
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
智東西
作者 | 云鵬
編輯 | 李水青
智東西8月4日消息 , 剛剛 , 小米公司正式開源聲音理解大模型MiDashengLM-7B 。 其聲音理解性能在22個公開評測集上刷新多模態大模型最好成績(SOTA) , 單樣本推理的首Token延遲(TTFT)為業界先進模型的1/4 , 同等顯存下的數據吞吐效率是業界先進模型的20倍以上 。
具體來看 , MiDashengLM-7B基于Xiaomi Dasheng作為音頻編碼器和Qwen2.5-Omni-7B Thinker作為自回歸解碼器 , 通過通用音頻描述訓練策略 , 實現了對語音、環境聲音和音樂的統一理解 。
此前小米于2024年首次發布Xiaomi Dasheng聲音基座模型 , 此次開源的7B模型是該模型的擴展 。 目前該系列模型在小米智能家居、汽車座艙等領域有30多個落地應用 。
小米稱 , 音頻理解是構建全場景智能生態的關鍵領域 。 MiDashengLM通過統一理解語音、環境聲與音樂的跨領域能力 , 不僅能聽懂用戶周圍發生了什么事情 , 還能分析發現這些事情的隱藏含義 , 提高用戶場景理解的泛化性 。
MiDashengLM的訓練數據由100%公開數據構成 。
GitHub主頁:
https://github.com/xiaomi-research/dasheng-lm
技術報告:
https://github.com/xiaomi-research/dasheng-lm/tree/main/technical_report
模型參數(Hugging Face):
https://huggingface.co/mispeech/midashenglm-7b
模型參數(魔搭社區):
https://modelscope.cn/models/midasheng/midashenglm-7b
網頁Demo:
https://xiaomi-research.github.io/dasheng-lm
交互Demo:
