
文章圖片
文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
編輯:好困
【新智元導讀】從馬拉松冠軍到最強大腦 , 這次的突破不再是四肢 , 而是靈魂 。
中國人形機器人 , 再獲突破性進展!
昨天 , 全球參數量最大的具身智能多模態(tài)大模型——Pelican-VL 1.0正式開源 。
它不僅覆蓋了7B到72B級別 , 能夠同時理解圖像、視頻和語言指令 , 并將這些感知信息轉化為可執(zhí)行的物理操作 。
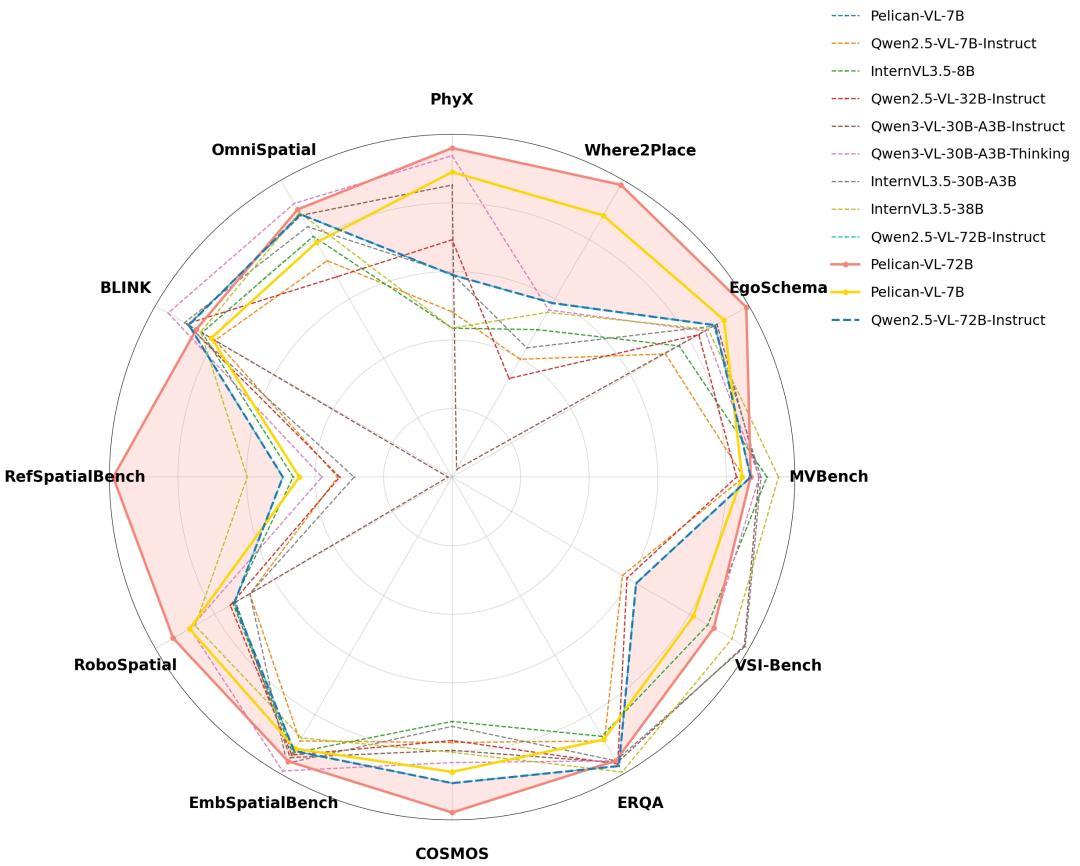
而且還針對目前具身能力短板 , 在空間理解、物理推理和思維鏈等維度實現了系統(tǒng)性提升 , 并在12個主流公開評測基準上達到行業(yè)領先水平 。
可以說 , Pelican-VL 1.0的提出 , 打通了從「看懂世界」到「動起來」的完整智能鏈路 。
項目主頁:
https://pelican-vl.github.io/
Github:
https://github.com/Open-X-Humanoid/pelican-vl
Hugging Face:
https://huggingface.co/X-Humanoid/Pelican1.0-VL-72B
ModelScope:
https://modelscope.cn/models/X-Humanoid/Pelican1.0-VL-72B
而這背后 , 便是創(chuàng)造全球首個人形機器人馬拉松冠軍的團隊——北京人形機器人創(chuàng)新中心 。
當前 , 通用大模型在遷移到具身智能任務時 , 仍面臨多維度能力欠缺的問題 。
李飛飛教授提出過Think in Space的觀點 , 強調走向具身智能需要解決空間智能問題的重要性 。 英偉達和谷歌也在研究中指出 , 具身領域的大模型必須具備物理智能 , 并相繼推出了Cosmos-Reason和Gemini-RoboticsER這類面向具身場景的多模態(tài)大模型 。
無獨有偶 , 創(chuàng)新中心也希望通過全面開源Pelican-VL這一基礎大腦模型 , 幫助更多具身智能體獲得更強的認知與決策能力 , 并在意圖理解、長程任務規(guī)劃推理等多類場景中實現性能提升 。
具體來說 , 通過「刻意練習」(DPPO)訓練范式 , Pelican-VL在不斷自我診斷與糾錯中提升推理與規(guī)劃能力 , 使模型像人類一樣在失敗中學習 , 從而實現了視覺理解、語言表達和物理執(zhí)行的深度融合 。
憑借這一機制 , Pelican-VL在多個維度展現出突破性能力:
- 具備跨模態(tài)的理解與推理能力 , 能在復雜環(huán)境中識別目標、推斷物體功能與可供性;
- 具備時間-空間認知 , 能理解動作的順序與因果關系 。
總體上 , 論文報告稱相較基線模型 , 在空間理解和時間推理等能力上出現顯著提升 , 并在若干公開基準上超過了部分100B量級的開源模型 。
【全球最大開源具身大模型!中國機器人跑完馬拉松后開始學思考】Pelican-VL的推出不僅是一次技術突破 , 更為產業(yè)界與學術界帶來了雙重啟示 。
它首先構建了一套貫通「視覺理解—長程規(guī)劃—物理操作」的通用訓練范式 , 提供了一個可復用、可擴展的范式 , 降低了具身智能研發(fā)的門檻 。
與此同時 , 團隊開放了模型與推理框架 , 為科研機構和企業(yè)提供了一個可自由定制、快速迭代的智能基座 , 加速了從實驗到落地的過程 。
更深層的意義在于 , Pelican-VL讓「機器人自主學習和反思」從理念走向現實 。
