文章圖片

文章圖片
文章圖片
文章圖片
文章圖片

文章圖片

機器之心報道
編輯:杜偉、冷貓
計算機視覺領域的大部分下游任務都是從二維圖像理解(特征提?。 ┛嫉?。
在特征提取、語義理解、圖像分割等 CV 基本任務中的模型三幻神分別是 SAM、CLIP 和 DINO , 分別代表了全監督、弱監督和自監督三大數據訓練范式 。
【Meta視覺基座DINOv3王者歸來:自監督首次全面超越弱監督,商用開源】在人工智能領域 , 自監督學習(SSL)代表了 AI 模型無需人工監督即可自主學習 , 它已成為現代機器學習中的主流范式 。 自監督學習推動了大語言模型的崛起 , 通過在海量文本語料上的預訓練 , 獲得了通用表示能力 。
相比于需要標注數據的 SAM 模型和依賴圖像 - 文本對進行訓練的 CLIP 模型 , 基于自監督學習的 DINO 具備有直接從圖像本身生成學習信號的優勢 , 數據準備門檻更低 , 更容易實現更大規模的數據學習以達到更精細的圖像特征 , 泛化性更強 。
2021 年 , Meta 發布 DINO , 它基于 ViT 構建 , 在無需標注的情況下可以學習到語義分割、對象檢測等任務中高可用的特征 , 填補了 SAM 模型在計算機視覺下游任務的空白 。
2023 年 , DINOv2 發布并開源 , 是 DINO 模型的改進版本 。 它采用了更大規模的數據 , 強調訓練穩定性和通用性 , 支持線性分類、深度估計、圖像檢索等下游任務 , 效果逼近或超越弱監督方法 。
DINOv2 不僅被 Meta 用作 ImageBind 等多模態模型的視覺表征基礎 , 也在各類視覺相關研究工作中作為經典模型廣泛使用 。
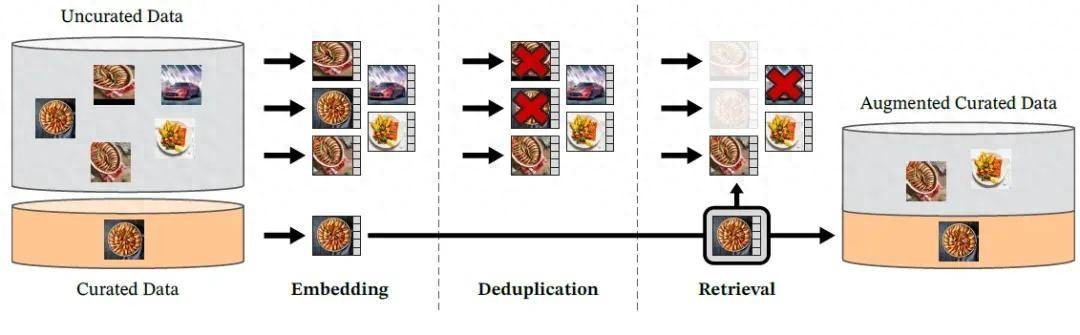
DINOv2 數據處理管線圖
雖然 DINOv2 已經存在兩年之久 , 它仍然是 CV 領域最優秀的前沿圖像模型之一 , 具有完善可擴展的 ViT 結構 , 但遺憾就遺憾在訓練數據量不夠大 , 在高分辨率圖像密集特征的任務中仍不夠理想 。
今天 , DINOv2 的兩大遺憾徹底被補足了 。 Meta 正式推出并開源了 DINOv3 , 一款通用的、SOTA 級的視覺基礎模型 , 同樣采用了自監督學習訓練 , 能夠生成更高質量的高分辨率視覺特征 。
DINOv3 首次實現:一個單一的凍結視覺骨干網絡在多個長期存在的密集預測任務(如目標檢測和語義分割)中超越了專業解決方案 。
DINOv3 取得突破性性能的核心在于其創新的自監督學習技術 , 這些技術徹底擺脫了對標注數據的依賴 , 大幅降低了訓練所需的時間與資源 , 使得訓練數據擴展至 17 億張圖像 , 模型參數規模擴展至 70 億 。 這種無標簽方法適用于標簽稀缺、標注成本高昂甚至不可能獲取標注的應用場景 。
從 DINO、DINO v2 到 DINOv3 。
