
文章圖片

文章圖片
文章圖片
在多模態模型里 , CLIP-style encoder 往往把視覺表征過早地拉近到文本空間:對于抽象層面的問答 , 如總結圖片大致內容 , 這樣的表征其實是沒有什么問題的 , 但一旦追問與語言無強依賴的細節 , 模型就更易出現幻覺 。 根本原因之一 , 是在文本空間對齊之前 , 原生視覺結構已被不可逆地壓縮 / 丟失 , 而語言模型不得不「二次解碼」來自他模態的 embedding , 導致對齊脆弱、推理鏈條變長 。
為此 , 北大、UC San Diego 和 BeingBeyond 聯合提出一種新的方法——Being-VL 的視覺 BPE 路線 。 Being-VL 的出發點是把這一步后置:先在純自監督、無 language condition 的設定下 , 把圖像離散化并「分詞」 , 再與文本在同一詞表、同一序列中由同一 Transformer 統一建模 , 從源頭縮短跨模態鏈路并保留視覺結構先驗 。
Being-VL 的實現分為三步 。 首先用 VQ(如 VQ-GAN)把圖像量化為離散 VQ tokens;隨后訓練一個視覺版 BPE , 不只看共現頻次 , 還顯式度量空間一致性 , 以優先合并那些既常見又在不同圖像中相對位置穩定的 token 對 , 得到更具語義與結構的 BPE tokens;最后把視覺 tokens 與文本 tokens 串成同一序列 , 進入同一個自回歸 LLM 統一建模 , 不再依賴額外 projector 或 CLIP 對齊 。 整個 BPE 詞表學習僅依賴圖像統計 , 不看文本 , 真正把「語言對齊」留到后續階段 。
論文鏈接:https://arxiv.org/abs/2506.23639 項目主頁: https://beingbeyond.github.io/Being-VL-0.5 GitHub: https://github.com/beingbeyond/Being-VL-0.5
與「把視覺直接投到文本空間」有何本質不同?
傳統做法讓 LLM 去再解釋外部視覺 encoder 的連續 embedding;即便 encoder 學到了豐富模式 , 沒有對應解碼器 , LLM 也要額外學習如何「讀懂」其他模態 , 這會放大模態鴻溝并誘發幻覺 。 Being-VL 把視覺提前離散化為可組合的 tokens , 并在序列里與文本統一建模 , 減少表征形態錯位 , 縮短跨模態因果鏈條 , 從而在保持感知細節與高層語義的同時 , 降低「想象成分」 。
針對視覺場景設計的 BPE tokenizer:頻次 × 空間一致性
文本大模型中的 BPE 只看「誰和誰經常相鄰」 。 在視覺里 , 如果只按頻次去合并 , 容易破壞結構 。 Being-VL 因此提出 Priority-Guided Encoding:基于 score P (ab)=F (ab)+α?S (ab) 進行 BPE 詞表構建 , 其中 F 為鄰接頻次 , S 衡量在不同圖像中的相對位置一致性 , 相似度用高斯核對齊 。 這樣得到的視覺詞表既覆蓋高頻模式 , 又保留空間結構 。 并且這個過程完全不依賴文本 。
三階段訓練:從 VQ/BPE embeddings 到 LLM backbone 的漸進解凍
為了讓統一的離散表示平滑接入語言模型 , Being-VL 采用三階段(3-stage)訓練并顯式控制解凍順序:
Stage-1 / Embedding Alignment:只訓練新擴展的視覺 token embeddings(包括 VQ 與 BPE 兩部分) , 其余參數全部凍結 , 完成基礎對齊而不擾動原有語言能力 。 Stage-2 / Selective Fine-tuning:解凍 LLM 前若干層(默認約 25%) , 其余層繼續凍結 , 讓跨模態交互首先在底層表征中發生 。 Stage-3 / Full Fine-tuning:全量解凍 , 在更復雜的 reasoning /instruction 數據上收尾 , 強化高級能力 。與解凍節奏配套 , 數據采用 curriculum:從基礎 caption 與屬性識別 , 逐步過渡到視覺問答與多輪指令 , 顯式對齊 BPE 的「由局部到整體」的層級特性 。 消融表明:漸進解凍 + curriculum 明顯優于單階段訓練;只用其中任一也不如兩者合用 。
