
文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片

henry 發自 凹非寺
量子位 | 公眾號 QbitAI
AI自動生成的蘋果芯片Metal內核 , 比官方的還要好?
Gimlet Labs的最新研究顯示 , 在蘋果設備上 , AI不僅能自動生成Metal內核 , 還較基線內核實現了87%的PyTorch推理速度提升 。
更驚人的是 , AI生成的Metal內核還在測試的215個PyTorch模塊上實現了平均1.87倍的加速 , 其中一些工作負載甚至比基準快了數百倍 。
真就AI Make蘋果AI Great Again?
用AI為蘋果設備生成內核先說結論:通過AI自動實現內核優化 , 可以在無需修改用戶代碼、無需新框架或移植的情況下 , 顯著提升模型性能 。
為了證明這一點 , 研究人員選取了來自Anthropic、DeepSeek和OpenAI的8個頂尖模型 , 讓它們為蘋果設備生成優化的GPU內核 , 以加速PyTorch推理速度 。
至于為什么是蘋果?別問——問就全球最大硬件供應商(doge)
接下來 , 讓我們看看研究人員是怎么做的:
實驗設置首先 , 在模型選擇方面 , 參與測試的模型包括:claude-sonnet-4、claude-opus-4;gpt-4o、gpt-4.1、gpt-5、o3;deepseek-v3、deepseek-r1 。