它的「刻意練習」機制使模型能在錯誤中總結經驗、持續(xù)進化 , 如同人類通過反復訓練掌握技能 。
這意味著未來的機器人不再只是機械執(zhí)行者 , 而是具備認知與改進能力的學習體 。
可以想象 , 在家庭或工業(yè)場景中 , 它將能夠自主判斷物體用途、調節(jié)操作力度、優(yōu)化行動策略——從被動執(zhí)行邁向主動理解與自我成長 , 標志著具身智能邁入真正的「學習時代」 。
智能抓取
實現精細抓取泛化操作新突破
當抓取一個水杯或一枚雞蛋時 , 基于Pelican-VL的大腦會瞬間完成一系列精密的操作:
通過視覺預判物體屬性、在接觸瞬間施加恰到好處的力道、并在觸碰后根據手感微調抓力 。
這套由主動預測、觸覺適應與記憶更新構成的「感知運動閉環(huán)」 , 是靈巧抓取的關鍵 。
而這項能力正是具身智能機器人與物理世界交互的基礎 , 但卻面臨著觸覺感知與運動靈活的協(xié)同難、復雜場景下的泛化難、算法與數據制約等等難題 , 目前行業(yè)內即便有相關技術突破 , 也仍未完全解決大規(guī)模落地的難題 。
如今 , Pelican-VL驅動的機器人抓取框架 , 成功復現并實現了這一高級智能 。
仿生核心:Pelican-VL構建的智能抓取閉環(huán)
技術框架嚴格遵循了人類感知運動的三個核心環(huán)節(jié) , 并將其轉化為可執(zhí)行的機器人系統(tǒng):
1. 主動預測:提供精準的「第一印象」
在機械臂接觸物體前 , Pelican-VL大模型憑借其卓越的視覺感知與真實世界物理推理能力 , 僅通過視覺輸入 , 就能精準預測出物體的物理屬性(如材質、易碎度) , 并生成初始抓取力 。
這為機器人提供了如同人類般的「先見之明」 , 使其從指尖接觸的一刻起 , 就具備了恰到好處的基準夾持力 , 通過模型提供前饋信息縮短閉環(huán)控制穩(wěn)定時間 。
2. 觸覺適應:實現毫秒級的「手感微調」
在抓取和操控過程中 , 指尖的觸覺傳感器會實時傳回微滑移、受力分布等數據 。 系統(tǒng)通過一個同步的在線摩擦估計與自適應抓取控制模塊 , 像人類神經反射一樣 , 持續(xù)、快速地微調抓力 。
這不僅確保了抓取的穩(wěn)定性 , 更關鍵的是能動態(tài)適應不確定因素 , 避免對精致、柔軟的物品造成損傷 。
3. 記憶更新:打造持續(xù)進化的「經驗庫」
每次抓取任務完成后 , 系統(tǒng)會對比預測與實際感官結果的差異 , 并將這次成功的交互經驗存儲在一個物理記憶圖譜中 。
當下一次遇到相同或類似的物體時 , Pelican-VL會優(yōu)先調用這個更新、更精確的記憶來指導預測 。 使機器人系統(tǒng)具備持續(xù)學習的能力 , 每一次抓取都在為下一次更精準、更柔和的操作打下基礎 。
實戰(zhàn)驗證:輕松拿捏精致與柔軟物體
在實際機器人測試中 , 該框架展現出了卓越的性能 。
從接近、加載、提升、持穩(wěn)到運輸歸還的完整七階段抓取流程中 , Pelican-VL驅動的機器人能穩(wěn)定操作一系列精致與柔性物體 。
- 「看得準」:由Pelican-VL提供的精準初始力先驗 , 極大地加速了后續(xù)自適應控制器的收斂過程 。
- 「抓得穩(wěn)」:在線控制器在提升、移動過程中持續(xù)動態(tài)調整抓力 , 有效應對慣性等擾動 , 確保抓取萬無一失 。
- 「學得快」:整個交互過程形成的經驗被存入知識圖譜 , 系統(tǒng)像一位經驗豐富的老師傅 , 越用越熟練 。
這一能力使機器人在低成本、低樣本的條件下依然能夠實現高度泛化、更加柔性的抓取表現 , 為行業(yè)帶來了真正可規(guī)模化落地的智能抓取方案 。
