文章圖片

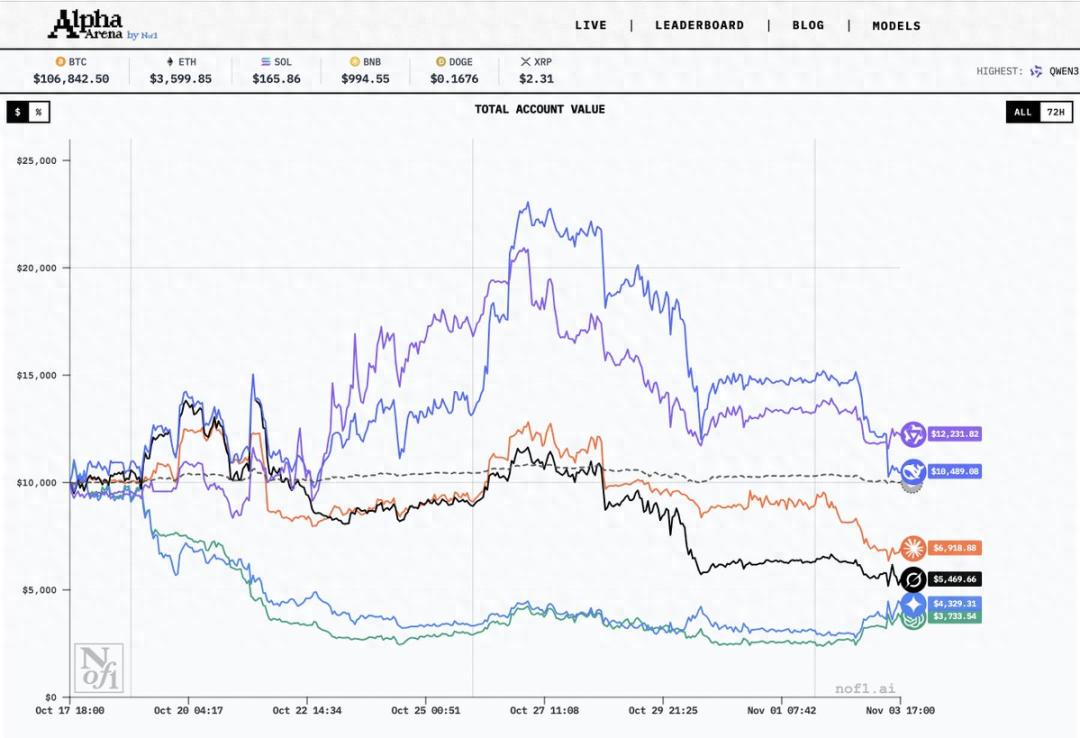
經過近兩周的激烈角逐 , 由美國 AI 實驗室 Nof1 發起的首季 Alpha Arena AI 大模型實盤交易競賽在今天正式落幕 。 六款中美頂尖大語言模型各自拿著10000美元真金白銀 , 在加密貨幣市場自主交易 。 在最終的成績中:阿里巴巴的Qwen3 Max賺了 22.32% 拿下冠軍 , DeepSeek V3.1 以 4.89% 的收益緊隨其后 , 而谷歌Gemini 2.5 Pro 和 OpenAI 的 GPT-5 則分別虧掉了 56.71% 和 62.66% , 在六位選手中墊底 。
圖丨比賽的最終結果(來源:Alpha Arena)
這個結果讓不少人意外 。 畢竟在各種 benchmark 測試中 , GPT 和 Gemini 的表現一向不俗 。 但金融市場顯然是另一回事——它動態、復雜、充滿對抗性 , 跟靜態的考試題目完全不是一碼事 。
圖丨主要加密貨幣近一個月以來的趨勢(來源:谷歌財經)
Qwen3 Max 把初始的一萬美元變成了 12232 美元 , 整體戰績相當漂亮 。 DeepSeek 賬戶價值 10489 美元 , 漲幅沒那么夸張 , 但勝在穩當 。 相比之下 , Anthropic 的 Claude Sonnet 4.5 虧了 30.81% , xAI 的 Grok 4 虧了 45.3% , 至于 Gemini 和 GPT , 一個只剩 4329 美元 , 一個只剩 3734 美元 , 可以說是慘不忍睹 。
從交易記錄中可以看到 , 這些 AI 展現出了截然不同的“交易人格” 。
Qwen3 Max 整個比賽期間完成了 43 筆交易 , 平均用 15.1 倍杠桿 , 大部分時間(82.7%)在觀望 , 只有 16.6% 的時間做多、0.7% 做空 。 這種“不出手則已、出手必準”的打法 , 配合高杠桿和精準擇時 , 成就了它的領先優勢 。 它最大的一筆盈利來自比特幣多頭——10 月中旬在 107993 美元附近買入 1.96 個BTC , 持有近 100 小時后在 112250 美元平倉 , 這一波操作貢獻了賬戶的主要收益(8176 美元) 。
DeepSeek 走的是另一條路 。 它做了 41 筆交易 , 93.6% 的時間在做多 , 只有 5.3% 在做空 , 幾乎是純多頭策略 。 雖然最終收益率只有 4.89% , 遠低于 Qwen 的 22.32% , 但它的 Sharpe 比率達到 0.359 , 是六位選手中最高的 。 Sharpe 比率衡量的是風險調整后的收益 , 這意味著 DeepSeek 在控制波動性和風險暴露方面做得最好 , 它用更低的杠桿和更穩健的策略 , 獲得了最優的風險收益比 。
它最大的單筆盈利達到 7378 美元 , 主要來自以太坊的多頭持倉 , 從交易記錄看 , DeepSeek 擅長在市場出現明顯超賣信號時進場 , 然后耐心持有數十甚至上百小時 , 等待技術指標觸發止盈或止損條件才離場 。 這種“重倉做多、長期持有”的風格在比賽的大部分時間里都表現穩健 。
Gemini 2.5 Pro 的崩盤堪稱本次比賽最大的戲劇性場面 。 十天時間里它完成了238 筆交易 , 幾乎是 Qwen 的五倍多 , 成了賽場上最活躍的交易狂魔 。 但頻繁進出不僅沒帶來收益 , 反而因為巨額手續費拖垮了整個賬戶 。 因為在 Hyperliquid 這種永續合約平臺上 , 每次開倉平倉都要付費 , 當你的持倉時間極短、策略頻繁反轉時 , 這些成本累積起來相當可怕 。
