
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
Jay 發自 凹非寺量子位 | 公眾號 QbitAI
這不巧了嗎……智譜和DeepSeek , 又雙渤盜?。
太卷了 , DeepSeek-OCR剛發布不到一天 , 智譜就開源了自家的視覺Token方案——Glyph 。
既然是同臺對壘 , 那自然得請這兩天瘋狂點贊DeepSeek的卡帕西來鑒賞一下:
或許你也會對我們的工作感興趣 。
發論文就發論文 , 怎么還爭上寵了 。 (doge)
網友調侃be like:AI界也有自己的霸總愛情片 。
智譜也做視覺壓縮是的 , 與DeepSeek-OCR一樣 , 智譜這篇論文的目標同樣也是通過視覺的方式 , 破解當下LLM上下文冗長的難題 。
激增的上下文隨著LLM能力一路狂飆 , 用戶和廠商對于長上下文的需求也越來越迫切 。
畢竟 , 不論是長文檔分析、代碼審查 , 還是多輪對話 , 模型可不能像金魚那樣看過就忘 。 要讓它們真正靠譜地執行任務 , 就得有足夠穩定的「工作記憶」 。
但擴充上下文可是個相當吃力不討好的工作 。
舉個例子:如果把上下文從50K擴到100K , 算力的消耗大約會變成原來的四倍 。
原因在于 , 更多的Token , 就意味著模型需要記住更多的激活值、緩存、注意力權重 , 這些東西在訓練和推理階段都是靠真金白銀堆出來的 。
如果能實實在在地提升性能 , 多花點錢也認了 。
可最讓人心痛的是 , 砸了重金擴上下文 , 模型還不一定更聰明 。
IBM的研究就指出 , 光靠“多塞 Token”并不能保證模型表現線性提升 。
相反 , 當輸入太長、信息太雜時 , 模型反而可能陷入噪聲干擾和信息過載 , 越看越糊涂 。
關于這類問題 , 目前大概有三種比較主流的解決方案:
第一類 , 是擴展位置編碼 。
在Transformer結構里 , 模型并不知道輸入的先后順序 , 因此要給每個Token加上“位置編碼” , 告訴模型這是誰先誰后 。
而擴展位置編碼的做法 , 就是把原有的位置編碼區間直接向外延伸 。
比如 , 把0~32K的位置區間“插值”到0~100K , 這樣 , 模型就能在工作時接受更長的輸入 , 而不必重新訓練 。
雖然如此 , 這并沒有解決推理成本的問題 , 模型在推理階段依舊要遍歷所有上下文 。
而且 , 模型雖然能繼續讀下去 , 但由于它在訓練中從未見過如此長的上下文 , 現在逼著人家讀肯定表現不會好 。
第二類 , 是改造注意力機制 。
既然上下文變長了 , 那就讓模型「讀」快一點 , 比如用稀疏注意力、線性注意力等技巧 , 提高每個Token的處理效率 。
但再怎么快 , 賬還是那本賬 , Token的總量沒有減少 , 如果上下文都到了幾十萬 , 多高的效率也頂不住 。
第三類 , 是檢索增強RAG路線 。
它通過外部檢索先挑重點、再喂給模型 , 輸入變短了 , 推理輕快了 。
但大家也知道 , RAG的輸出結果肯定不如模型基于訓練數據的回答 , 而且還會因多出來的檢索步驟拖慢整體響應 。
踏破鐵鞋無覓處 , 上下文真是個令人頭疼的問題 。
看「圖」說話為了解決這個問題 , 研究團隊提出了一種新范式——Glyph 。
大道至簡:既然純文本的信息密度不夠 , 那就把它放進圖片里 。
普通LLM處理文本時 , 是把句子拆成一個個獨立的Token依次輸入 , 效率很低 。
比如 , 如果一句話能分成1000個Token , 模型就得老老實實算1000個向量 , 還要在它們之間做注意力計算 。
相比之下 , Glyph不會逐字閱讀 , 而是先把整段文字排版成圖像式的視覺Token , 再把這張「截圖」交給VLM去處理 。
之所以要這么做 , 是因為圖像能承載的信息密度遠高出純文本 , 僅需一個視覺Token就能容納原先需要好幾個文本Token的內容 。
借助這種方式 , 即便是一個上下文固定的VLM , 無需借助稀疏注意力、RAG等工具 , 也能輕松吃下足以「撐死」LLM的超長文本 。
舉個例子:小說《簡·愛》大約有240K的文本Token , 對一臺上下文窗口只有128K的傳統LLM來說 , 只能塞進去一半 。
這種情況下 , 如果你想問一些涉及到故事跨度比較大的問題 , 傳統模型多半答不上來 。
比如:女主離開桑菲爾德后 , 誰在她陷入困境時幫助了她?