這不僅是技術上的一個里程碑 , 更為機器人在復雜、非結構化環(huán)境中真正實現自主操作 , 打開了無限可能的大門 。
VLM讓VLA實現能力躍遷
在典型的Vision–Language–Action(VLA)系統(tǒng)里 , Pelican-VL扮演著「視覺語言大腦」的角色 , 為機器人提供強大的環(huán)境感知和指令理解能力 。
它將攝像頭所見與自然語言指令結合 , 構建起對場景的多模態(tài)表征 , 然后輸出可供后續(xù)決策單元使用的結構化信息 。
也就是說 , Pelican-VL負責「看圖聽話」 , 理解指令和環(huán)境 , VLA負責跨機器人應用;二者組合可以在多種機器人上執(zhí)行多任務 。
有了這樣的基礎 , 系統(tǒng)可以完成長時序、多步驟的任務規(guī)劃和執(zhí)行 。
Pelican-VL等具身智能模型可部署在商超、家居等多種真實場景中 , 通過視覺-語言感知輔助多步任務規(guī)劃
論文中演示了一個生活場景下的復合指令:例如「把鞋子放到鞋架上、將桌上的垃圾扔到垃圾桶 , 再把衣服放入洗衣機」 。
Pelican-VL首先感知房間物體和布局 , 構建出整個環(huán)境的語義表示;接著根據指令自動生成行動序列:依次移動到鞋架、垃圾桶和洗衣機位置并進行抓取和放置操作 。
在這一過程中 , 模型不斷更新內部環(huán)境狀態(tài) , 調整計劃并適應實際情況 , 實現了自然語言指令的自主分解和執(zhí)行 。
簡而言之 , Pelican-VL構成了VLA系統(tǒng)的認知前端 , 為長期規(guī)劃和指令執(zhí)行提供跨模態(tài)的信息支持 , 使機器人能夠像人類一樣將復雜任務拆解并落地操作 。
同時 , 在快慢系統(tǒng)、端到端等諸多架構中 , 前沿探索者們也一直在致力于研究當VLA以VLM為基座時 , VLM各項能力為度對VLA模型所帶來的性能增益 。
例如DeepMind的RT-Affordance , 李飛飛的ReKep以及Sergey Levine的Training Strategies for Efficient Embodied Reasoning等著名學者和機構都曾探討過可供性、思維鏈等能力對于具身操作的重要性 。
對此 , Pelican-VL針對性地進行了能力提升 , 并在多個維度中達到行業(yè)領先水平 。
RT-Affordance項目地址:https://snasiriany.me/rt-affordance
ReKep項目地址:https://rekep-robot.github.io/
跨本體具身大腦實現多機協(xié)作
Pelican-VL具備不同層級的機器人任務規(guī)劃調度能力 , 可根據場景生成機器人行為規(guī)劃 , 并將其轉化為具體機器人功能函數的執(zhí)行調用 , 作為多機器人系統(tǒng)的任務調度器 。
論文中給出一個多機器人協(xié)作流水線的開發(fā)示例:
在一個燈泡質檢流程中 , Pelican-VL將任務按機器人拆分為若干行為層任務 , 進而生成不同機器人動作層的函數調用 。
例如 , 它會生成對「輪式人形機器人」執(zhí)行「檢查電控柜并啟動系統(tǒng)」的函數調用指令 , 也會為雙臂機器人生成「對燈泡進行結構與功能檢測」的調用 。
對于通用的操作函數 , 生成所需的控制參數 , 由專門的運動規(guī)劃模塊將其轉化為關節(jié)軌跡和夾爪動作 。
這種方式類似于一個項目經理給不同的團隊下達精確的工作指令 , Pelican-VL則通過多輪對話和分步指令 , 確保多臺機器人的協(xié)同工作 。
基于穩(wěn)定多視角可供性的零樣本操作
