語言模型訓練中的獨特價值 。 與單智能體設置相比 , 多智能體環境提供了更豐富的學習信號和更魯棒的訓練動態 。 這為未來的研究開辟了新方向:
混合博弈類型:結合零和、合作和混合動機游戲 , 可能培養更全面的推理能力 。 元游戲學習:讓模型不僅玩游戲 , 還能創造新游戲 , 實現真正的創造性推理 。 跨模態游戲:將語言游戲擴展到包含視覺、音頻等多模態信息 , 培養更豐富的認知能力 。實踐意義與局限性
實踐意義
對于希望提升模型推理能力的研究者和工程師 , SPIRAL 提供了一種全新的思路 。 不需要收集大量高質量的推理數據 , 只需要設計合適的游戲環境 。 研究團隊已經開源了完整的代碼實現 , 包括分布式訓練框架和游戲環境接口 。
更重要的是 , SPIRAL 驗證了一個關鍵假設:預訓練模型中已經包含了各種推理模式 , 強化學習的作用是從這些模式中篩選和強化那些真正可泛化的思維鏈 。 這改變了我們對模型能力提升的理解 。 我們不是向模型灌輸新的推理方法 , 而是通過競爭壓力讓有效的推理策略自然勝出 , 無效的被淘汰 。 游戲環境就像一個進化選擇器 , 只有真正通用的推理模式才能在不斷變化的對手面前存活下來 。
當前局限
盡管取得了顯著成果 , SPIRAL 仍有一些局限性需要在未來工作中解決:
游戲環境依賴:雖然消除了人工策劃問題的需求 , 但仍需要設計游戲環境 。 計算資源需求:每個實驗需要 8 塊 H100 GPU 運行 25 小時 , 這對許多研究團隊來說是個挑戰 。 性能瓶頸:在長時間訓練后 , 性能提升會趨于平緩 , 需要新的技術突破 。 評估局限:當前評估主要集中在學術基準測試 , 對現實世界推理任務的影響還需進一步驗證 。結語
SPIRAL 的工作不僅僅是一個技術突破 , 更代表了對智能本質的新理解 。 它表明 , 復雜的推理能力可能不需要通過精心設計的課程來教授 , 而是可以通過簡單的競爭環境自然涌現 。
當我們看到一個只會下庫恩撲克的模型突然在數學考試中表現更好時 , 我們不禁要問:智能的本質到底是什么?也許 , 正如 SPIRAL 所展示的 , 智能不是關于掌握特定知識 , 而是關于發展可以跨越領域邊界的思維模式 。
這項研究為自主 AI 發展指明了一個充滿希望的方向 。 在這個方向上 , AI 系統通過相互競爭不斷進化 , 發現我們從未想象過的推理策略 , 最終可能超越人類設計的任何課程體系 。 正如研究團隊在論文中所說:「這只是將自對弈嵌入語言模型訓練的第一步嘗試 。 」
推薦閱讀















- 淘寶和閑魚,最終還是被AI這惡作劇玩壞了
- 大模型隱私安全和公平性有“蹺蹺板”效應,最佳平衡法則剛剛找到
- 華為Mate80突然曝光:外觀和配置進一步確認,或10月正式發布
- 擊敗一加和iQOO,驍龍8至尊領先版+7200mAH,榮耀拿下性價比第1
- 微信轉賬和紅包,原來區別這么大,以后別再用錯了
- 礪算科技首款GPU芯片問世!真自研,暢跑3A大作和大模型
- 單項最高獎勵15萬美元,Meta征集表面肌電圖腕帶和控制算法提案
- 一加Ace 5 Pro和一加13T怎么選?看完區別后,心里有數了
- 小米16曝光:物理零孔直屏+24GB運存,這才是香餑餑
- 2025年上半年中國彩電市場回暖:銷量和銷售額雙增長