其次 , 在測試輸入方面 , 研究使用了KernelBench數據集中定義的PyTorch模塊 , 并選取了其中215個模塊進行測試 。
這些被選取的模塊被劃分為三個等級 , 分別是第一級的簡單操作(如矩陣乘法、卷積);第二級是由第一級操作組成的多操作序列;第三級是完整的模型架構(如 AlexNet、VGG) 。
再次 , 在評估指標方面 , 研究人員主要關注兩個指標:一是AI生成內核的正確性 , 二是其相較于基準PyTorch的性能提升 。
最后 , 研究使用的蘋果硬件為Mac Studio (Apple M4 Max chip) , Baseline為PyTorch eager mode(劃重點 , 一會要考)
實驗測試在上述準備完畢后 , 研究團隊展開了測試 。
測試流程如下:
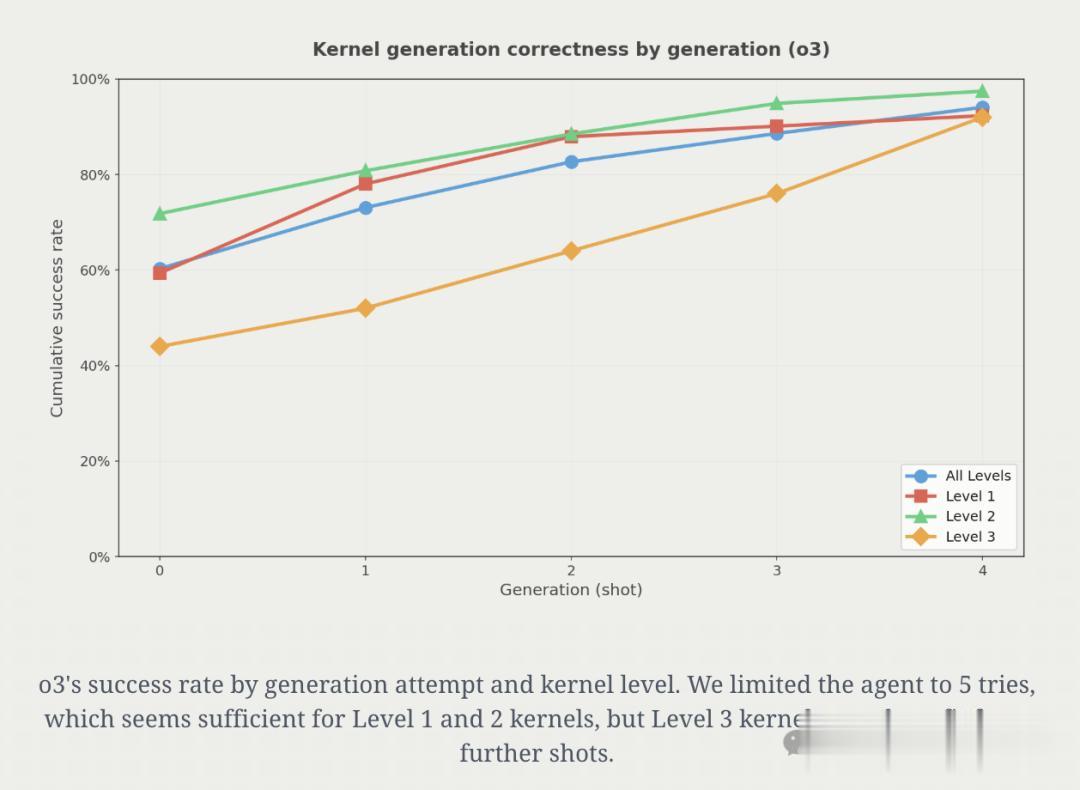
接收提示(prompt)和PyTorch代碼; 生成 Metal 內核; 評估其是否在正確性(correctness^4)上與基準PyTorch一致; 如果編譯失敗或不正確 , 則將錯誤信息回傳給智能體重試 , 最多允許重試5次 。【AI生成蘋果Metal內核,PyTorch推理速度提升87%】如上所說 , 研究者首先關注AI生成內核的正確性 。
