
文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
聞樂 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
何愷明又一次返璞歸真 。
最新論文直接推翻擴(kuò)散模型的主流玩法——不讓模型預(yù)測(cè)噪聲 , 而是直接畫干凈圖 。
如果你熟悉何愷明的作品 , 會(huì)發(fā)現(xiàn)這正是他創(chuàng)新的典型路徑 , 不提出更復(fù)雜的架構(gòu) , 而是把問題拆回最初的樣子 , 讓模型做它最擅長(zhǎng)的那件事 。
實(shí)際上 , 擴(kuò)散模型火了這么多年 , 架構(gòu)越做越復(fù)雜 , 比如預(yù)測(cè)噪聲、預(yù)測(cè)速度、對(duì)齊latent、堆tokenizer、加VAE、加perceptual loss……
但大家似乎忘了 , 擴(kuò)散模型原本就是去噪模型 。
現(xiàn)在這篇新論文把這件事重新擺上桌 , 既然叫denoising模型 , 那為什么不直接denoise?
于是 , 在ResNet、MAE等之后 , 何愷明團(tuán)隊(duì)又給出了一個(gè)“大道至簡(jiǎn)”的結(jié)論:擴(kuò)散模型應(yīng)該回到最初——直接預(yù)測(cè)圖像 。
擴(kuò)散模型可能被用錯(cuò)了當(dāng)下的主流擴(kuò)散模型 , 雖然設(shè)計(jì)思想以及名為“去噪” , 但在訓(xùn)練時(shí) , 神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)的目標(biāo)往往并不是干凈的圖像 , 而是噪聲 ,或者是一個(gè)混合了圖像與噪聲的速度場(chǎng) 。
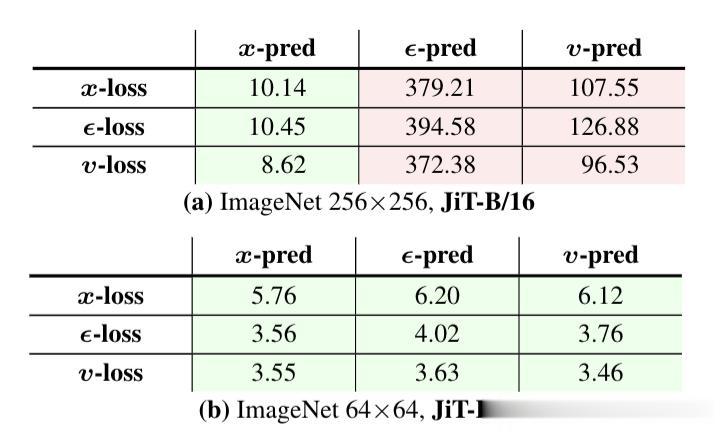
實(shí)際上 , 預(yù)測(cè)噪聲和預(yù)測(cè)干凈圖差得很遠(yuǎn) 。
根據(jù)流形假設(shè) , 自然圖像是分布在高維像素空間中的低維流形上的 , 是有規(guī)律可循的干凈數(shù)據(jù);而噪聲則是均勻彌散在整個(gè)高維空間中的 , 不具備這種低維結(jié)構(gòu) 。
簡(jiǎn)單理解就是 , 把高維像素空間想象成一個(gè)巨大的3D房間 , 而干凈的自然圖像其實(shí)都擠在房間里的一塊2D屏幕上 。 這就是流形假設(shè)——自然數(shù)據(jù)看著維度高 , 實(shí)則集中在一個(gè)低維的「曲面(流形)」上 。
但噪聲不一樣 。 它是彌漫在整個(gè)3D房間里的雪花點(diǎn) , 不在屏幕上;而速度場(chǎng)也一樣 , 一半在屏上、一半在屏外 , 同樣也脫離了「流形」的規(guī)律 。
這就導(dǎo)致了一個(gè)核心矛盾 , 在處理高維數(shù)據(jù)時(shí) , 例如將圖像切分為16x16甚至32x32的大Patch , 要求神經(jīng)網(wǎng)絡(luò)去擬合無規(guī)律的高維噪聲 , 需要極大的模型容量來保留所有信息 , 這很容易導(dǎo)致模型訓(xùn)練崩潰 。
而相反呢 , 如果讓網(wǎng)絡(luò)直接預(yù)測(cè)干凈的圖像 , 本質(zhì)上就是讓網(wǎng)絡(luò)學(xué)習(xí)如何將噪點(diǎn)投影回低維流形 , 這對(duì)于網(wǎng)絡(luò)容量的要求要低得多 , 也更符合神經(jīng)網(wǎng)絡(luò)“過濾噪聲、保留信號(hào)”的原本設(shè)計(jì) 。
于是 , 這篇文章提出了一個(gè)極簡(jiǎn)的架構(gòu)JiT——Just image Transformers 。
正如其名 , 這就是一個(gè)純粹處理圖像的Transformer , 它的設(shè)計(jì)非常簡(jiǎn)單 。 沒有像普遍的擴(kuò)散模型一樣使用VAE壓縮潛空間 , 也沒有設(shè)計(jì)任何Tokenizer , 不需要CLIP或DINO等預(yù)訓(xùn)練特征的對(duì)齊 , 也不依賴任何額外的損失函數(shù) 。