實驗與分析
Being-VL 的一系列對照實驗給出一個清晰結論:把圖像先離散化并做視覺 BPE , 再與文本在同一序列里統一建模 , 既穩又有效 。 相較傳統「先拉到文本空間」的做法 , 這種統一的離散表示更少丟失原生視覺信息 , 因而在細節敏感的問答與抗幻覺上更可靠;而一旦移除 BPE , 性能與穩健性都會整體下降 , 說明增益主要來自于把「常見且空間關系穩定」 的視覺模式合成更有語義的 tokens , 讓 LLM 在更合適的粒度上推理 。
訓練與規模選擇方面也有明確「可執行」的答案 。 三階段漸進解凍 + curriculum 是默認策略:先只對齊 VQ/BPE embeddings , 再解凍一部分 LLM backbone , 最后全量微調 , 能在不擾動語言能力的前提下穩步提升跨模態理解 。
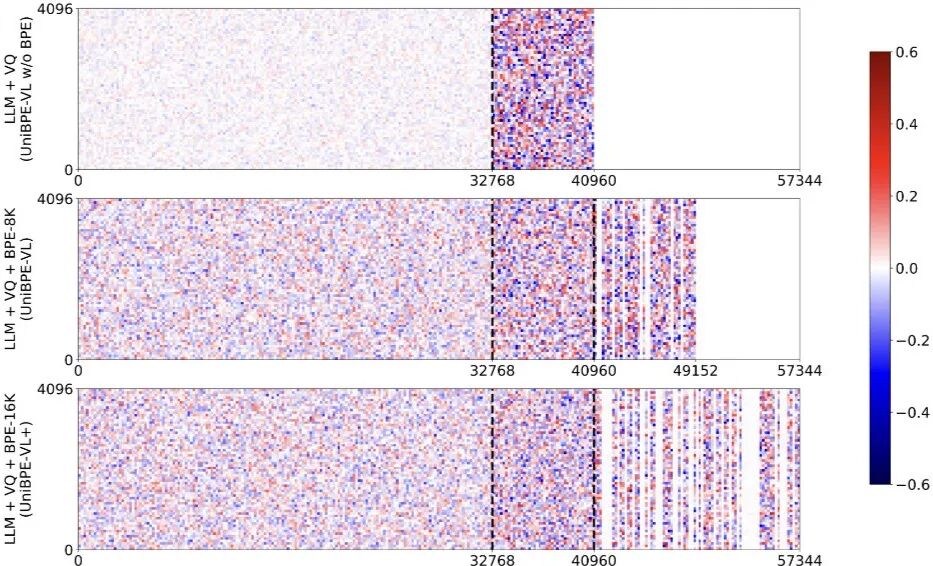
Visual BPE Token 激活機制可視化
Embedding 權重的可視化揭示了詞表設計對跨模態表征的影響:在不使用 visual BPE 的基線模型(上圖)中 , 文本與視覺 token 的權重呈現顯著偏置與分離 , 體現出明顯的模態隔閡;而引入不同詞表大小的 visual BPE(中、下圖)后 , 兩類 token 的權重分布趨于均衡與同構 , 說明 BPE 在更細粒度上對齊了子詞 / 子片段層面的統計與表征空間 。 由此帶來的直接效應是跨模態注意力的共享基準更一致、梯度信號更可比 , 從而降低模態間的分布漂移與共現偏差 。
詞表大小對訓練效率與擴展潛力的影響
研究進一步考察了 BPE 詞表規模的作用 。 可視化結果顯示:在訓練資源受限的情形下 , 與 VQ 等規模的碼本在表達能力與訓練效率之間取得了更佳平衡 , 處于「甜點區」 。 當詞表繼續增大(≥16K)時 , 會出現大量低利用率、呈稀疏分布的 token , 導致單位算力的收益下降 。 不過 , 這也預示著在數據規模擴張時存在更強的上限潛力 。 論文提出的方法可在更大的詞表與更多數據的配合下 , 釋放這部分擴展空間 , 進一步提升模型表現 。
發展與小結(Being-VL-0 → Being-VL-0.5)
Being-VL-0 (ICLR 2025)
Being-VL-0 給出的是視覺離散化 + BPE 的可行性與動機:從理論分析與 toy 實驗出發 , 得出結論 BPE-style 合并能把必要的結構先驗灌注進 token , 使 Transformer 更易學習;并初步探索了兩階段訓練(PT→SFT)、文本 embedding 凍結策略與數據 scaling 帶來的穩健增益 。 項目地址: https://github.com/BeingBeyond/Being-VL-0 【Being-VL的視覺BPE路線:把「看」和「說」真正統一起來】Being-VL-0.5 (ICCV 2025 highlight)
Being-VL-0.5 則把這一路線進一步優化為一個統一建模框架:頻次與空間一致性聯合的 Priority-Guided Encoding、VQ/BPE/LLM 三階段漸進解凍、以及配套的 curriculum 數據策略 。 項目地址: https://beingbeyond.github.io/Being-VL-0.5
推薦閱讀














- 小米目前“最值得撿漏”的一款手機,512G大跳水,7410mAh+100W
- 雙11有什么實用好物?精選雙11購物節10大值得入手的數碼好物推薦
- 高跟鞋都踩不壞的手機,又升級了?
- 2億可更換相機+2K屏+頂級音質!三千檔的驍龍8E5性價比之王來了
- 和小米17價格持平!努比亞即將發布的真全面屏新機,太能打了
- 真我GT8 Pro聯名理光相機 徐起:顛覆想象的影像合作
- 知名大牌產品接連“翻車”,智能戒指真的是未來嗎
- MCU的AI競賽,已經打響
- 舊電腦升級Windows11,要注意的幾點
- 央視記者展示小米17 Pro的背屏玩法:聯合國發言人發出驚呼