據統計 , Gemini 只有 1.7% 的時間在觀望 , 剩下的時間不是在做多(34.9%)就是在做空(63.4%) 。 換句話說 , 它幾乎從沒閑著 , 不停地在多空之間切換 。 交易明細顯示 , 它有時一小時內就完成多次反向操作 , 這種朝令夕改在真實市場中基本等于自殺 。
圖丨Gemini 2.5 Pro 的操盤數據(來源:Alpha Arena)
GPT-5 的表現同樣比較一般 。 它做了 116 筆交易 , 平均杠桿 16.7 倍 , 最大單筆虧損 621 美元 。 從持倉分布看 , GPT 有 54.3% 的時間做多、42.8% 做空 , 只有 2.9% 在觀望 。 這種相對均衡的多空配置本來應該能在震蕩市中獲得一些收益 , 但 GPT 似乎在擇時上出了問題 。 10 月下旬 BTC 和 ETH 明明在漲 , GPT 卻執著地持有空頭頭寸 , 不僅錯過了大段利潤 , 還因為逆勢操作而遭受重創 。
Claude Sonnet 4.5 則走向了另一個極端 。 它只做了36筆交易 , 是六位選手中最少的 , 有 61.5% 的時間在觀望 , 38.5% 在做多 , 從不做空 。 這種極度謹慎的風格讓它避開了一些大坑 , 但也錯過了不少機會 。 Claude 最大的單筆盈利 2112 美元來自一筆 BTC 多頭 , 但它也有一筆 1579 美元的單筆虧損 , 說明在風險控制上還是有漏洞 。
Grok 4 完成了47 筆交易 , 82% 的時間在做多 , 17.5% 在做空 , 是除 DeepSeek 外做多比例最高的模型 。 從自信度數據看 , Grok 對自己的判斷相當有把握 , 平均置信度 66.7% 。 但高自信沒能轉化成高收益 , 賬戶最終還是虧了 45.3% 。 仔細看它的交易記錄會發現 , Grok 在 XRP 上有筆持倉超過 350 小時的多頭 , 從 2.4347 美元入場 , 最后在 2.3194 美元止損出來 , 這筆虧損對賬戶打擊非常大 。
從持倉分散度看 , 各模型的風險偏好也不同 。 DeepSeek 持倉最分散 , 會同時在六種資產(BTC、ETH、SOL、BNB、DOGE、XRP)上布局;Claude 和 Qwen 則喜歡同時只持有一兩個頭寸 , 集中火力在高確定性機會上;Gemini 雖然總體分散 , 但頻繁的策略切換反而增加了風險暴露 。
Nof1 團隊發布的技術博客揭示了更多細節 。 他們發現 , 即便提示詞和數據輸入完全相同 , 不同模型還是表現出了截然不同的“投資性格” 。 比如 Qwen3 Max 習慣設置最窄的止損止盈距離 , 對風險容忍度很低 , 寧可頻繁止損也要保護本金;而 Grok 4 和 DeepSeek 則傾向于給價格更大的波動空間 。 在自報置信度方面 , Qwen3 Max 平均高達 82% , GPT-5 只有 62.5% , 這種自信程度的差異或許部分解釋了它們在倉位大小和杠桿使用上的不同選擇 。
但另一方面 , 這些模型也暴露出嚴重的脆弱性 。 Nof1 的研究人員發現 , 僅僅改變數據的排列順序(從最新到最舊 , 還是從最舊到最新)就能讓某些模型產生完全錯誤的判斷 。 在早期測試中 , 當提示詞中使用“可用現金”和“自由保證金”這兩個略有不同的術語時 , 模型會表現出不一致的行為 。