Meta 表示 , 其正以商業許可方式開源 DINOv3 的一整套骨干網絡 , 其中包括基于 MAXAR 衛星圖像訓練的衛星圖像骨干網絡 。 同時 , Meta 還開放了部分下游任務的評估頭(task head) , 以便社區復現其結果并在此基礎上拓展研究 。 此外還提供了示例筆記本 , 幫助開發者快速上手 , 立即開始構建基于 DINOv3 的應用 。
對于 Meta 此次的新模型 , 網友調侃道 , 「我還以為 Meta 已經不行了 , 終于又搞出了點新東西 。 」
自監督學習模型的全新里程碑
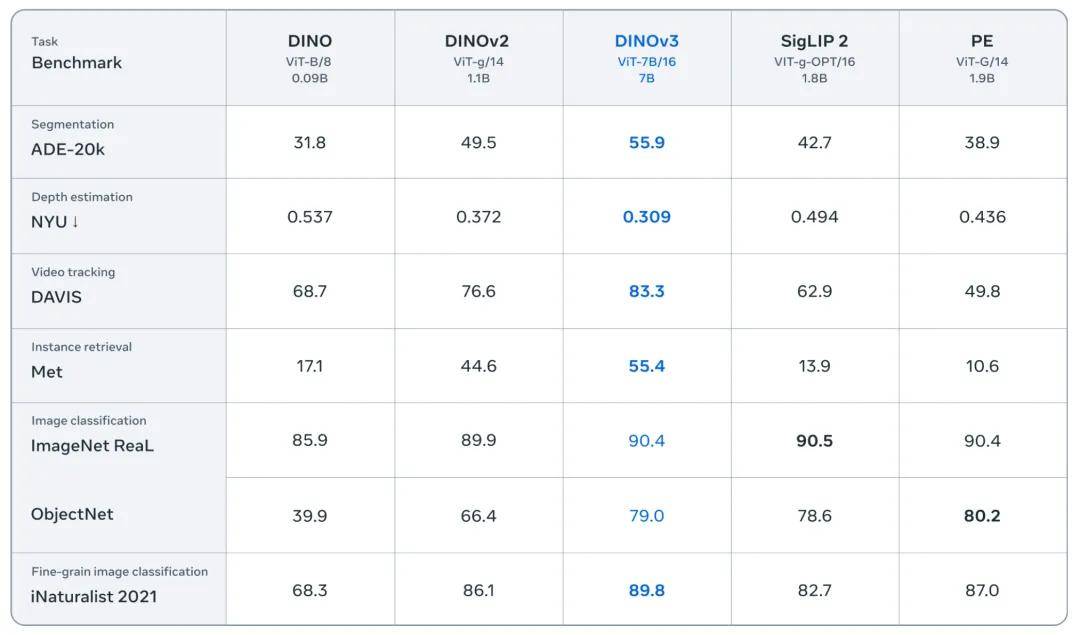
DINOv3 實現了一個新的里程碑:首次證明自監督學習(SSL)模型在廣泛任務上能夠超越弱監督模型 。 盡管前代 DINO 模型已在語義分割、單目深度估計等密集預測任務中取得顯著領先 , DINOv3 的表現更勝一籌 。
DINOv3 在多個圖像分類基準上達到了與最新強大模型(如 SigLIP 2 和 Perception Encoder)相當或更優的性能 , 同時在密集預測任務中顯著擴大了性能差距 。
DINOv3 基于突破性的 DINO 算法構建而成 , 無需任何元數據輸入 , 所需訓練計算量僅為以往方法的一小部分 , 卻依然能夠產出表現卓越的視覺基礎模型 。
DINOv3 中引入的一系列新改進 , 包括全新的 Gram Anchoring 策略 , 有效緩解了密集特征的坍縮問題 , 相比 DINOv2 擁有更出色、更加干凈的高分辨率密集特征圖;引入了旋轉位置編碼 RoPE , 避免了固定位置編碼的限制 , 能夠天然適應不同分辨率的輸入等 。
這些新的改進使其在多個高競爭性的下游任務中(如目標檢測)取得了當前 SOTA 性能 , 即使在「凍結權重」這一嚴苛限制條件下也是如此 。 這意味著研究人員和開發者無需對模型進行針對性的微調 , 從而大大提高了模型在更廣泛場景中的可用性和應用效率 。
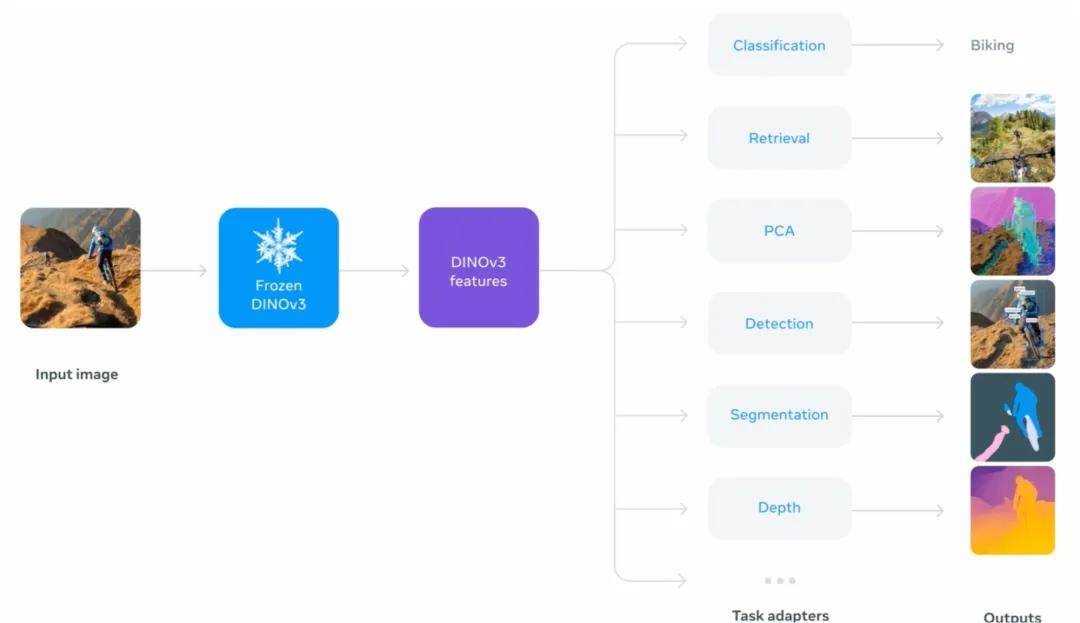
從數據整理(無標簽原始圖像、平衡的圖像數據)、預訓練(大規模自監督學習模型)、Gram Anchoring(改進的局部特征)、高分辨率微調(適用于高分辨率推理)和模型蒸餾(涵蓋多種模型規模) 。
DINOv3 作為通用視覺特征提取器的工作流程 , 以及它在不同下游任務中的應用方式 。
高分辨率、密集特征與高精度
DINOv3 的一大亮點 , 是相比于已有模型在高分辨率圖像以及密集圖像特征上的進步 , 顯著改善了 DINOv2 時期的痛點 。
比如說這張圖 , 是一張分辨率為 4096×4096 的水果攤圖像 。 要從這里找出某種特定的水果 , 就算是肉眼看都有點暈…
而 Meta 可視化了 DINOv3 輸出特征所生成的 余弦相似度圖 , 展示了圖像中某個被紅色叉標記的 patch 與所有其他 patch 之間的相似度關系 。
