Claude不讓我們用!國產平替能頂上嗎?

文章圖片

文章圖片
文章圖片

文章圖片

文章圖片
機器之心報道
作者:冷貓、杜偉
這幾天 , 全球 AI 代碼生成的競爭格局 , 迎來了新的拐點 。
【Claude不讓我們用!國產平替能頂上嗎?】在編程領域 , 曾被視為王者的 Anthropic , 似乎正在一步步失去昔日的鋒芒 , 地位開始動搖 。
這一方面源于 OpenAI GPT-5 系列模型的強勢崛起 , 在與 Claude Code 的對戰中大有「后來者居上」之勢 , AI 大神 Karpathy 現身說法并開始安利 GPT-5 Pro 的強大代碼能力 。
另一方面則是 Anthropic 自身的一系列迷之操作 , 先是放任并承認自家模型(包括 Claude Opus 4.1 和 Opus 4)降智 , 本周又宣布向包括中國在內的部分地區限制其 AI 產品和服務的使用 。
在這個微妙的時間節點 , 多家國產大模型廠商向 Anthropic 發起了一波正面狙擊 。 月之暗面發布了 Kimi-K2-0905 版本、阿里發布了超萬億參數的 Qwen3-Max-Preview 。
前者作為 Kimi-K2 系列模型的最新版本 , 將上下文長度擴展到了 256k , 針對前端開發等實際編程任務做了優化 , 長代碼生成中的正確性、穩定性和邏輯一致性較以往版本有了提升 。 后者是阿里迄今最大的模型 , 同樣提升了通用知識、數學推理、編程等多種任務的表現 。
可以看到 , 國產大模型廠商近來集中在代碼生成任務上發力 。 Kimi-K2-0905 強調了工具調用能力 , 并提升了模型與 Agent 框架(如 Roo Code)的集成性 。
在使用該模型調用外部工具時 , 格式正確率現在可以達到 100% , 不再需求人工修正 。 它還完全兼容 Anthropic API , 方便接入與遷移 。 對 WebSearch Tool 的支持 , 可以通過實時信息檢索提升任務效果 。
隨著 0905 版本的發布 , 近 30 天 Kimi-K2 系列模型在 Hugging Face 中的下載量超過了 39 萬 。
對于最新的 Kimi-K2-0905 , 有人直言「終于不用再為處理復雜的長任務而感到挫敗了 。 」
此消彼長 , 隨著國產大模型在代碼生成領域持續發力 , 全球競爭的格局也許真的要變一變了 。
能力、價格雙優勢 , 讓國產大模型更能打
作為 Kimi K2 系列中最新的版本 , Kimi-K2-0905 與其他國產大模型廠商的新模型(如 Qwen3-Max-Preview)一樣 , 向曾經的王者 Claude 的傳統優勢區間發起挑戰 , 強調智能編程領域的性能提升 。
從技術細節上來看 , Kimi-K2-0905 沿用了目前主流的 MoE 架構 , 參數規模為萬億級別 , 在推理時實際被激活的參數為 320 億 。
參數概覽
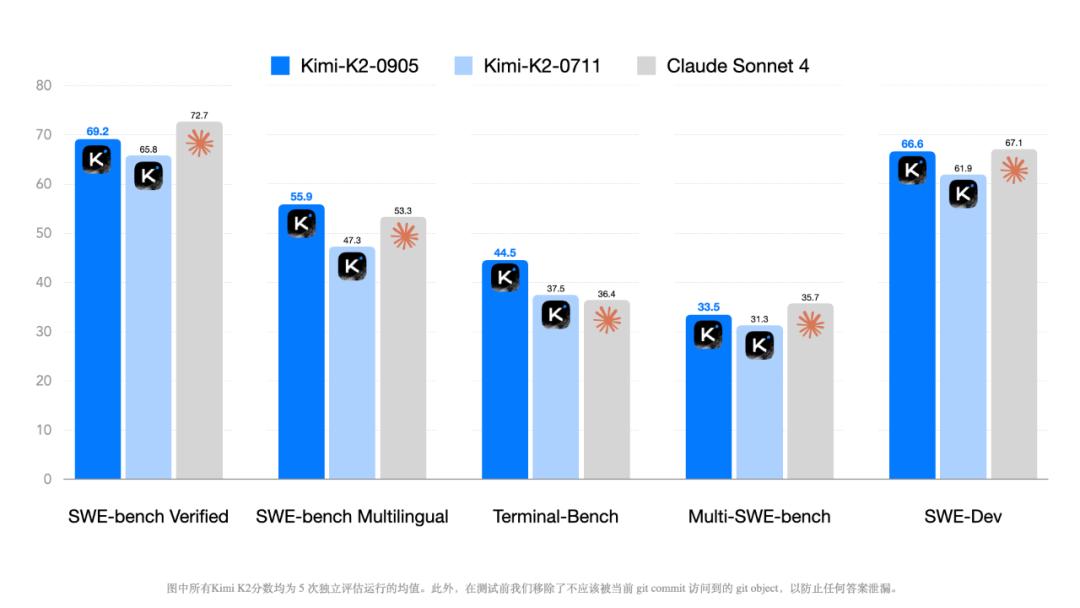
從該模型與 Claude Sonnet 4 在 SWE-bench Verified 等真實編程基準的對比中發現 , Kimi-K2-0905 在部分測試中(如多語言環境、命令行 / 終端交互)甚至超過了這個競爭對手 。
實戰表現究竟如何?我們用它做了個經典小游戲 。
指令很簡單:「制作一個和微信打飛機類似的網頁小游戲 , 需要美觀 , 好玩 , 功能齊全 。 」
Kimi-K2-0905 生成游戲代碼(部分截圖)
在網頁端實現的效果堪稱驚艷 , 不僅實現了浩瀚星空的背景 , 高速移動的拖影 , 概率出現的回血道具 , 還有不同顏色的敵人爆炸效果 , 甚至玩得好的話還有連擊加分 。
