
文章圖片
文章圖片
周展輝(https://zhziszz.github.io/):加州大學(xué)伯克利分校計算機(jī)博士生;
陳凌杰(https://lingjiechen2.github.io/):伊利諾伊大學(xué)厄巴納香檳分校計算機(jī)博士生
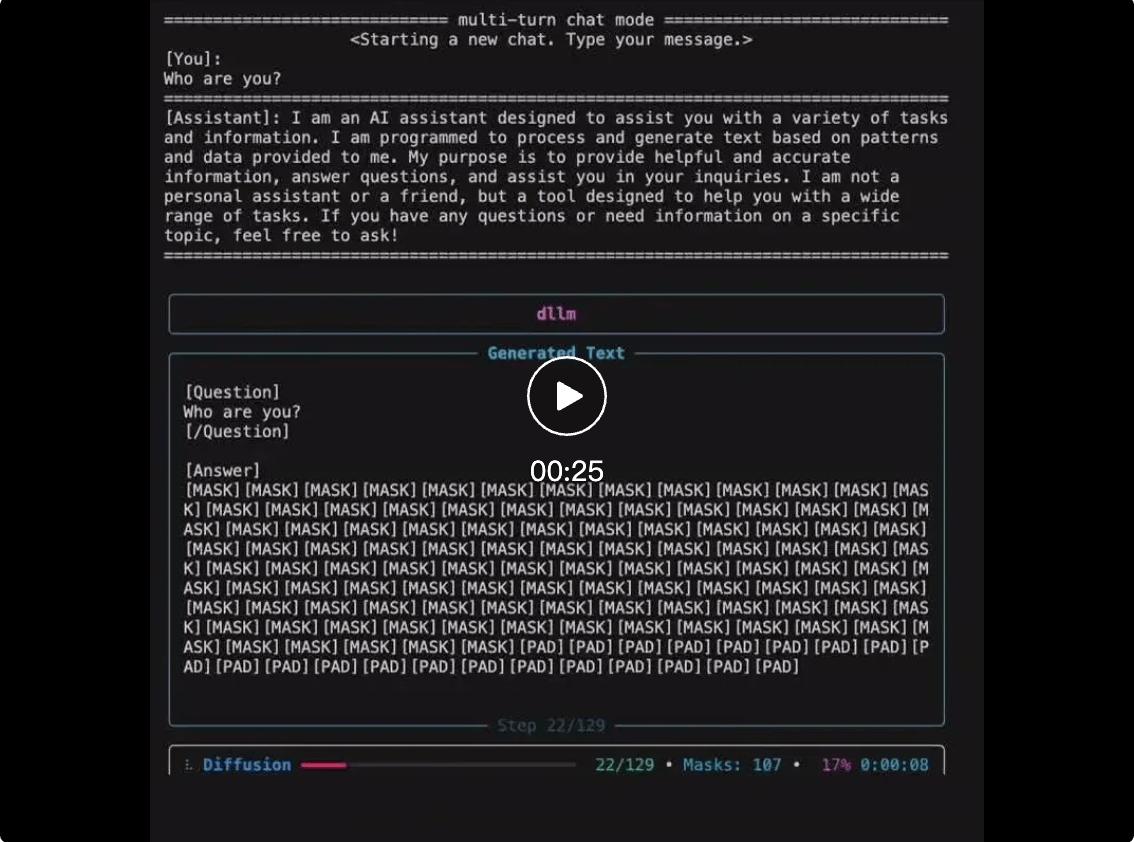
擴(kuò)散式語言模型(Diffusion Language Model DLM)雖近期受關(guān)注 , 但社區(qū)長期受限于(1)缺乏易用開發(fā)框架與(2)高昂訓(xùn)練成本 , 導(dǎo)致多數(shù) DLM 難以在合理預(yù)算下復(fù)現(xiàn) , 初學(xué)者也難以真正理解其訓(xùn)練與生成機(jī)制 。
為此 , 伯克利與 UIUC 團(tuán)隊(duì)基于自研的擴(kuò)散語言模型工具 dLLM , 做了一個簡單的實(shí)驗(yàn):讓 BERT 通過離散擴(kuò)散學(xué)會對話 。 結(jié)果遠(yuǎn)超預(yù)期 —— 無需生成式預(yù)訓(xùn)練 , 僅約 50 GPU?小時的監(jiān)督微調(diào) , ModernBERT-large-chat-v0(0.4B 參數(shù))在多項(xiàng)任務(wù)中的表現(xiàn)已逼近 Qwen1.5-0.5B , 證明「離散擴(kuò)散 + 輕量級指令微調(diào)」即可賦予經(jīng)典 BERT 強(qiáng)生成能力 , 為社區(qū)提供了真正高效、低成本的方案 。
更重要的是 , 團(tuán)隊(duì)已將訓(xùn)練、推理與評測的全流程代碼完全開源 , 并封裝為可直接運(yùn)行的「Hello World」示例 , 使初學(xué)者也能輕松復(fù)現(xiàn)并理解擴(kuò)散式語言模型的關(guān)鍵步驟 。 同時團(tuán)隊(duì)也開源了其背后的支持框架 dllm , 兼容當(dāng)前主流開源擴(kuò)散模型且有極強(qiáng)的可擴(kuò)展性 。
項(xiàng)目鏈接:https://github.com/ZHZisZZ/dllm 項(xiàng)目報告:https://wandb.ai/asap-zzhou/dllm/reports/dLLM-BERT-Chat--VmlldzoxNDg0MzExNg 項(xiàng)目模型:https://huggingface.co/collections/dllm-collection/bert-chatdLLM: 支撐 BERT Chat 的通用擴(kuò)散語言模型框架
BERT Chat 系列的訓(xùn)練、評測與可視化均基于團(tuán)隊(duì)自研的 dLLM—— 一個面向擴(kuò)散式語言模型的統(tǒng)一開發(fā)框架 。 dLLM 不僅是工具庫 , 更是一體化的研究平臺 , 持續(xù)吸引研究者使用與貢獻(xiàn) 。
在設(shè)計上 , dLLM 強(qiáng)調(diào)易用性與可復(fù)現(xiàn)性 。 框架結(jié)構(gòu)清晰、腳本完善 , 使 BERT Chat 等擴(kuò)散式訓(xùn)練實(shí)驗(yàn)?zāi)軌蛟趩慰ㄉ踔凉P記本環(huán)境復(fù)現(xiàn) , 非常適合初學(xué)者快速入門 。 同時 , 它兼容當(dāng)前主流的開源擴(kuò)散語言模型 , 包括 Dream、LLaDA、RND 等 , 提供靈活的模型基座選擇 。
更重要的是 , dLLM 還實(shí)現(xiàn)了多個缺乏公開實(shí)現(xiàn)的研究算法 , 如 Edit Flows , 使許多原本停留在論文中的擴(kuò)散式生成方法得以真正落地 , 為社區(qū)進(jìn)一步探索提供了堅實(shí)基礎(chǔ) 。