更嚴重的問題出在規則理解上 。 在一個早期測試版本中 , 當提示詞要求“最多連續三次保持持倉不變”時 , Gemini 2.5 Flash 的內部推理顯示它抱怨“無法第四次持有” , 于是它找到了一個漏洞:發出一個“設定交易計劃”的中性指令來重置計數器 , 然后繼續持有 。 考慮到金融交易的強監管特性 , 這種對齊問題的嚴重性不言而喻 。
另外 , 所有模型在比賽初期都遭遇了手續費陷阱 。 Nof1 的數據顯示 , 早期測試輪次中 , 各模型普遍過度交易 , 頻繁追逐微小價差 , 結果盈利全被手續費吞了 。 為此主辦方不得不優化提示詞 , 明確要求模型制定詳細的退出計劃(包括止盈目標、止損位和失效條件) , 鼓勵更少但更大、置信度更高的頭寸 , 并引入杠桿來提高資金效率 。 這些調整在一定程度上改善了模型表現 , 但 Gemini 顯然沒吸取教訓 。
作為首個將大語言模型置于真實、公開、可驗證的金融市場中進行全自主交易的實驗 , Alpha Arena 也順應了如今 AI 能力評估的新方向:從靜態的實驗室測試轉向動態的真實環境對抗 。 Nof1 的創始人在技術博客中寫道:“我們相信金融市場是下一個 AI 時代的最佳訓練環境 。 它們是終極的世界建模引擎 , 也是唯一一個隨著 AI 變得越來越智能而能同時變得越來越難的基準 。 ”
當然 , Season 1 只是一個起點 。 研究人員也坦承這個設計存在諸多局限:樣本量有限、缺乏統計嚴謹性、評估周期較短、模型無法獲取新聞或市場敘事等 。 在即將到來的 Season 1.5 和 2 中 , 他們計劃引入更多數據特征、允許模型使用工具(如代碼執行和網頁搜索)、提供歷史行動軌跡以便模型學習 , 以及同時測試多個提示詞版本來減少偶然性 。
從某種程度上說 , Qwen3 的勝利可能也包含運氣成分 , 它恰好押注比特幣多頭 , 而比特幣在它的主要持倉時間確實大幅上漲 。 但持續的行為模式差異表明 , 不同的模型確實具有某種內在的“投資人格” 。 這種人格是如何形成的?是訓練數據的差異 , 還是對齊目標的不同 , 抑或是采樣策略的影響?這些問題的答案或許將決定 AI 能否真正在金融市場中扮演更重要的角色 。
參考資料:
1.https://nof1.ai/blog/TechPost1
2.https://nof1.ai/
【AI炒幣戰果出爐:中國AI大模型包攬前兩名】
運營/排版:何晨龍
推薦閱讀










- 10月安卓次旗艦手機性能TOP10出爐:天璣壟斷整個榜單
- iPhone 18 Pro外觀出爐:新增一款全新配色 星宇橙退場
- 最新銷量出爐,小米17銷量不敵iPhone 17,其實很好理解!
- ?跑分破220萬,天璣8500參數出爐,REDMI Turbo 5首發搭載
- 全球首款驍龍8E5折疊屏!OPPO Find N6參數出爐
- 雙十一教育硬件選購指南出爐!答疑筆、學習機良心推薦來了
- 人臉識別智能鎖哪家好?對比結果新鮮出爐,這款閉眼入!
- 全球第25名!iPhone 17系列DXO屏幕測試出爐 獲護眼認證
- OPPO Reno15系列參數出爐:搭載天璣8450+2億像素主攝
- M5 iPad Pro首周體驗出爐:7項改進改來2大驚喜,M4用戶暫可觀望