https://huggingface.co/spaces/mispeech/MiDashengLM
一、支持跨場景音頻理解能力 , 音頻編碼器多項關鍵測試超越WhisperMiDashengLM在音頻描述、聲音理解、音頻問答任務中有比較明顯的優勢:
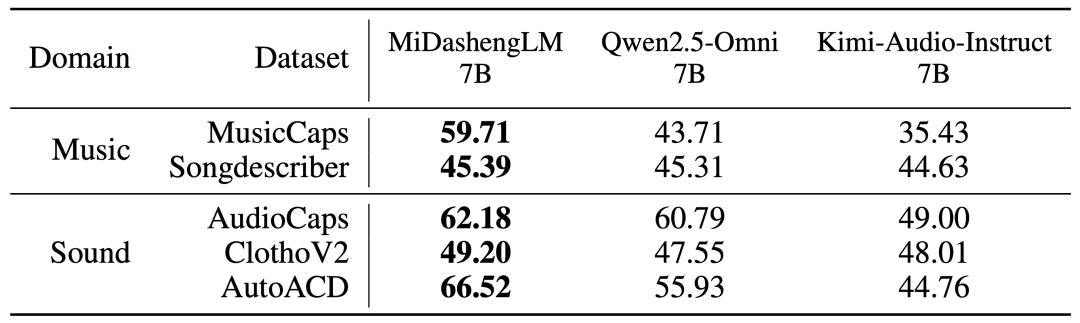
音頻描述任務性能(FENSE指標)
在音頻描述任務中 , MiDashengLM-7B比Qwen、Kimi同類7B模型性能更強 。
聲音理解任務性能
在聲音理解任務中 , MiDashengLM-7B除FMA、VoxCeleb-Gender項目均領先于Qwen的7B模型 , 與Kimi的7B模型相比 , 僅有VoxCeleb-Gender項目略微落后 。
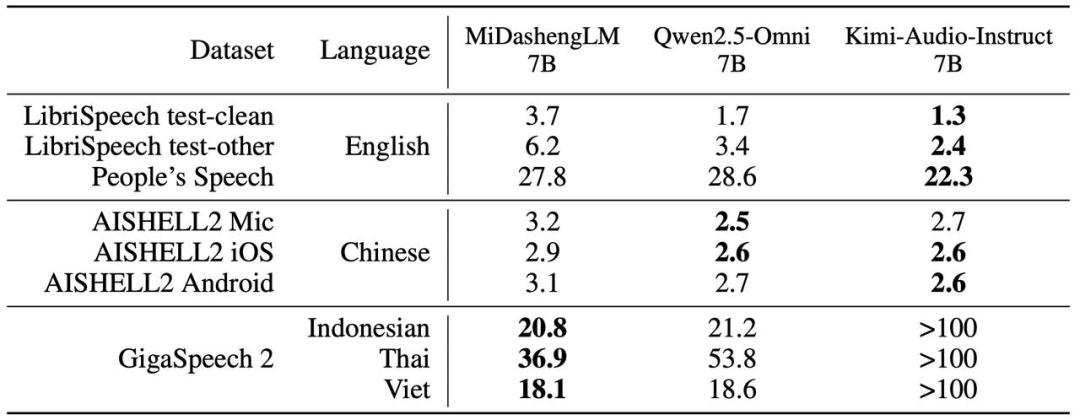
語音識別任務性能(WER/CER指標)
在語音識別任務中 , MiDashengLM-7B的主要優勢在于GigaSpeech 2 , 在其他兩組測試中Qwen和Kimi有一定優勢 。
音頻問答任務性能
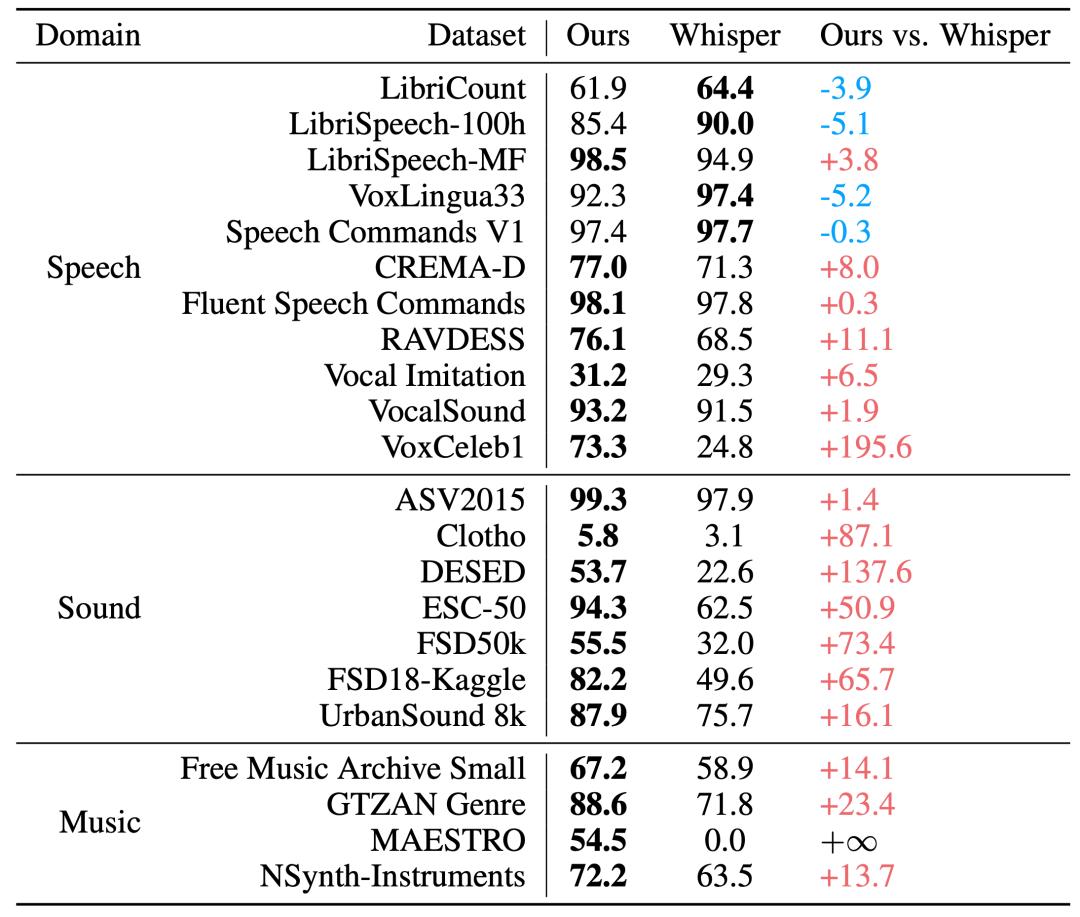
其中 , Xiaomi Dasheng音頻編碼器是MiDashengLM音頻理解能力的重要來源 。 在用于評估編碼器通用能力的X-ARES Benchmark上 , Xiaomi Dasheng在多項關鍵任務上優于作為Qwen2.5-Omni、Kimi-Audio等模型音頻編碼器的Whisper 。
音頻編碼器在X-ARES Benchmark上的分數對比
除了聲音理解 , Xiaomi Dasheng還可以用于音頻生成任務 , 如語音降噪、提取和增強 。
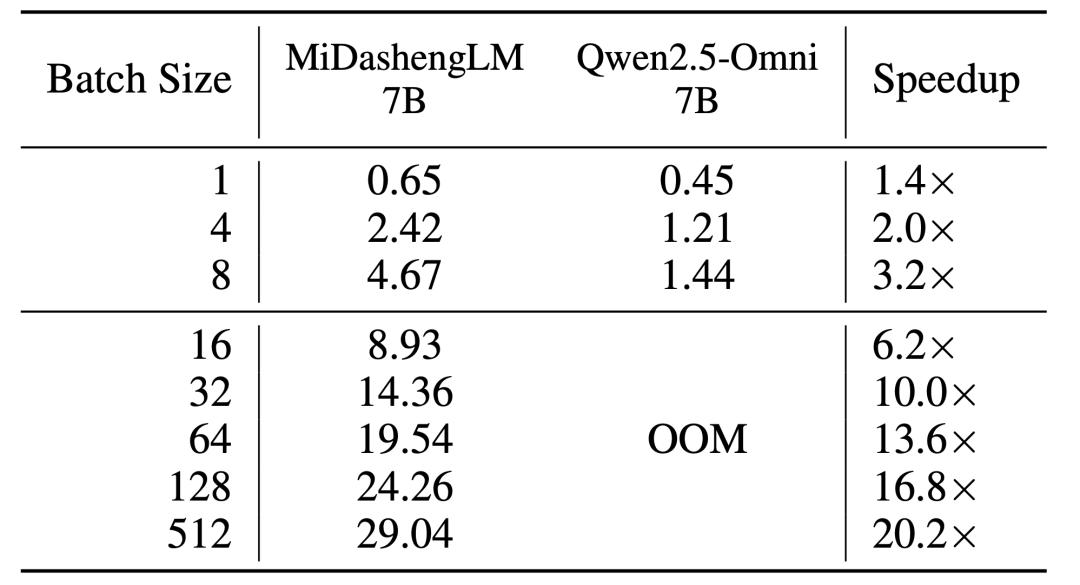
二、推理效率提升 , 單樣本4倍加速與百倍并發支持MiDashengLM的訓練和推理效率是其另一項優勢 。 對于單個樣本推理的情形 , 即batch size為1時 , MiDashengLM的首個token預測時間(TTFT)為Qwen2.5-Omni-7B的1/4 。