放大看看 , 是不是還挺準確的?
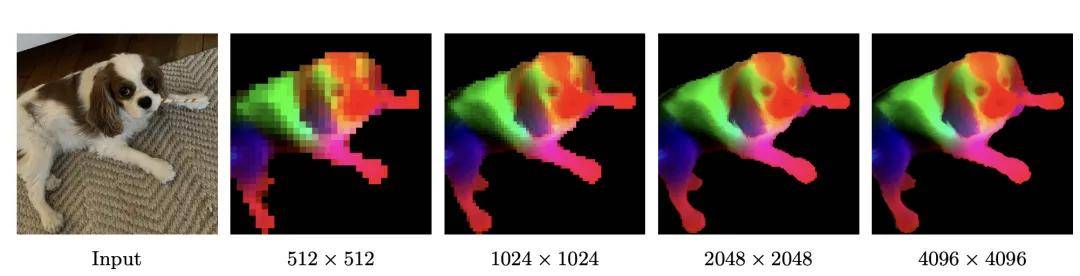
關于密集特征部分 , Meta 通過以下方式可視化 DINOv3 的密集特征:對其特征空間執行主成分分析(PCA) , 然后將前三個主成分映射為 RGB 顏色通道 。 為使 PCA 聚焦于主體區域 , Meta 對特征圖進行了背景剔除處理 。
隨著圖像分辨率的提升 , DINOv3 能夠生成清晰銳利且語義一致的特征圖 。
Meta 稱 , 盡管自監督學習出現較晚 , 但其發展迅速 , 如今已追趕上近年來 ImageNet 上的精度上限 。
可擴展、高效且無需微調
DINOv3 是在其前代 DINOv2 的基礎上構建的 , 模型規模擴大了 7 倍 , 訓練數據集擴大了 12 倍 。 為展現模型的通用性 , Meta 在 15 個不同的視覺任務和超過 60 個基準測試上進行了評估 。 DINOv3 的視覺骨干模型在所有密集預測任務中表現尤為出色 , 展現出對場景布局與物理結構的深刻理解能力 。
視頻目標分割與跟蹤評估結果
分割與跟蹤示例
模型輸出的豐富密集特征 , 能夠捕捉圖像中每一個像素的可量化屬性或特征 , 并以浮點數向量的形式表示 。 這些特征能夠將物體解析為更細粒度的組成部分 , 甚至能在不同實例和類別間進行泛化 。
憑借這種強大的密集表示能力 , Meta 可以在 DINOv3 上方僅用極少的標注訓練輕量化的適配器 —— 只需少量標注和一個線性模型 , 就能獲得穩健的密集預測結果 。
進一步地 , 結合更復雜的解碼器 , Meta 展示了:無需對骨干網絡進行微調 , 也能在長期存在的核心視覺任務上取得最先進的性能 , 包括目標檢測、語義分割和相對深度估計 。
由于在無需微調骨干網絡的前提下也能實現 SOTA(最先進)性能 , 單次前向傳播就可以同時服務多個任務 , 從而顯著降低推理成本 。 這一點對邊緣應用場景尤為關鍵 , 這些場景往往需要同時執行多項視覺預測任務 。
易于部署的系列模型
將 DINOv3 擴展至 70 億參數規模 , 展現了自監督學習(SSL)的全部潛力 。 然而 , 對于許多下游應用而言 , 70 億參數的模型并不現實 。 基于社區反饋 , Meta 構建了一個涵蓋不同推理計算需求的模型家族 , 以便支持研究人員和開發者在各種使用場景中進行部署 。
通過將 ViT-7B 模型進行蒸餾 , Meta 得到了一系列更小但性能依舊出色的模型變體 , 如 ViT-B 和 ViT-L , 使得 DINOv3 在多個評估任務中全面超越了同類的基于 CLIP 的模型 。