基座模型選擇:為何最終選擇 ModernBERT
在選擇基座模型之前 , 實(shí)驗(yàn)首先關(guān)注 ModernBERT 這一近期提出的 BERT 變體 。 相比原始 BERT 的 512-token 上下文窗口 , ModernBERT 將上下文長度顯著擴(kuò)展至 8192 tokens , 并在多個非生成式基準(zhǔn)任務(wù)上表現(xiàn)更優(yōu) 。 因此 , 實(shí)驗(yàn)的核心問題是:這些改進(jìn)是否能夠在生成式訓(xùn)練場景中帶來實(shí)際收益?為此 , 實(shí)驗(yàn)采用離散擴(kuò)散語言建模 , 在 Wikitext-103-v1 數(shù)據(jù)集上進(jìn)行了預(yù)訓(xùn)練測試 。 結(jié)果顯示 , 在一眾對比的模型中 , ModernBERT 達(dá)到了最低的訓(xùn)練 loss , 表明它在生成式訓(xùn)練中同樣具備優(yōu)勢 。 基于這一表現(xiàn) , 我們選定 ModernBERT 為后續(xù)離散擴(kuò)散訓(xùn)練與指令微調(diào)的主要基座模型 。
擴(kuò)散式預(yù)訓(xùn)練是否必要?
SFT 已足以激活生成能力
在探索擴(kuò)散式訓(xùn)練路徑時 , 實(shí)驗(yàn)首先嘗試在更大規(guī)模的語料庫(OpenWebText)上對 ModernBERT 進(jìn)行離散擴(kuò)散語言建模預(yù)訓(xùn)練 。 然而 , 與在 Wikitext-103-v1 上的訓(xùn)練效果不同 , 模型在 OpenWebText 上的訓(xùn)練 loss 并未出現(xiàn)顯著下降 。 這一結(jié)果表明 , ModernBERT 的原始 MLM 預(yù)訓(xùn)練已經(jīng)提供了大量語言與世界知識 , 對相似語料進(jìn)行額外的 MDLM 預(yù)訓(xùn)練可能收益有限 。
由此進(jìn)一步提出疑問:對于 ModernBERT 而言 , 持續(xù)的生成式預(yù)訓(xùn)練是否真的必要?為驗(yàn)證這一點(diǎn) , 實(shí)驗(yàn)分別對三種 ModernBERT-large 檢查點(diǎn)進(jìn)行指令微調(diào)(SFT):
(1) 未經(jīng)任何生成式預(yù)訓(xùn)練的版本 ,
(2) 在 Wikitext-103-v1 上做過 MDLM 預(yù)訓(xùn)練的版本 ,
(3) 在 OpenWebText 上做過 MDLM 預(yù)訓(xùn)練的版本 。
盡管經(jīng)過生成式預(yù)訓(xùn)練的模型(2 和 3)在 SFT 初期具有更低的訓(xùn)練 loss , 但三者最終在訓(xùn)練與評測 loss 上的收斂表現(xiàn)幾乎相同 。 該結(jié)果說明 , ModernBERT 的原始 MLM 預(yù)訓(xùn)練已編碼了足夠的語言知識 , 在此基礎(chǔ)上進(jìn)行額外的離散擴(kuò)散語言建模預(yù)訓(xùn)練 , 對后續(xù)的指令微調(diào)帶來的收益非常有限 。
