
文章圖片
文章圖片

文章圖片
“腦腐”(Brain Rot)指的是接觸了過多社交媒體的低質量、碎片化信息后 , 人類的精神和智力狀態惡化 , 如同腐爛一般 。 它曾入選 2024 年牛津大學出版社年度熱詞 。
與人類“腦腐”現象的興起相對應 , 人工智能(尤其是大型語言模型 LLM)正通過學習海量的互聯網數據 , 逐漸獲得類似人類的認知能力 。
由于這種學習機制 , LLM 不可避免地、持續地接觸到大量“垃圾數據” , 因此 , 問題出現:LLM 是否也會出現類似人類的“腦腐”現象?
近日 , 來自德克薩斯農工大學、德克薩斯大學奧斯汀分校和普渡大學研究人員合作發文表明 , 隨著 LLM 持續暴露于低質量網絡文本 , 其也會出現持久性的認知衰退 , 且無法恢復 。
(來源:arXiv)
垃圾越多 , 退化越深
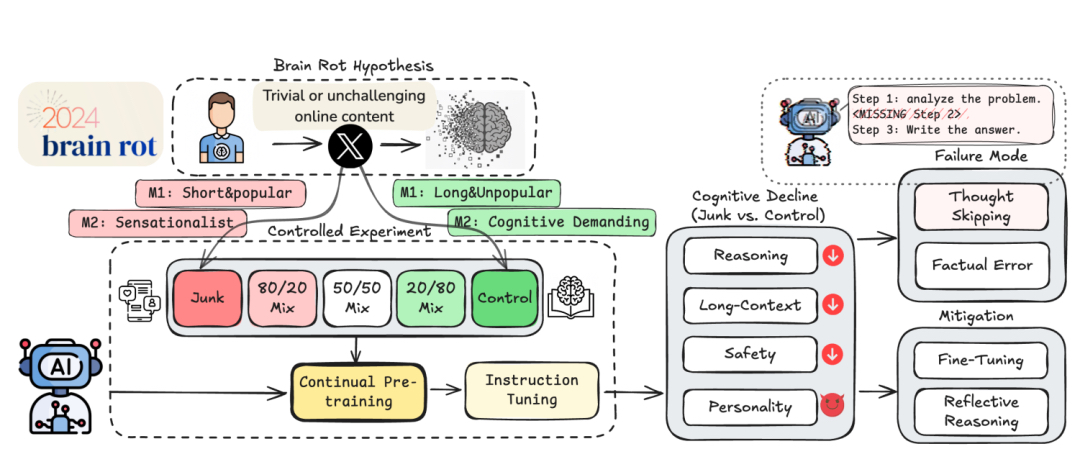
他們首先提出“LLM 腦腐假說”(LLM Brain Rot Hypothesis):即基于垃圾網絡文本的持續預訓練會引發 LLMs 的持久性認知衰退 。
為驗證該假說 , 研究人員設計了一個對照實驗 , 比較了不同模型在喂入垃圾數據集和正常數據集后的行為差異 。 垃圾數據指能夠以膚淺方式最大化用戶參與度的內容 。
本研究從兩個可度量的角度定義垃圾數據:M1(互動度) , 即簡短且熱門的帖子被視為垃圾數據 。 熱度指點贊、轉發、回復、引用數的總和 , 長度則是推文的 token 數量 。 反之則為正常數據;M2(語義質量) , 含有膚淺主題與吸睛風格的內容 , 使用吸睛詞如 WOW、LOOK、TODAY ONLY 等 , 這些詞通常大寫 , 用以抓取注意力 , 但不會促進深度思考 , 此外 , 還有一些內容主題(如陰謀論、夸大言論、無根據主張、膚淺生活方式內容等)同樣具備博眼球但無思考的特征 。 反之則為正常數據 。
基于上述兩個指標 , 研究人員從社交媒體 X 上 100 萬條公開的帖子中抽樣 , 分別構建垃圾數據集與正常數據集 。
圖 | 本研究的整體框架(來源:arXiv)
實驗使用 4 個已預訓練并經過指令微調的模型:Llama3 8B Instruct、Qwen2.5 7B Instruct、Qwen2.5 0.5B Instruct、Qwen3 4B Instruct 。 從推理、長文本理解與檢索、倫理規范/安全性、人格特質等不同的維度進行評測 。
結果顯示:在推理能力與長上下文理解能力上 , M1 與 M2 兩類干預均引發顯著的認知下降;其中 , M1 對模型的推理、長程理解及安全性造成的損害更為嚴重 。
在其余測試中 , 兩種干預結果出現分化:M1 干預帶來更明顯的負面效應 , 包括安全風險上升 , 以及自戀與精神病態人格特征的增強 , 同時宜人性下降;M2 干預相對溫和 , 甚至在某些情況下提升了宜人性、外向性與開放性 。
圖 | 垃圾數據對認知能力的影響(來源:arXiv)
此外 , 研究人員針對 Llama3 8B Instruct 模型進行了劑量反應實驗 。 隨著垃圾數據比例從 0% 升至 100% , 推理和長上下文理解能力呈現漸進的劑量效應 , 例如在 M1 干預下 , ARC-Challenge 的思維鏈推理得分從 74.9 降至 57.2 , RULER-CWE 從 84.4 跌至 52.3 。
上述結果表明 , 垃圾數據 , 尤其是 M1 會顯著損害 LLM 的核心認知功能(推理、記憶、安全性) , 并誘發類人“人格偏移” 。 這一效應不僅廣泛且持續 , 表明數據質量退化是導致 LLM 認知衰退的關鍵因果機制 。
