
文章圖片
劉鋒林 , 中科院計算所泛在計算系統研究中心博士研究生(導師:高林研究員) , 研究方向為計算機圖形學與生成式人工智能 , 在ACM SIGGRAPH\\TOG , IEEE TPAMI , IEEE TVCG , IEEE CVPR等期刊會議上發表論文10余篇 , 其中5篇為第一作者發表于SIGGRAPH和CVPR , 4篇論文收錄于中科院一區期刊ACM Transaction on Graphics , 第一作者研究工作連續兩年入選SIGGRAPH亮點工作宣傳片(Video Trailer) 。 曾獲得國家獎學金、中國計算機學會CADCG凌迪圖形學獎學金等榮譽 。
隨著移動攝影設備的普及 , 基于手機或相機等可以快速獲取帶有豐富視角變換的三維場景視頻 。 如何高效、自由地編輯這些三維內容成為一個關鍵挑戰 。 例如 , 在視頻中無縫添加新物體、精準去除不需要的元素 , 或者自然替換已有部分 , 這些能力在虛擬現實 (VR)、增強現實 (AR) 以及短視頻創作中具有廣泛的應用前景 。
然而 , 現有的經典方法 , 通常只能添加預定義的三維模型庫中的物體 , 極大地限制了用戶的個性化創意表達 。 更關鍵的是 , 讓新加入的物體融入原有場景的光影環境 , 生成逼真的陰影 , 以達到照片級的真實感 , 是具有挑戰性的難題 。 同樣 , 移除物體后 , 如何合理地填補空缺區域并生成視覺連貫合理的內容 , 也需要更優的解決方案 。
近期 , 研究人員提出了一種基于線稿的三維場景視頻編輯方法 Sketch3DVE [1
, 相關技術論文發表于 SIGGRAPH 2025 , 并入選 Video Trailer 。 它賦予用戶基于簡單線稿即可重塑三維場景視頻的能力 。 無論是為視頻場景個性化地添加全新物體 , 還是精細地移除或替換已有對象 , 用戶都能通過繪制關鍵線稿輕松實現 。
論文標題:Sketch3DVE: Sketch-based 3D-Aware Scene Video Editing 論文地址:https://dl.acm.org/doi/10.1145/3721238.3730623 項目主頁:http://geometrylearning.com/Sketch3DVE/ Github:https://github.com/IGLICT/Sketch3DVE
此外 , 即使是單張靜態圖片 , 用戶也能自由規劃虛擬相機路徑(指定相機軌跡) , 首先生成具有視角變化的動態視頻 , 隨后再進行任意編輯 。
現在 , 就讓我們一同探索 Sketch3DVE 如何將簡單的線稿筆畫 , 轉化為重塑三維世界的鑰匙!
圖 1 基于線稿的三維場景視頻編輯結果
圖 2 視角可控的視頻生成及編輯結果
Part 1 背景
近年來 , 視頻生成基礎模型(如 Sora、Kling、Hunyuan Video、CogVideoX 和 Wan 2.1 等)在文本到視頻和圖像到視頻生成方面取得了顯著進展 。 精確控制生成視頻中的相機軌跡因其重要的應用前景而受到廣泛關注 。
現有方法主要分為兩類:一類工作 [2 3
直接將相機參數作為模型輸入 , 利用注意力機制或 ControlNet 結構來實現對生成視頻視角的控制;另一類工作 [4 5