批次處理時 , 在80GB GPU上處理30秒音頻并生成100個token的測試中 , MiDashengLM可以把batch size設置為512 , 而Qwen2.5-omni-7B在batch size設置為16時即出現顯存溢出(OOM) 。
Batch size=1時TTFT和GMACS指標對比
在實際部署中 , MiDashengLM在同等硬件條件下可支持更多的并發請求量 , 降低計算成本 。
80G顯存環境下模型每秒可處理的30s音頻個數
這背后 , MiDashengLM基于Xiaomi Dasheng架構 , 在維持音頻理解核心性能指標基本持平的前提下 , 通過優化音頻編碼器設計 , 將其輸出幀率從Qwen2.5-Omni的25Hz降至5Hz , 降幅80% , 降低了計算負載并實現了推理效率提升 。
三、訓練范式改變:從碎片化轉錄到全局語義刻畫MiDashengLM采用通用音頻描述對齊范式 , 避免了用ASR轉錄數據對齊僅關注語音內容而丟棄環境聲音和音樂信息 , 且無法捕捉說話人情感、空間混響等關鍵聲學特征的局限 , 通用描述對齊策略通過非單調的全局語義映射 , 迫使模型學習音頻場景的深層語義關聯 。
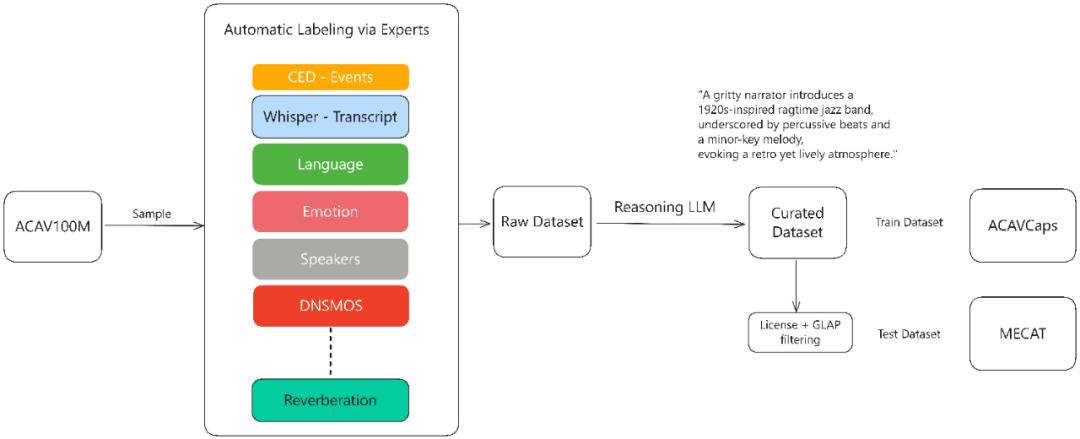
該方法可以使用幾乎所有的數據 , 包括噪聲或非語音內容 , 而基于ASR轉錄的方法會丟棄非語音數據如環境聲或音樂 , 導致數據利用率低下 , 基于ASR的對齊方法在ACAV100M-Speech數據集上會損失90%潛在有用數據 。
MiDashengLM訓練框架
MiDashengLM的訓練數據通過多專家分析管道生成:首先對原始音頻使用各種專家模型作語音、人聲、音樂和環境聲學的細粒度標注 , 包括使用Dasheng-CED模型預測2秒粒度的聲音事件 , 再通過DeepSeek-R1推理大模型合成統一描述 。
全部訓練數據的原始標簽在預訓練中被棄用 , 只采用利用上述流程生成的新的豐富文本描述標簽 , 以迫使模型學習更豐富全面的聲音信息 。