完全從像素開始 , 用一個(gè)純粹Transformer去做denoise 。
JiT就像一個(gè)標(biāo)準(zhǔn)的ViT , 它將原始像素切成大Patch(維度可高達(dá)3072維甚至更高)直接輸入 , 唯一的改動(dòng)就是將輸出目標(biāo)設(shè)定為直接預(yù)測(cè)干凈的圖像塊 。
實(shí)驗(yàn)結(jié)果顯示 , 在低維空間下 , 預(yù)測(cè)噪聲和預(yù)測(cè)原圖的表現(xiàn)難分伯仲;但一旦進(jìn)入高維空間 , 傳統(tǒng)的預(yù)測(cè)噪聲模型徹底崩潰 , FID(越低越優(yōu))指數(shù)級(jí)飆升 , 而直接預(yù)測(cè)原圖JiT卻依然穩(wěn)健 。
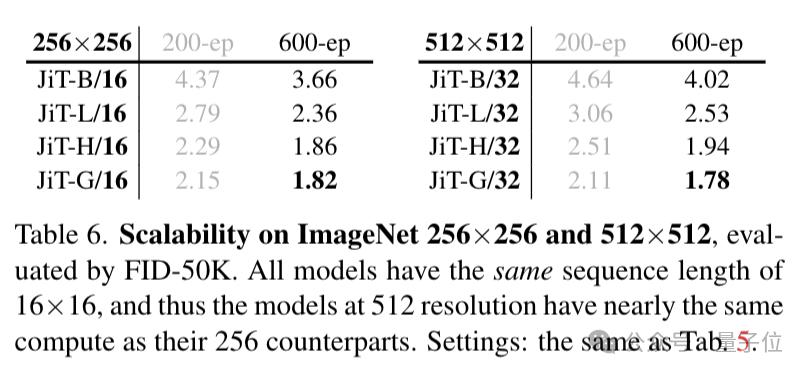
模型的擴(kuò)展能力也很出色 。 即使將patch尺寸擴(kuò)大到64x64 , 讓輸入維度高達(dá)一萬多維 , 只要堅(jiān)持預(yù)測(cè)原圖 , 無需增加網(wǎng)絡(luò)寬度也能實(shí)現(xiàn)高質(zhì)量生成 。
團(tuán)隊(duì)甚至發(fā)現(xiàn) , 在輸入端人為引入瓶頸層進(jìn)行降維 , 不僅不會(huì)導(dǎo)致模型失效 , 反而因?yàn)槠鹾狭肆餍螌W(xué)習(xí)過濾噪聲的本質(zhì) , 進(jìn)一步提升了生成質(zhì)量 。
這種極簡(jiǎn)架構(gòu)在不依賴任何復(fù)雜組件或預(yù)訓(xùn)練的情況下 , 在ImageNet 256x256和512x512上達(dá)到了1.82和1.78的SOTA級(jí)FID分?jǐn)?shù) 。
作者介紹這篇論文的一作是何愷明的開門弟子之一黎天鴻 , 本科畢業(yè)于清華姚班 , 在MIT獲得了碩博學(xué)位之后 , 目前在何愷明組內(nèi)從事博士后研究 。
他的主要研究方向是表征學(xué)習(xí)、生成模型以及兩者之間的協(xié)同作用 。 目標(biāo)是構(gòu)建能夠理解人類感知之外的世界的智能視覺系統(tǒng) 。
此前曾作為一作和何愷明開發(fā)了自條件圖像生成框架RCG , 團(tuán)隊(duì)最新的多項(xiàng)研究中他也都有參與 。
也可以說這是一位酷愛湖南菜的學(xué)者 , 把菜譜都展示在了自己的主頁上 。
【何愷明團(tuán)隊(duì)新作:擴(kuò)散模型可能被用錯(cuò)了】論文地址:https://arxiv.org/abs/2511.13720
— 完 —
量子位 QbitAI · 頭條號(hào)簽約
關(guān)注我們 , 第一時(shí)間獲知前沿科技動(dòng)態(tài)
推薦閱讀















- MIT英偉達(dá)團(tuán)隊(duì)革新注意力機(jī)制,破解LLM性能難題
- Google Play 2025年度榜單:大中華開發(fā)者團(tuán)隊(duì)斬獲16項(xiàng)大獎(jiǎng)
- AWS推出Kiro正式版,支持團(tuán)隊(duì)協(xié)作和CLI功能
- 消息稱字節(jié)跳動(dòng)Seed大語言模型團(tuán)隊(duì)核心成員喬思遠(yuǎn)離職 加入Meta
- 2M大小模型定義表格理解極限,清華大學(xué)崔鵬團(tuán)隊(duì)開源LimiX-2M
- 閃電快訊|三年數(shù)億元支持AI創(chuàng)業(yè)生態(tài),百度官宣再投8支初創(chuàng)團(tuán)隊(duì)
- 清華團(tuán)隊(duì):1.5B 模型新基線!用「最笨」的 RL 配方達(dá)到頂尖性能
- 雷軍挖來前DeepSeek大將!大模型團(tuán)隊(duì)40人合影曝光,疑進(jìn)軍具身智能
- 小鵬團(tuán)隊(duì)曾拒絕女性機(jī)器人當(dāng)場(chǎng)脫衣割肉:不被信任哭笑不得
- 何愷明MIT兩名新弟子曝光:首次有女生入組,另一位是FNO發(fā)明者