實驗表明 , 正確性會隨著嘗試次數的增加而提升 。 以o3為例:第一次嘗試就有約60%的概率得到可用實現 , 到第5次嘗試時可用實現比例達到94% 。
此外 , 研究還發現推理模型非常擅長跨層級生成正確的內核 , 盡管非推理模型有時也能做到這一點 。
那么 , AI生成的內核表現如何呢?
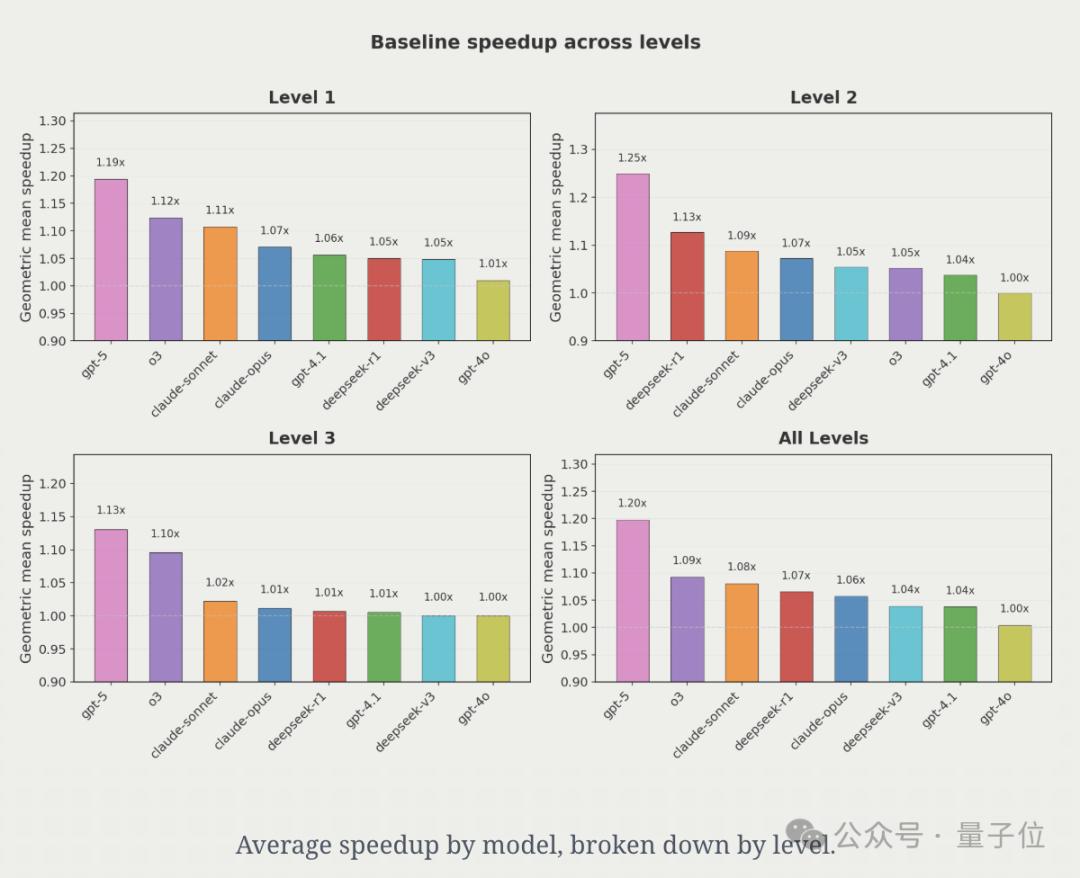
實驗結果相當驚艷 , 幾乎每個模型都生成了一些比基準更快的內核 。
例如 , GPT-5在一個Mamba 25狀態空間模型上實現了4.65倍的加速 , 其主要通過內核融合(kernel fusion) 來減少內核調用的開銷 , 并改善內存訪問模式 。
在一些案例中 , o3甚至將延遲提升了超過9000倍!
總體而言 , GPT-5平均可以帶來約20%的加速 , 其他模型則落后 。
不過 , GPT并非是門門最優 , 研究人員發現GPT-5在34%的問題上生成了最優解 。
但在另外30%的問題上 , 其他模型生成的解比GPT-5更優!
這就意味著沒有單一模型能在所有問題上都生成最優內核 。
因此 , 如果把多個模型組合起來 , 就能更大概率生成最優內核 。
于是乎 , 研究人員又展開了智能體群體實驗(Agentic Swarm) 。
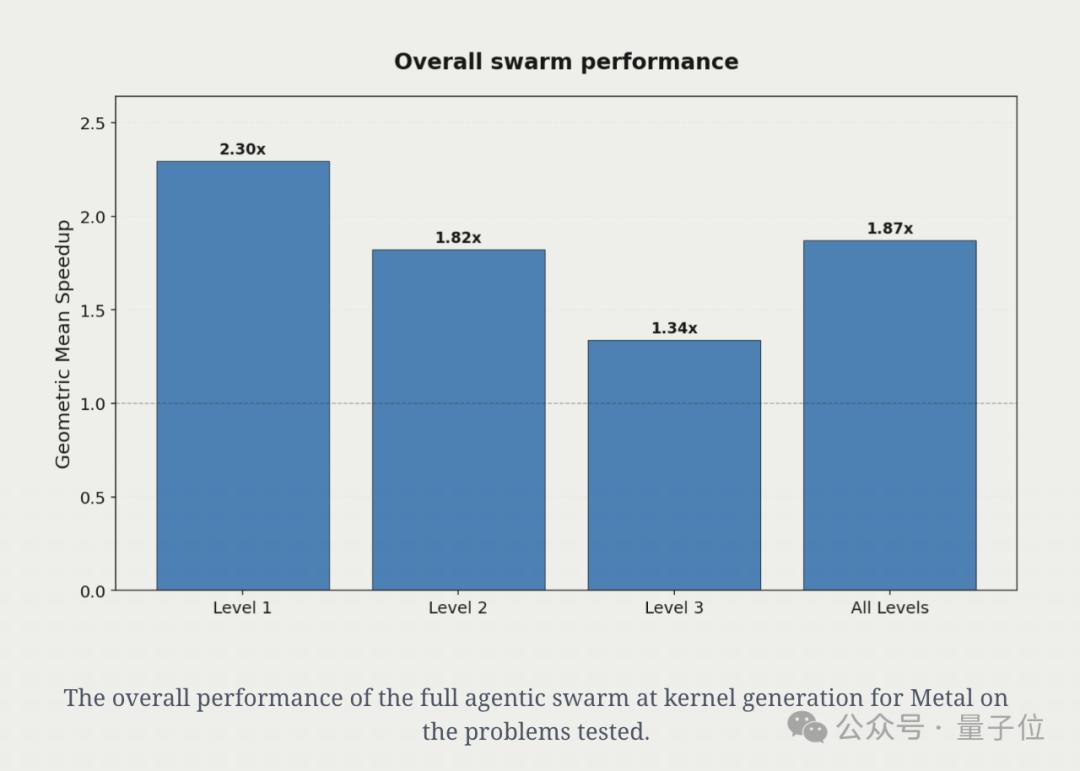