其中 , 來自ACAV100M的開源數據集經過上述流程重新標注后 , 形成了新的ACAVCaps訓練集和MECAT Benchmark 。 MECAT Benchmark已于近期開源 , ACAVCaps數據集將在ICASSP論文評審后開放下載 。
ACAVCaps訓練數據集構建流程
四、全棧開源 , 透明可復現此次MiDashengLM訓練數據100%來自公開數據集 , 涵蓋五類110萬小時資源 , 包括語音識別、環境聲音、音樂理解、語音副語言和問答任務等多項領域 。
MiDashengLM完整公開了77個數據源的詳細配比 , 技術報告公開了從音頻編碼器預訓練到指令微調的全流程 。
據官方信息 , 小米已開始對Xiaomi Dasheng系列模型做計算效率的升級 , 尋求終端設備上可離線部署 。
結語:小米音頻大模型再拱一卒 , 多模態能力拼圖日趨完善作為影響自然語言交互體驗的關鍵技術之一 , 小米Xiaomi Dasheng系列模型此次的升級 , 對其提升自家設備的AI交互體驗有一定幫助 , 從智能家居、智能汽車到智能手機 , 各類產品均能受益 。
【剛剛,小米又開源一大模型,22個公開測評SOTA】AI多模態是當下業界主攻的方向之一 , 小米重心轉向造車后 , 在AI大模型領域發聲并不多 , 小米未來在多模態領域能否帶來更多模型創新 , 值得期待 。
推薦閱讀















- 剛剛,谷歌「IMO金牌」模型上線Gemini,數學家第一時間證明猜想
- 小米電競手機再曝,165Hz高刷屏+9千大電池+玄戒新U?有點心動
- 華米OV新款大折疊集體曝光:小米、vivo規劃“闊折疊”
- 董明珠壓力大,小米空調,線上銷量只落后格力2%了
- 銷量大漲33.4%!華為、小米、小天才領跑中國智能腕戴市場
- 8月又一款新機官宣:8月7日,全新登場
- 小米全力投入澎湃OS 3系統研發:帶來更高流暢度與液體玻璃效果
- 時隔3年又要遙遙領先,華為Mate80系列多個重磅新技術曝光
- 曾經性價比絕殺小米的國產手機,蘋果一直在替它背黑鍋
- 8000大電池+2K直屏!最便宜的驍龍8至尊2代新機要秒小米16?