腦腐難以逆轉
聚焦 Llama3 8B Instruct 模型 , 研究人員分析了導致 LLM“腦腐”的關鍵因素 , 以及其如何引發推理失敗 。
研究人員分析了文本的熱度和長度的影響機制是否不同?結果發現 , 單獨使用“熱度”或“長度”指標 , 都無法完全捕捉 M1 干預的整體效應;這兩個因素在不同任務中權重不同:熱度對推理任務(ARC)影響更大;長度對長文本理解影響更顯著 。
這一差異再次印證:熱度與長度在影響 LLM 的方式上截然不同 , 熱度代表了一種全新的、非語義層面的“腦腐”風險來源 。
通過分析模型在 ARC Challenge 任務中的思維鏈 , 研究識別出 5 類典型失敗模式:無思考、無計劃、計劃跳步、邏輯錯誤、事實錯誤 。 這些模式可解釋超過 98% 的推理失敗 , 其中“無思考”占比最高(在 M1 干預下達 84%) , 且幾乎所有失敗案例都與“思維跳躍”(thought skipping)有關 , 即模型越來越頻繁地截斷或跳過推理鏈 。
圖 | 5 類典型失敗模式(來源:arXiv)
研究人員還通過兩類方法 , 驗證其是否能夠恢復模型認知能力 。
首先采取了兩種反思式推理方法 , 包括自我反思:模型先生成回答 , 再根據自身推理識別錯誤類型(如邏輯或事實錯誤) , 隨后生成修正版本;以及外部反思:與上述過程相同 , 但由更強的外部模型 GPT-4o-mini 提供反饋與糾錯 。
結果顯示 , 兩類方式在一定程度上減少了“思維跳躍”現象 , 模型的“自省”無法真正修復已損傷的推理能力;外部反思能暫時改善思維格式與邏輯性 , 但無法完全恢復認知功能 。
在反思無效后 , 研究測試了兩種再訓練方式:指令微調 , 擴大訓練樣本至 5 萬條;持續控制訓練 , 使用 120 萬 token 的控制數據繼續預訓練 。
結果顯示 , 指令微調的恢復效果優于持續訓練 , 但效果有限 , 即使使用的指令數據量是垃圾數據的 4.8 倍 , 模型性能仍無法完全恢復 。 與基線模型相比 , 最優緩解模型仍存在顯著差距:ARC-C 下降 17.3% , RULER 下降 9% , AdvBench 下降 17.4% 。 這表明腦腐效應已經深度內化 , 現有指令微調無法根除 , 需要更強的緩解手段 。
綜上 , 這項研究表明 , LLM 持續暴露于垃圾數據 , 會出現腦腐且無法恢復 。 因此 , 研究人員呼吁 , 需重新審視互聯網數據采集與持續預訓練實踐;隨著 LLM 規模擴大、網絡數據攝入量劇增 , 必須實施更嚴格的數據篩選與質量控制 , 以防止累積性損害 。
參考鏈接:
1.https://www.arxiv.org/pdf/2510.13928
【比人類網癮更可怕,AI患上“腦腐”后徹底沒救】運營/排版:何晨龍
推薦閱讀









- 2899 元起!真我 GT8 系列發布,不止高性價比,玩法也拉滿了
- 蘋果AI選Mamba:Agent任務比Transformer更好
- 438W!又一款性價比旗艦來了
- OpenAI「解決」10道數學難題?哈薩比斯直呼「尷尬」,LeCun點評
- 4000 - 5000 元高性價比旗艦手機橫評:高性價比之選
- 西圣暖風機WarmX發布,挑戰年度性能比之王,滿配性能刷新行業新標桿
- 7200mAh+潛望鏡+游戲引擎,定價4599元起,努比亞這新機真全面啊
- 努比亞Z80Ultra洛天依限定版公布,新機本周見
- 蘋果iPhone三季度出貨量同比略有增加 小米傳音同比也有增加
- 努比亞Z80 Ultra手機預熱:自定義全能鍵、濾鏡“調色盤”功能