則從單張輸入圖像構建顯式的三維表示(如 NeRF) , 通過指定相機軌跡渲染出新視角圖像 , 并以此作為控制信號引導視頻生成 。
盡管這些方法能夠生成視角可控的視頻 , 如何對已存在的、包含大幅度相機運動的真實視頻進行精確編輯 , 仍然是一個有待解決的研究問題 。
視頻編輯任務與視頻生成有本質區別 , 它需要保持原始視頻的運動模式與局部特征 , 同時根據用戶指令合成新的內容 。 早期的視頻編輯方法 [6 7
通常基于 Stable Diffusion 等圖像擴散模型 , 對視頻幀進行逐幀處理 , 并通過引入時序一致性約束來生成編輯結果 。
進一步地 , 研究者開始利用視頻生成模型進行編輯 , 例如一些方法 [8
從輸入視頻中提取注意力特征圖以編碼運動信息 , 另一些方法 [9
則采用 LoRA 對預訓練視頻模型進行微調以捕捉特定視頻的運動模式 。 然而 , 這些方法主要擅長外觀層面的編輯(如風格化、紋理修改) , 在幾何結構層面的編輯效果較差 , 并且難以有效處理包含大幅度相機運動的場景 。
線稿(Sketch)作為一種直觀的用戶交互方式 , 已被廣泛應用于圖像、視頻和三維內容的生成與編輯中 。 基于線稿的視頻編輯方法也已出現 , 例如 VIRES [10
通過優化 ControlNet [11
結構實現了基于線稿引導的視頻重繪 , 而 SketchVideo [12
則設計了一種關鍵幀線稿傳播機制 , 允許用戶僅提供少量?。 ?-2 ?。 ┑南吒寮純殺嗉鍪悠?。
盡管如此 , 現有的基于線稿的視頻編輯方法主要面向通用場景 。 如何處理包含顯著相機視角變化的視頻 , 并在編輯過程中保持新內容的三維幾何一致性 , 仍是當前研究面臨的關鍵挑戰 。
Part 2 算法原理
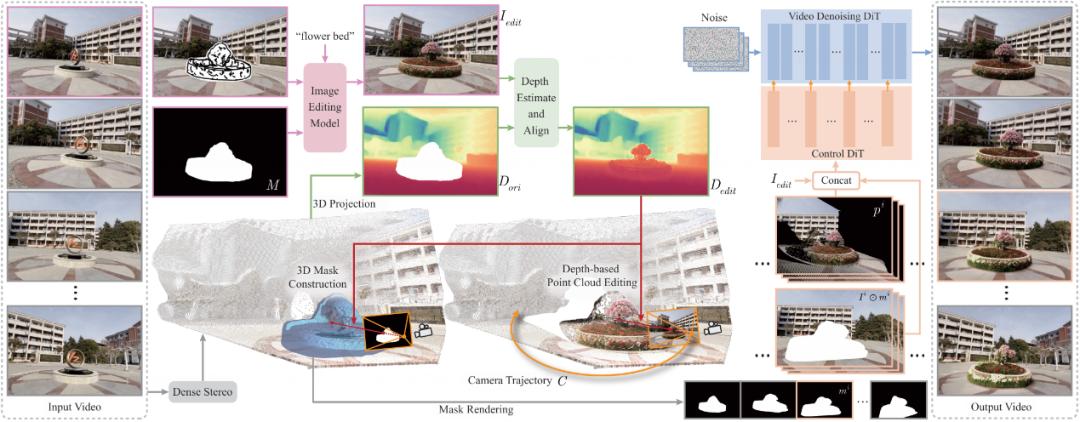
圖 3 Sketch3DVE 的編輯流程和網絡架構圖
給定輸入的三維場景視頻后 , 用戶首先選定第一幀圖像 。 在該幀上 , 用戶繪制一個掩碼(Mask)標記需要編輯的區域 , 并繪制線稿(Sketch)來指定新物體的幾何形狀 。
同時 , 用戶輸入文本描述來定義新物體的外觀特征 。 系統采用 MagicQuill [13
圖像編輯算法(或其他兼容的基于圖像補全的編輯方法)處理第一幀 , 生成該幀的編輯結果 。
隨后 , 系統利用 DUSt3R [14
三維重建算法處理整個輸入視頻 , 對場景進行三維分析 。 該方法輸出第一幀對應的場景點云(Point Cloud)以及每一幀對應的相機參數(Camera Parameters) , 為后續的視頻編輯傳播提供幾何基礎 。
接下來 , 需要將第一幀圖像上的編輯操作傳播到其對應的三維點云上 。 系統采用基于深度圖的點云編輯方法:首先 , 使用 DUSt3R 或 DepthAnything [15
等方法預測編輯后第一幀圖像的深度圖(Depth Map) 。 由于預測得到的是相對深度值 , 需要將其與原始場景的尺度對齊 。
為此 , 系統利用掩碼外部(非編輯區域)的像素 , 通過逐像素的對應關系計算深度值的平移和縮放參數 。 應用這些參數對預測深度圖進行變換 , 并將編輯區域的深度值融合到原始場景的深度圖中 。 最后 , 通過反投影(Back-projection)處理融合后的深度圖 , 得到編輯后的三維點云 。