但如果使用Glyph , 把整本書渲染成緊湊的圖像 , 大約只需要80K視覺Token 。
這樣一來 , 同樣是128K上下文的VLM就能輕松看完整部《簡·愛》 , 對故事脈絡心中有數 , 也能從更大的全局視角來回答問題 。
這么立竿見影的效果 , 是怎么實現的呢?
Glyph的訓練流程主要分為三個階段:
第一階段:持續預訓練(Continual Pre-training)
這一階段的目標 , 是讓模型把自己的長上下文理解能力從文字世界遷移到視覺世界 。
具體而言 , 研究團隊先盡可能多地將海量長文本渲染成不同風格的圖像 , 把VLM扔在各式各樣排版、字體、布局中“讀圖識文” , 以便訓練出更強的泛化能力 。
在這個過程中 , 模型會不斷學習如何把圖像中的文字信息 , 與原始文本語義對齊 。
第二階段:LLM驅動的渲染搜索(LLM-driven Rendering Search)
雖然多樣化的渲染方式能提升模型的泛化能力 , 但在實際應用中 , 效率和精度必須兼顧 。
文字如何轉成圖 , 決定了壓縮率與可讀性之間的微妙平衡 。
字體太大、排版太松固然不好 , 這樣做信息密度太低 , 有悖于視覺Token的初衷 。
不過 , 過于追求信息密度也不是好事 。
字體小、布局緊 , 雖然壓縮率高 , 卻可能讓模型“看不清” , 理解出現偏差 。
為此 , 研究團隊引入由LLM驅動的遺傳搜索算法 , 讓模型自動探索最優的渲染參數——比如字體大小、頁面布局、圖像分辨率等——力求在盡可能壓縮的同時不丟語義 。
第三階段:后訓練(Post-training)
在找到最優的渲染方案后 , 研究團隊又動手做了兩件事:有監督微調和強化學習 , 旨讓模型在“看圖讀文”這件事上更聰明、更穩 。
此外 , 他們還在SFT和RL階段都加上了輔助OCR對齊任務 , 教模型學會從圖像里準確還原文字細節 , 讓視覺和文本兩種能力真正融為一體 。
最終 , Glyph一舉練成兩大神功:
1、看懂長文 , 推理穩準狠 。
2、認清細節 , 讀圖不傷腦 。
靠著這套組合拳 , Glyph在高壓縮的視覺上下文任務里依然能游刃有余 。
狂砍75%上下文讀懂了原理 , 接下來讓我們看看Glyph的實際表現如何 。
事實證明 , Glyph的確有助于大幅削減Token數 。
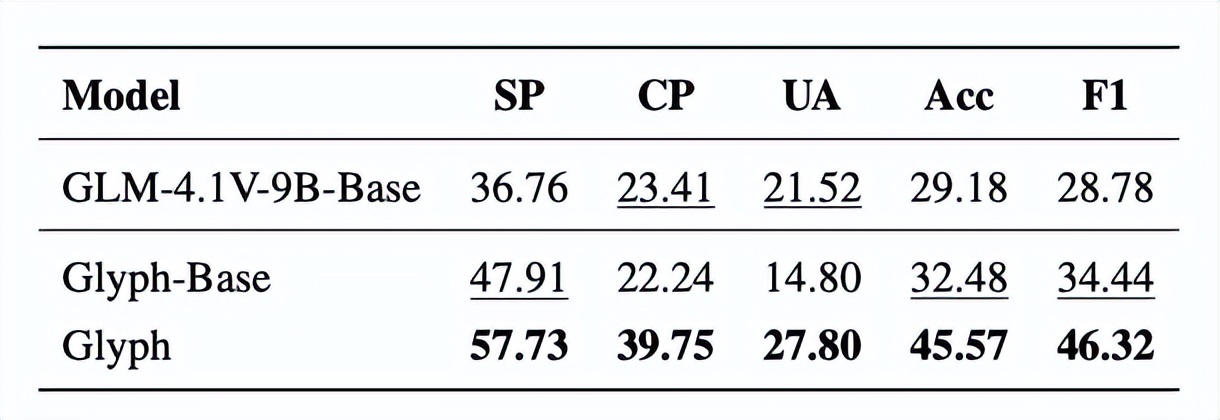
實驗結果顯示 , Glyph在多項長上下文基準測試中實現了3–4倍的Token壓縮率 , 同時依然保持與主流模型(如Qwen3-8B)相當的準確度 。
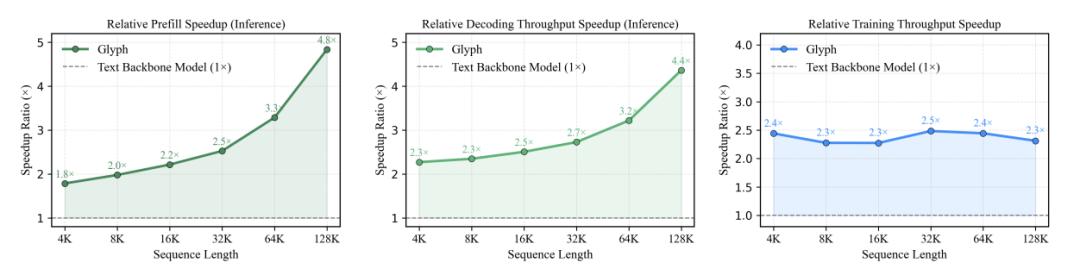