智能體群體實驗果不其然 , 相較于單個模型 , 智能體群體策略實現了更高的性能提升 。
與GPT-5相比 , 智能體群體在各層級平均加速31% , 在Level 2問題上加速42% 。
在幾乎沒有上下文信息的情況下(僅有輸入問題和提示) , 智能體群體就已經表現得相當不錯 。
接下來 , 研究人員嘗試為智能體提供更多上下文 , 以獲取更快的內核 。
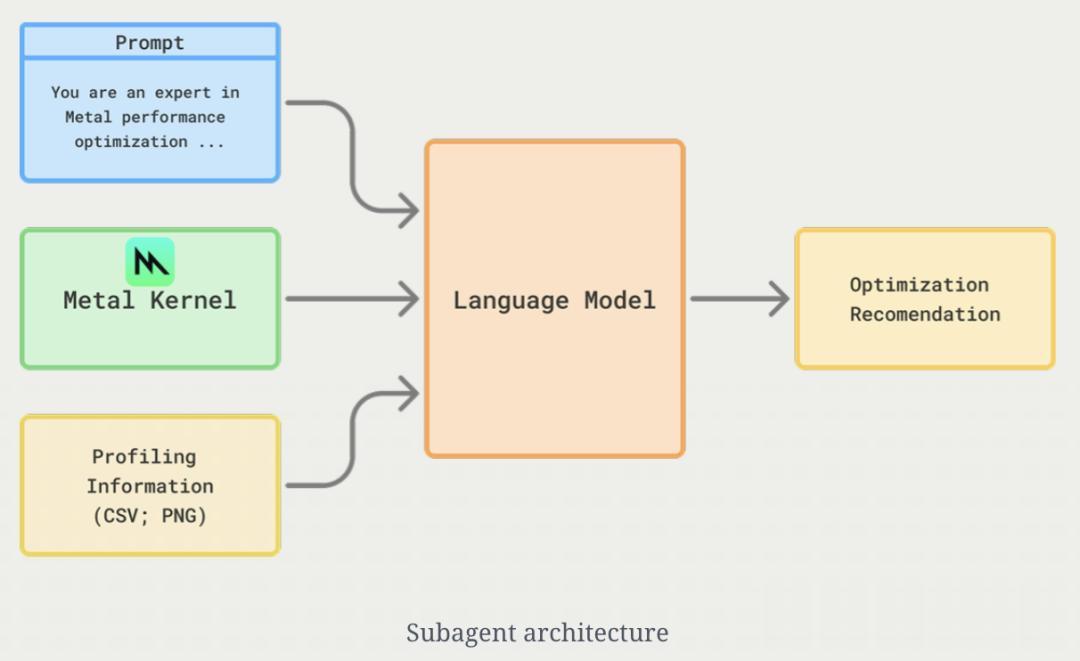
這里主要包含兩個額外的信息來源:
CUDA實現(由于 Nvidia GPU的普及 , 通常可以獲得優化過的CUDA參考實現); M4上gputrace 的性能分析信息 。 (包含Apple Script捕獲的gputrace摘要、內存和時間線視圖)
在具體的實施步驟中 , 研究者先將截圖處理任務分配給一個子智能體(subagent) , 讓它為主模型提供性能優化提示 。
在收到提示后 , 主智能體先進行一次初步實現 , 然后對其進行性能分析和計時 。
隨后 , 再將截圖傳給子智能體以生成性能優化提示 。
實驗表明 , 在上下文配置方面也沒有所謂的“單一最佳”方案 。
不過 , 在具體的性能加速方面 , 加入這些額外上下文實現了平均1.87倍的加速 , 相較于普通智能體僅實現的1.31倍的平均加速 , 額外上下文將提升幅度提高了三倍!