為了減少用戶交互 , 掩碼只需在第一幀繪制 。 為了將第一幀的掩碼精確傳播到后續不同視角的幀上 , 系統設計了一個基于三維感知的掩碼傳播算法 。
該算法在三維空間中構建一個網格模型來表示三維掩碼(3D Mask):利用編輯前后幀提供的深度信息和相機參數 , 將每個像素位置反投影到三維空間 , 形成網格頂點;根據像素鄰域關系連接這些頂點 , 構建出表示編輯區域前表面的網格面片;后表面則使用平面結構并通過側面連接 , 最終形成一個封閉的三維網格模型 。 該三維掩碼模型可根據不同幀的相機參數渲染出對應的二維掩碼 。
最后 , 系統構建了一個基于三維點云引導的視頻生成模型 , 其思路類似于 [11 12
。 該模型在預訓練的 CogVideoX 模型基礎上 , 額外引入了一個條件控制網絡 。
該網絡以三種信息作為輸入引導視頻生成:1) 編輯后的第一幀圖像;2) 由編輯后點云渲染得到的多視角視頻(提供三維幾何一致性約束);3) 原始輸入視頻(但移除了掩碼區域的內容 , 用于保持非編輯區域的時空一致性) 。 通過融合這些條件信息 , 模型最終輸出具有精確三維一致性的場景編輯視頻 。
Part 3 效果展示
如圖 4 所示 , 用戶可以在首幀繪制線稿并標記編輯區域 , 該方法可以生成高質量的三維場景視頻編輯結果 , 實現物體的添加、刪除和替換等操作 , 所生成新的物體具有良好的三維一致性 。
圖 4 基于線稿的三維場景視頻編輯結果
如圖 5 所示 , 當視頻中存在陰影和反射等較為復雜的情景時 , 由于該工作使用了真實視頻作為數據集進行訓練 , 也能在一定程度處理上述情況 , 并生成相對合理的視頻編輯結果 。
圖 5 陰影和反射等情況的場景編輯效果
如圖 6 所示 , 給定真實拍攝的三維場景視頻后 , 用戶可以標記指定編輯區域 , 并繪制顏色筆畫指定新生成內容的外觀 。 該工作可以生成較為真實自然的三維場景視頻編輯結果 。
圖 6 基于顏色筆畫的三維場景視頻編輯結果
如圖 7 所示 , 該工作也支持不以線稿作為輸入 , 而直接使用圖像補全方法對首幀進行編輯 , 相關編輯效果也可以合理應用至三維場景 。
圖 7 基于圖像補全方法的三維場景視頻編輯結果
Part 4 結語
隨著大模型和生成式人工智能的迅速發展 , 三維場景視頻編輯問題也有了新的解決范式 。 傳統的模型插入方法存在難以個性化定制、渲染結果不夠真實、無法去除已有物體等問題 。
Sketch3DVE 則提出了一種有效的解決方案 , 通過線稿定制化生成三維物體 , 合成高真實感的三維場景視頻編輯效果 , 并支持基于單目圖像的三維視頻合成和二次編輯 。
借助該方法 , 用戶無需掌握復雜的專業三維處理和視頻處理軟件 , 也無需投入大量時間和精力 , 僅憑幾筆簡單的線稿勾勒 , 便可以將想象中的物體帶到現實 , 構建出靈感和現實的橋梁 。 該項工作已經發表在SIGGRAPH 2025 。
有關論文的更多細節 , 及論文、視頻、代碼的下載 , 請瀏覽項目主頁 。
參考文獻:
[1
Feng-Lin Liu Shi-Yang Li Yan-Pei Cao Hongbo Fu Lin Gao*. “Sketch3DVE: Sketch-based 3D-Aware Scene Video Editing.” In ACM SIGGRAPH. 2025.