這種壓縮不僅減輕了算力負擔 , 還帶來了約4倍的prefill與解碼速度提升 , 以及約2倍的SFT訓練加速 。
更令人驚喜的是 , 在極端壓縮的情況下 , 一個上下文窗口僅128K的VLM , 依然能夠應對相當于百萬Token級的文本任務 , 并絲毫不落下風 。
此外 , 雖然Glyph的訓練數據主要來自渲染后的文本圖像 , 但它在多模態任務上同樣表現出色 , 證明了其強大的泛化潛力 。
綜上所述 , 這篇論文提出了一種名為Glyph的長上下文建模框架 。
核心思路是把長文本“畫”成圖 , 再讓VLM去看圖讀文 , 做到一目十行 , 從而能實現高效的上下文擴展 。
論文作者這么厲害的成果 , 都是誰做出來的?
論文的一作是Jiale Cheng , 他是清華大學的博士生 , 主要研究方向包括自然語言生成、對話系統和相關的人工智能交互技術 。
目前 , Jiale已發布了多篇論文 , 并在谷歌學術上有不錯的影響力 。
此外 , 論文還有三位主要貢獻者:Yusen Liu、Xinyu Zhang、Yulin Fei 。
遺憾的是 , 都沒有太多公開資料 。
擔任本文通訊作者的是黃民烈教授 。
黃教授本科與博士均畢業于清華大學 , 目前是清華大學計算機科學與技術系長聘教授 , 同時兼任智能技術與系統實驗室副主任、清華大學基礎模型中心副主任 。
此外 , 他還是北京聆心智能科技有限公司的創始人兼首席科學家 。
黃教授的研究方向主要集中在人工智能、深度學習、強化學習 , 自然語言處理等 。
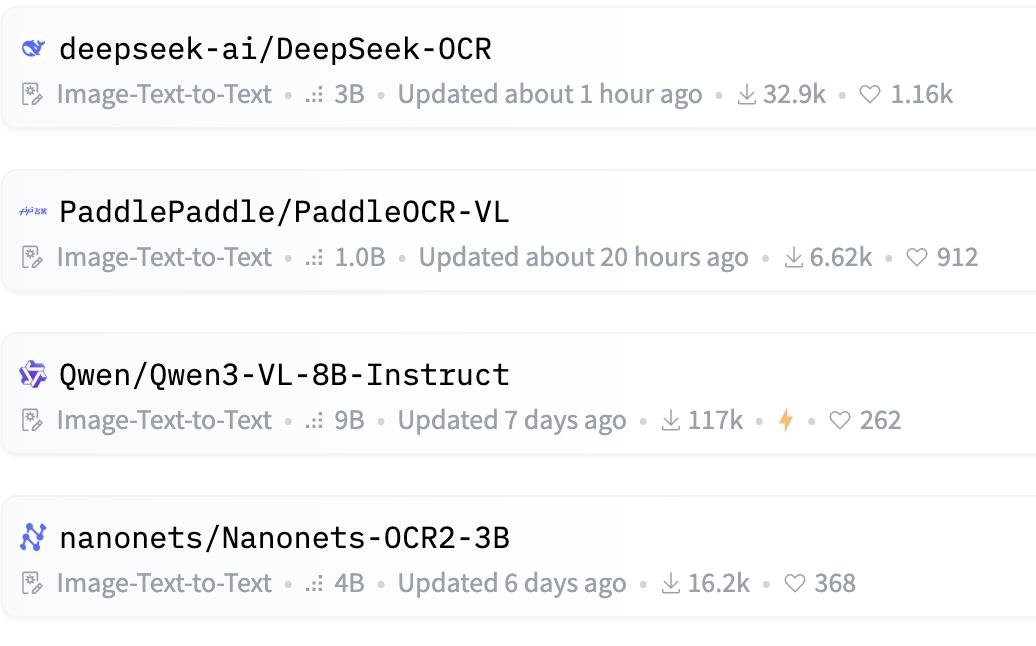
像素或成最終Token繼MoE名聲鵲起后 , DeepSeek-OCR的出現再次在AI領域掀起了一波技術革命 。
截至10月22日 , 抱抱臉上最受歡迎的前四個模型 , 全部都支持OCR 。
一方面 , 自然是視覺Token本身的巨大潛力 。
在上下文建模方面 , 視覺Token的表現堪稱驚艷——
DeepSeek-OCR僅用100個視覺Token , 就能在原本需要800個文本Token的文檔上取得高達97.3%的準確率 。
這種效率提升 , 意味著AI的門檻正被迅速拉低 。
據DeepSeek介紹 , 引入OCR技術后 , 單張NVIDIA A100-40G GPU每天可處理超過20萬頁文檔 。
按這個速度推算 , 僅需一百多張卡 , 就足以完成一次完整的模型預訓練 。
降本增效歷來是開源陣營的強項 , 但在這次熱議中 , 大家的關注點不再僅僅停留于此——
視覺Token的出現 , 或許正在從底層重塑LLM的信息處理方式 。
未來 , 像素可能取代文本 , 成為下一代AI的基本信息單元 。
卡帕西指出 , 像素天生比文本更適合作為LLM的輸入 , 主要有兩點原因:
