
文章圖片
文章圖片
DeepSeek終于發布新版本了!
雖然不是大家期待的V4或者R2 , 但這個3.1的版本 , 仍然帶來了一些小驚喜 。
我們來簡要總結下 , 這個DeepSeek V3.1都有哪些更新↓
1. 混合推理架構一個模型同時支持 思考模式(Think)與 非思考模式(Chat) 。 用戶可在官方 App/網頁端自由切換“深度思考”按鈕 。
當然這不是DeepSeek首創 , 今年4月阿里Qwen3發布的時候 , 就濃墨重彩的宣傳了一下這種架構 。
我們還寫了一個科普:漫畫趣解:什么是混合推理模型?有啥好處?
2. 更高的思考效率相比 DeepSeek-R1-0528 , V3.1-Think速度更快 , 能在更短時間內給出答案 。
DeepSeek通過「思維鏈壓縮訓練」 , 在 減少20%-50% token輸出的情況下 , 性能與0528持平 。
說白了 , 就是去掉無效推理、合并推理步驟、保留關鍵邏輯 , 但干貨質量不變 , 少浪費token 。
另外 , 素輸出也做了優化 , 廢話更少了 , 非思考模式下 , 輸出長度得到有效控制 , 相比V3更精簡 , 性能保持不變 。
3. 更強的Agent能力現在智能體概念太火 , DeepSeek當然不想錯過 。
經過Post-Training優化 , V3.1在工具調用與 智能體任務中表現提升明顯 。
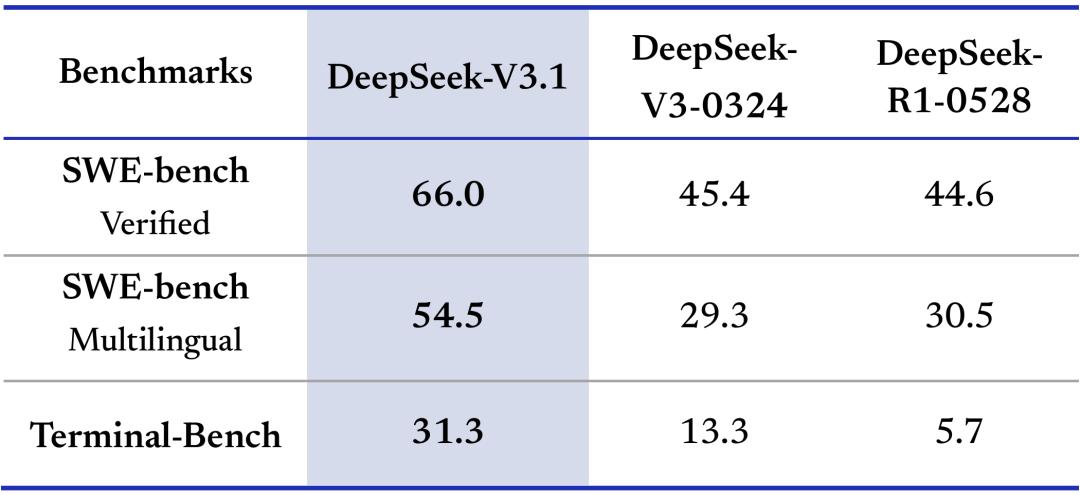
編程智能體:在SWE、Terminal-Bench 測評中 , 修復和復雜終端任務能力顯著增強 。 (能跟Claude叫板么)
搜索智能體:在browsecomp、HLE等復雜搜索與跨學科難題測試上性能大幅提升 。
4. API功能升級【DeepSeek終于還是沒憋住!】API 區分「非思考模式」和「思考模式」 , 支持128K上下文窗口 。
同時增加了對Anthropic API 格式的支持 , 可接入Claude Code框架(好消息) 。
5. 開源與訓練更新V3.1的Base模型在V3的基礎上重新做了外擴訓練 , 一共增加訓練了840B tokens 。
Base 模型與后訓練模型均已在 Huggingface 與魔搭開源 。