[2
Zhouxia Wang Ziyang Yuan Xintao Wang Yaowei Li Tianshui Chen Menghan Xia Ping Luo and Ying Shan. MotionCtrl: A Unified and Flexible Motion Controller for Video Generation. In ACM SIGGRAPH. 2024.
[3
Yuelei Wang Jian Zhang Peng-Tao Jiang Hao Zhang Jinwei Chen and Bo Li. 2024c. CPA: Camera-pose-awareness Diffusion Transformer for Video Generation. CoRR abs/2412.01429 (2024).
[4
Wangbo Yu Jinbo Xing Li Yuan Wenbo Hu Xiaoyu Li Zhipeng Huang Xiangjun Gao Tien-Tsin Wong Ying Shan and Yonghong Tian. 2024. ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis. CoRR abs/2409.02048 (2024).
[5
Zekai Gu Rui Yan Jiahao Lu Peng Li Zhiyang Dou Chenyang Si Zhen Dong Qifeng Liu Cheng Lin Ziwei Liu Wenping Wang and Yuan Liu. 2025. Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control. CoRR abs/2501.03847 (2025).
[6
Shaoteng Liu Yuechen Zhang Wenbo Li Zhe Lin and Jiaya Jia. Video-P2P: Video Editing with Cross-Attention Control. In IEEE CVPR 2024. 8599–8608.
[7
Shuai Yang Yifan Zhou Ziwei Liu and Chen Change Loy. Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation. In ACM SIGGRAPH 2023. 95:1–95:11.
[8
Max Ku Cong Wei Weiming RenHarry Yang and Wenhu Chen.2024. AnyV2V: A Plug and-Play Framework For Any Video-to-Video Editing Tasks. CoRR abs/2403.14468 (2024). [9
Wenqi Ouyang Yi Dong Lei Yang Jianlou Si and Xingang Pan. 2024a. I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models. In ACM SIGGRAPH Asia Takeo Igarashi Ariel Shamir and Hao (Richard) Zhang (Eds.). 95:1–95:11.
[10
Shuchen Weng Haojie Zheng Peixuan Zhang Yuchen Hong Han Jiang Si Li and Boxin Shi. VIRES: Video Instance Repainting with Sketch and Text Guidance. IEEE CVPR 2024.
[11
Zhang Lvmin Anyi Rao and Maneesh Agrawala. \"Adding conditional control to text-to-image diffusion models.\" ICCV 2023.
[12
Feng-Lin Liu Hongbo Fu Xintao Wang Weicai Ye Pengfei Wan Di Zhang Lin Gao*. “SketchVideo: Sketch-based Video Generation and Editing.” IEEE CVPR 2025
[13
Zichen Liu Yue Yu Hao Ouyang Qiuyu Wang Ka Leong Cheng Wen Wang Zhiheng Liu Qifeng Chen and Yujun Shen. 2024d. MagicQuill: An Intelligent Interactive Image Editing System. CoRR abs/2411.09703 (2024).
[14
Shuzhe Wang Vincent Leroy Yohann Cabon Boris Chidlovskii and Jér?me Revaud. DUSt3R: Geometric 3D Vision Made Easy. In IEEE CVPR 2024. 20697–20709.
【妙筆生維:線稿驅動的三維場景視頻自由編輯】[15
Lihe Yang Bingyi Kang Zilong Huang Zhen Zhao Xiaogang Xu Jiashi Feng and Hengshuang Zhao. 2024b. Depth Anything V2. CoRR abs/2406.09414 (2024).
推薦閱讀















- iQOO Neo10系列線稿圖突然曝光:鏡頭小改+配置清晰,12月發布
- 健美生維生素c,健美生維生素c作用
- 健美生維生素a作用,維生素a作用
- 吃健美生維生素c有什么作用,健美生維生素c可以美白嗎 健美生維生素c是早上吃嗎
- ps怎么提取線稿
- 如何用ps將圖片改為線稿
- 如何用ps制作手繪線稿圖
- cad怎么把圖片變成線稿
- 愛普生維修程序中文版 愛普生維修模式怎么退出
- 線稿顏色淡怎么加深 線稿怎么刷出顏色