此外 , Meta 還推出了一系列蒸餾自 ViT-7B 的 ConvNeXt 架構模型(T、S、B、L 版本) , 它們能夠滿足不同的計算資源約束需求 。 與此同時 , Meta 也將完整的蒸餾流程管線開源 , 以便社區在此基礎上進一步開發與創新 。
Meta「改變世界」的嘗試
Meta 稱 , DINOv2 已經通過利用大量未標注數據 , 為組織在組織病理學、內窺鏡檢查和醫學影像等領域的診斷和研究工作提供支持 。
在衛星與航空影像領域 , 數據體量龐大且結構復雜 , 人工標注幾乎不可行 。 借助 DINOv3 , Meta 使這些高價值數據集能夠用于訓練統一的視覺骨干模型 , 進而可廣泛應用于環境監測、城市規劃和災害響應等領域 。
DINOv3 的通用性與高效性使其成為此類部署的理想選擇 —— 正如 NASA 噴氣推進實驗室(JPL)所展示的那樣 , 其已經在使用 DINOv2 構建火星探索機器人 , 實現多個視覺任務的輕量執行 。
DINOv3 已經開始在現實世界中產生實際影響 。 世界資源研究所(WRI)正在使用 DINOv3 分析衛星圖像 , 檢測森林損失和土地利用變化 。 DINOv3 帶來的精度提升使其能夠自動化氣候金融支付流程 , 通過更精確地驗證修復成果來降低交易成本、加速資金發放 , 特別是支持小型本地組織 。
例如 , 與 DINOv2 相比 , DINOv3 在使用衛星與航空影像進行訓練后 , 將肯尼亞某地區樹冠高度測量的平均誤差從 4.1 米降低至 1.2 米 。 這使得 WRI 能夠更高效地擴大對數千名農戶與自然保護項目的支持規模 。
想要了解更多 DINOv3 細節的讀者 , 請移步原論文 。
論文地址:https://ai.meta.com/research/publications/dinov3/ Hugging Face 地址:https://huggingface.co/docs/transformers/main/en/model_doc/dinov3 博客地址:https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
推薦閱讀















- 又是北大校友!ChatGPT Agent華人研發主力被Meta挖走了
- 扎克伯格看OpenAI直播挖人,北大校友孫之清加入Meta
- OPPO聯手視覺健康全國重點實驗室,為屏幕護眼引入醫學級標準
- 全球AI眼鏡出貨量增長110%,Meta占據70%以上
- 是福爾摩斯,也是列文虎克,智譜把OpenAI藏著的視覺推理能力開源了
- 蘋果Siri王炸新功能曝出,AI操控一切App,又一華人AI研發跳槽Meta
- 榮耀 AiMAGE: 從MWC亮相到圖形商標落槌,AI 影像時代的視覺圖騰
- Meta高調公布旗艦原型機,VR設備有望通過“視覺圖靈測試”?
- Meta試點將重型木結構引入數據中心建造
- Cohere發布企業視覺模型Command A Vision