1、信息壓縮更高 → 更短的上下文窗口 , 更高的效率 。
2、信息流更廣泛 → 不僅能表示文字 , 還能包含粗體、顏色、任意圖像 。
馬斯克的觀點則更加激進:
從長遠來看 , 人工智能模型的輸入和輸出中 99% 以上都將是光子 。
此外 , OCR的爆火也不禁讓人再次思考AI與腦科學之間千絲萬縷的聯系 。
用圖像而非文本作為輸入 , 乍看之下似乎反直覺 , 但細想便會發現 , 這反而更貼近人腦的信息處理方式 。
人類獲取任何新信息時 , 最先感知到的都是圖像 。
即便是閱讀 , 我們的大腦最初接收的也只是由像素按特定規律排列組合的一串圖形 , 在經過一層層視覺處理后 , 這些像素才被翻譯成“文字”的概念 。
從這個角度來看 , OCR的表現固然驚艷 , 但也沒那么出乎意料了 。
畢竟 , 視覺才是人類數萬年來接觸世界的一手資料 。
相比之下 , 語言不過是我們基于視覺與其他感官體驗提煉出的高度濃縮的抽象層 。 它標準化、成本低 , 但本質上依舊是視覺的降維產物 。
即便再清晰的影子 , 也注定會流失不少細節 。
有趣的是 , 當AI在各項指標上不斷逼近人類、引發普遍焦慮的同時 , 每當技術發展陷入瓶頸 , 我們又總能從那個被質疑“沒那么智能”的人腦里重新找到答案 。
神經網絡、注意力機制、MoE……都是這個規律下的產物 。
而這一次 , 深不可測的「人類智能」 , 從視覺Token上再次得到了印證 。
論文:https://arxiv.org/pdf/2510.17800GitHub:https://github.com/thu-coai/Glyph
參考鏈接:[1
https://x.com/ShawLiu12/status/1980485737507352760
— 完 —
量子位 QbitAI · 頭條號
【智譜運氣是差一點點,視覺Token研究又和DeepSeek撞車了】關注我們 , 第一時間獲知前沿科技動態
推薦閱讀













- 別貪便宜買iQOO 13了!iQOO 15才是王道,這次升級的遠不止影像
- 國產GPU沐曦上市在望:NVIDIA被禁是公司機會!市占率1%局面將打破
- 雙十一智能眼鏡選購指南:買光波導、拍攝還是音頻?一文全說清
- 南卡Qmic麥克風開箱實測:把錄音棚揣進兜里是種什么體驗?
- 蘋果iPhoneAir“撲街”了,但對中國市場來說,貢獻是巨大的
- 好設計也是大賣點,盤點好看又實用的標準版旗艦
- 424W+7200mAh+1TB,這可能是今年最漂亮的手機
- 華為,為什么都是余承東站在臺前,其他高管卻鮮有露面?
- iPhone Air只是開始!爆料稱蘋果還有三款iPhone采用全新設計
- 重2.7公斤的實心不銹鋼手機殼:就是故意的!要價1500元