在更加通用的操作場景下 , 論文也給出了一個基于可供性進行任意物體操作的例子 。
Pelican-VL先輸出詳細的視覺定位和功能性描述(如目標物體的抓取點、放置位置等) , 然后利用函數調用機制觸發(fā)操作 。
例如在通用抓取演示中 , 它會先生成多視角下的一致性預估(如抓取點、避障區(qū)域)以保證空間定位準確;接著將這些計劃通過接口調用下發(fā)給運動控制單元 。
這一流程就像「思維鏈」式的中間規(guī)劃:模型內部先思考出清晰的步驟 , 再把每步落成可執(zhí)行的函數調用 , 確保執(zhí)行過程可控且透明 。
通過函數調用 , Pelican-VL不僅能處理單機任務 , 也可管理多機器人協(xié)作任務 , 進一步彰顯了其在復雜系統(tǒng)中的實用性 。
結語
此次Pelican-VL的開源 , 對于人形機器人產業(yè)與研究而言帶來了兩個正向價值:
- 首先它提供了一整套「視覺理解→長程規(guī)劃→物理操作」串聯(lián)的可復用訓練范式 , 降低了在機器人中使用 VLM 的門檻;
- 其次 , 借助開源基礎模型和推理代碼 , 所有其他實驗室或企業(yè)都可以在這個「腦」上做定制化訓練 , 加速人形機器人在各行各業(yè)的落地探索 。
不難看出 , 一切都是為產業(yè)落地提供更良好土壤 , 讓國內的機器人廠商和開發(fā)者可以自由使用與定制人形機器人 , 加速研發(fā)進程 , 并且正在讓具身智能機器人從最能跑 , 演化到最聰明和最好用的更高階段 。
根據了解 , 目前北京人形機器人創(chuàng)新中心還在推進「千臺機器人真實場景數據采集計劃」 , 讓上千臺機器人在工廠、倉庫、酒店等場景中執(zhí)行任務并采集數據 。
而這些規(guī)模化的多模態(tài)數據與Pelican-VL結合 , 將推動其在制造業(yè)自動化、智能物流、零售無人化和家居服務等多領域的快速適配和優(yōu)化 。
對于制造業(yè)企業(yè)來說 , 基于Pelican-VL快速開發(fā)特定場景下的應用方案 , 可大大降低開發(fā)成本和難度 。
長期來看 , Pelican-VL及其后續(xù)版本將促進國內形成完善的通用機器人智能平臺 , 推動更多種類的機器人像安裝「通用智能操作系統(tǒng)」一樣迅速獲取新能力 , 讓人形機器人更低門檻、低成本、高效率的走進不同制造業(yè)、工業(yè)體系 。
參考資料:
https://pelican-vl.github.io/
https://github.com/Open-X-Humanoid/pelican-vl
https://huggingface.co/X-Humanoid/Pelican1.0-VL-72B
https://modelscope.cn/models/X-Humanoid/Pelican1.0-VL-72B
推薦閱讀















- 中芯國際,可能已是全球第2大芯片代工廠,超過三星了
- 華為堆料激進 Mate 80 Pro Max來了:雙長焦+麒麟 全球唯一
- 未來領跑者|月之暗面:登頂全球“K2”背后的北京AI攀登者
- 榮耀400系列全球發(fā)貨量破600萬,500系列即將發(fā)布
- 消息稱國內顯示屏廠商上半年銷售額增至293億美元 全球份額首次過半
- 2M大小模型定義表格理解極限,清華大學崔鵬團隊開源LimiX-2M
- 全球AI數據中心越造越大,網絡連接技術成為創(chuàng)新重點
- AMD CEO蘇姿豐:全球AI數據中心市場規(guī)模在2030年將達到1萬億美元
- 榮耀400系列全球狂銷600萬臺!下一站500系列
- 2025全球計算大會召開, GCC彰顯全球計算生態(tài)核心樞紐價值