我們試著玩了好一會兒 , 困難模式真的挺難的 。
根據知名博主「karminski - 牙醫」的測試 , Kimi-K2-0905 前端水平有了顯著的提升 , 空間理解能力和召回能力都有所增強 。
在需要生成超過一千行代碼的「鞭炮連鎖爆炸測試」中 , Kimi-K2-0905 表現優秀 。
原貼地址:https://x.com/karminski3/status/1963834619276709933?s=46
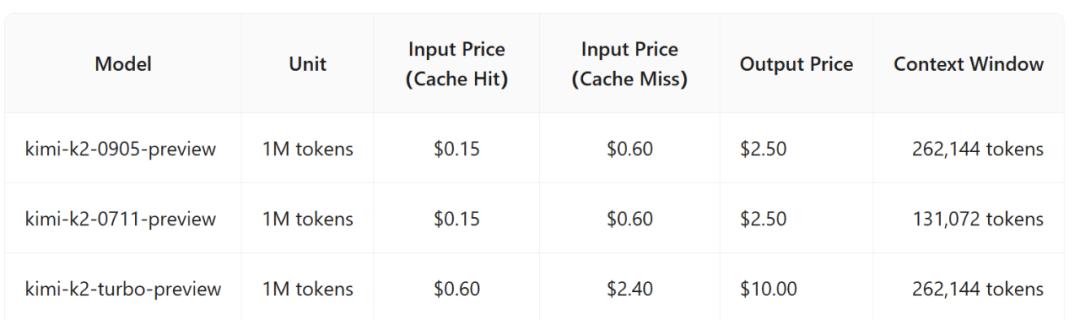
Kimi-K2-0905 此次還在 API 定價上打出了競爭性優勢 。
據我們了解 , Kimi 開放平臺上架的 kimi-k2-0905-preview 模型 API , 定價與上一代一致 , 計費方案為緩存未命中時每百萬輸入 tokens/4 元 , 緩存命中時每百萬輸入 tokens/1 元 , 每百萬輸出 tokens/16 元 。 詳細的定價策略參考下圖:
以美元計價的價格與國內價格比較接近 。
相較于 Anthropic 堪稱夸張的定價 , Kimi 等國產編程模型稱得上是「開源 Claude 平替」 , 并且能夠實現全方位兼容 Anthropic API 和 Claude Code , 延續開發者曾經的使用習慣 。
尤其是在 Anthropic 對國內和其他地區「斷供」的大背景下 , 讓現有項目和工作流平穩落地的重要性不言而喻 。
結語
在 AI 編程領域 , 國內的 AI 廠商都有自己的理解 。 大概分為兩個方向 , 一部分廠商在產品和用戶體驗側發力;另一部分則是打磨基礎模型 。
例如騰訊和字節對自家編碼產品的更新主要集中在產品側 , 字節更新 Trae Solo 版本、騰訊發布 CodeBuddy IDE 等等 , 都是試圖超越 Cursor 核心競爭力的嘗試 。
與之對應 , 以月之暗面為代表的 AI 新勢力 , 選擇了一條更為直接的發展道路:通過技術創新與極限性能打磨 , 力求在大模型核心能力上與國際一線廠商(如 Anthropic)一較高低 。
無論是上下文窗口的持續擴展 , 還是針對真實編程任務、Agent 工具調用等的專門優化 , 國內玩家正在取得逼近甚至超越海外同類產品的表現 。
同時 , 主流 AI 編程工具 , 如 Cursor、Windsurf、Trae、Cline 等 , 以及第三方 Agent 產品 , 如 flowith 和 Genspark 等 , 也都在主動接入國內優秀的大模型 , 中國 AI 新勢力已深度融入主流開發與應用生態 。
如今 , 國產大模型不僅能在性能參數上趕超國際領先者 , 也能在實際開發體驗上獲得更多認可 。 這樣的「正反饋循環」一旦形成 , 則有望快速積累開發者口碑 , 創建更繁榮的應用生態 , 進一步撬動更廣闊的市場 。
推薦閱讀













- 突發!Anthropic “封殺”中國控股公司,禁止其使用Claude等AI服務
- 中國控股企業使用Claude遭禁 智譜:推出“搬家計劃”
- 為什么我們的家的寬帶越用越憋屈?
- 直指2nm 要領先中國!印度:我們正在研制世界上最先進的芯片
- 華為郭平:鴻蒙是我們不得不打的一場“戰爭”
- 最后通牒!Claude聊天/代碼默認全喂AI訓練,你的隱私能被用5年
- Anthropic推出實驗性Claude AI插件可控制Chrome瀏覽器
- 手機直連衛星業務加速普及 會給我們帶來哪些便利?
- OpenAI和Anthropic罕見互評模型:Claude幻覺明顯要低
- 剖析蘋果邀請函后,我們發現了些沒人聊過的新功能