特別重要的一點是這一版的DeepSeek調整了分詞器與chat template , 這意味著如果需要做模型微調 , 需要對齊新的分詞器 , API調用也需要更新chat template 。
另外官方特別說明 , 模型采用了UE8M0 FP8 Scale 參數精度 , 比V3更進了一步:參數、激活在訓練與推理中大規模切換到FP8 , 通過動態scale避免溢出/精度損失 。
這真是N記H卡B卡的舒適區 , 菊卡就很難辦 。
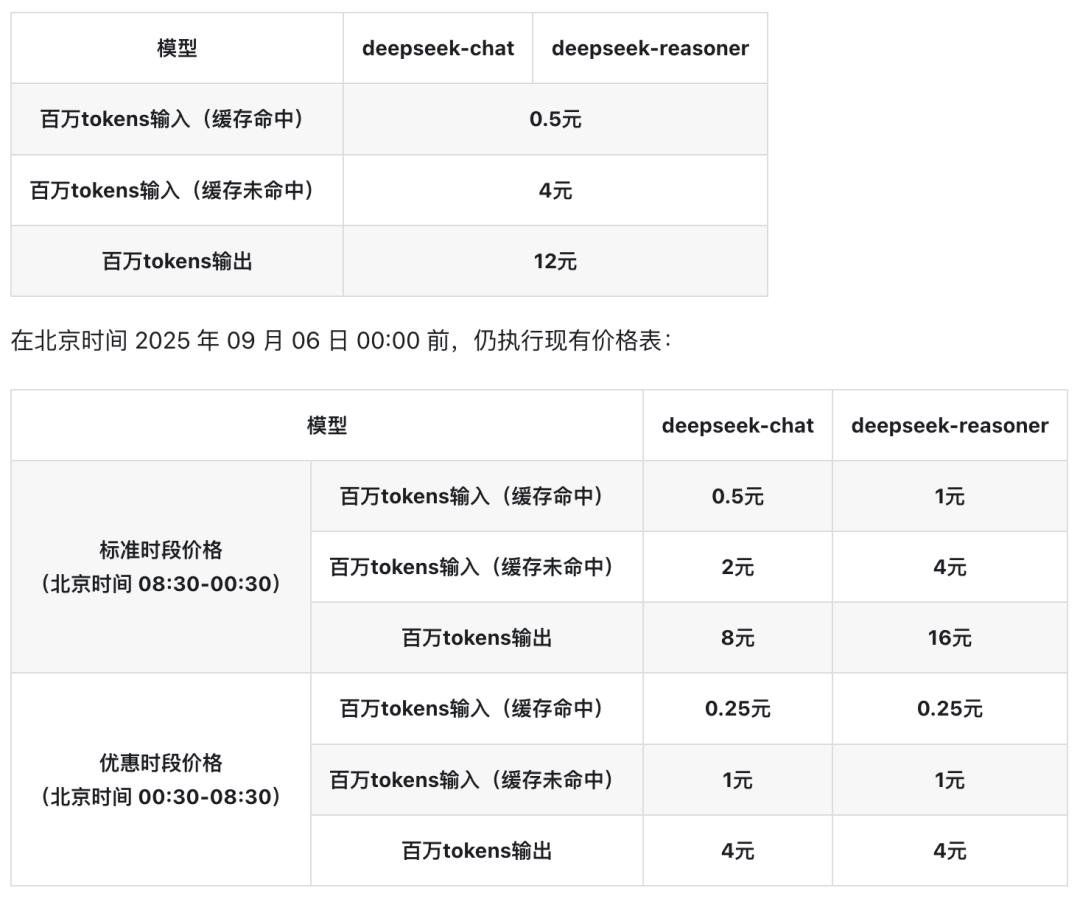
6. 價格調整 , 取消優惠2025年9月6日凌晨起 , 啟用新價格表 , 夜間優惠沒了 , 晝夜同價 。
遺憾的是 , V4還沒來 , R2還沒來 。
而且 , 這一版本仍然偏重文本(Chat、Reasoning、Agent) ,
在多模態交互、應用場景拓展上 , DeepSeek 還沒跟上 。
生態與工具鏈成熟度也差點火候 , 雖然增加了Function Calling+Agent優化 , 但生態仍然有限 。
另外通過「思維鏈壓縮」達到高效推理是一種相對激進的方案 , 如果面對“復雜推理+工具協同”場景時 , 可能會大腦短路 。
而這個場景 , 恰恰是Agentic AI的重度需求 。
目前 , DeepSeek官方網頁端、App、小程序及 API 開放平臺所調用模型均已同步更新 。
大家趕緊去試起來吧!
推薦閱讀













- 三個月、零基礎手搓一塊TPU,能推理能訓練,還是開源的
- 2025 年《財富》中國科技50強榜單揭曉: 華為登頂,Deepseek第二
- 為什么DeepSeek從年初“國運級”到現在熱度減退,問題出在哪里?
- Pura80、Mate70、nova14全系降價,買早還是買晚才是真贏家?
- iPhone 17 Pro Max充電速度曝光:蘋果終于要起飛了?
- 華為降價后選Mate還是Pura?這三款閉眼入型號說清楚
- iPhone17 Pro Max真機首曝!橫向大矩陣相機設計,愛還是嫌丑?
- 榮耀還是妥協了,256GB+6600mAh+一億像素,國補后跌至1265元
- 美國要慌了?Deepseek,全面適配國產AI芯片了
- 不追求極致性能的紅米,還是好紅米嗎?