有提升 , 但看跟誰比為了更深入地討論 , 我們有必要先回顧一些背景知識 。
在PyTorch中 , 我們通常會調用如Sequential、ReLU這樣的函數 。
在具體的執行中 , PyTorch會先將函數拆解為張量運算(矩陣乘法、加法等) , 再交給GPU執行 。
這時就需要GPU內核(kernel)負責把這些數學操作轉成GPU可理解的低級并行指令 。
因此 , 在某種程度上 , 我們可以說GPU內核就像C編譯器一樣 , 其性能對于運算效率至關重要 。
而上面這篇工作所做的 , 就是讓原本必須由工程師手寫的內核優化交給AI自動完成 , 并測試它的性能 。
不過 , 問題就來了 。
眾所周知 , 蘋果硬件并不像英偉達的CUDA一樣 , 對PyTorch有很好的優化 。
因此 , 這篇研究直接拿MPS后端原生實現和AI生成的內核對比是有失公允的 。
不少眼尖的網友也是發現并指出了這一點:文章里所用的baseline是eager mode , 這通常只用于訓練調試或指標計算 , 不會被真正部署到設備上 。
在真實部署中 , 一般會先把模型導出為ONNX , 再編譯成設備原生格式(Metal、CUDA 或 ROCm 等) , 這樣效率會比直接用PyTorch eager mode高很多 。
所以 , 無論內核是工程師手寫 , 還是AI自動生成 , 經過優化的GPU內核都會比未優化的PyTorch推理快得多 。
因此 , 拿調試過的內核和eager比 , 多少有點奇怪 。
對此 , 研究人員回應道:
這篇工作不是為了展示部署環境的最終性能極限 , 而是展示AI自動生成內核的可行性 。
研究的目的是在內核工程方面獲得人類專家一定程度的效益 , 而無需開發人員的額外投入 , 希望通過A將部分流程自動化 。
所以 , 重點不在于性能提升 , 而在原型驗證 。
對此 , 你怎么看?
參考鏈接
[1
https://gimletlabs.ai/blog/ai-generated-metal-kernels#user-content-fn-4
[2
https://news.ycombinator.com/item?id=45118111
[3
https://en.wikipedia.org/wiki/Compute_kernel
[4
https://github.com/ScalingIntelligence/KernelBench/
— 完 —
量子位 QbitAI · 頭條號簽約
關注我們 , 第一時間獲知前沿科技動態
推薦閱讀















- 蘋果推送iOS 26 Beta 9,正式版發布時間與回歸指南
- 三星三大王炸:三折疊手機緊追華為,XR頭顯硬剛蘋果,AI眼鏡大招來了
- 蘋果首款折疊屏iPad:你準備好為三萬塊的未來買單了嗎?
- 實體SIM卡再見!中國聯通確認,對蘋果eSIM進行業務支撐!
- 當全世界向云端大模型狂奔,蘋果選擇回歸設備
- 蘋果也開始做折疊屏,除了屏大它究竟好在哪兒?
- AI搜索引擎,蘋果決定自研!代號WKA
- 領先蘋果 有望國內首發eSIM!華為三折疊Mate XTs今日發布 定價有驚喜
- 2025年蘋果秋季發布會看點前瞻,iPhone17系列攜10款重磅產品來襲
- 12999 元起?蘋果新品來了,新設計提前曝光