在確認(rèn)預(yù)訓(xùn)練并非必要后 , 團(tuán)隊(duì)擴(kuò)大了 SFT 數(shù)據(jù)規(guī)模 , 將 allenai/tulu-3-sft-mixture 與 HuggingFaceTB/smoltalk 拼接 , 并分別在 ModernBERT-base 與 ModernBERT-large 上進(jìn)行離散擴(kuò)散微調(diào) , 最終得到兩個模型權(quán)重:ModernBERT-base-chat-v0(0.1B) 與 ModernBERT-large-chat-v0(0.4B) 。 兩者均展現(xiàn)出穩(wěn)定的多輪對話能力 。 綜合這些結(jié)果可以得到結(jié)論:對于 BERT 而言 , 擴(kuò)散式 SFT 本身就足以激活生成能力;額外的生成式擴(kuò)散預(yù)訓(xùn)練帶來的收益極小 , 而決定最終性能的關(guān)鍵是指令微調(diào) 。
實(shí)驗(yàn)結(jié)果:超乎預(yù)期的小模型表現(xiàn)
在多項(xiàng)主流評測任務(wù)上 , 對 ModernBERT 系列模型進(jìn)行了系統(tǒng)測試 , 包括 LAMBADA(語言理解)、GSM8K(數(shù)學(xué)推理)以及 CEVAL-valid(中文知識測評) 。 結(jié)果顯示 , ModernBERT-base-chat-v0(0.1B)與 ModernBERT-large-chat-v0(0.4B)在各項(xiàng)指標(biāo)上均表現(xiàn)穩(wěn)定 , 其中 large 版本的整體性能已接近 Qwen1.5-0.5B 。 值得注意的是 , ModernBERT-base-chat-v0 僅使用約四分之一規(guī)模的參數(shù)(0.1B) , 便能夠生成流暢自然的語言 , 這進(jìn)一步說明擴(kuò)散式訓(xùn)練在小模型規(guī)模下依然具備競爭力 。
項(xiàng)目說明:一份為學(xué)習(xí)而生的擴(kuò)散模型示例
團(tuán)隊(duì)將 BERT Chat 系列定位為一項(xiàng)教學(xué)與研究實(shí)驗(yàn) , 而非商用系統(tǒng) 。 在 0.1B 與 0.4B 這樣的小模型規(guī)模下 , 我們并不過多追求其在基準(zhǔn)測試集上的表現(xiàn) , 但它們足以作為入門示例 , 幫助研究者理解擴(kuò)散式語言模型的訓(xùn)練與生成機(jī)制 。 若希望進(jìn)一步探索模型潛力 , 也可以嘗試減少擴(kuò)散步數(shù)(例如將 T 減半) , 通常會帶來明顯的生成速度提升 , 因?yàn)閿U(kuò)散模型能夠在一次迭代中并行生成多個 token 。
為保持研究過程的透明與可復(fù)現(xiàn)性 , 團(tuán)隊(duì)不僅開放了完整的訓(xùn)練腳本 , 還公布了全部訓(xùn)練曲線、消融實(shí)驗(yàn)、參數(shù)設(shè)置與運(yùn)行指令 。 相關(guān)記錄可直接在 WB 報告中查看 。 我們相信 , 開放研究不應(yīng)只呈現(xiàn)成功的結(jié)果 , 而應(yīng)將完整的探索過程一并公開 , 幫助社區(qū)更全面地理解擴(kuò)散語言模型的研究路徑 。
總結(jié):BERT 的新潛力
【通用的dLLM開發(fā)框架,讓BERT掌握擴(kuò)散式對話】本研究展示了一個簡單卻關(guān)鍵的結(jié)論:僅依靠擴(kuò)散式 SFT 與少量指令數(shù)據(jù) , 就能夠賦予傳統(tǒng) BERT 實(shí)用級的對話生成能力 。 無需龐大的自回歸預(yù)訓(xùn)練 , 也無需 TB 級 token 的數(shù)據(jù)成本 , BERT 仍然具備被「重新激活」的潛力 。 對于一直希望找到一個「能跑通、能看懂」的 Diffusion LM 教程的讀者而言 , dLLM 正是一個從訓(xùn)練、推理到評測都能完整貫通的起點(diǎn) 。
推薦閱讀













- 終于,iOS、安卓、鴻蒙全面互通!
- 澎湃OS再次公布進(jìn)展通報:相機(jī)卡頓修復(fù),還有一堆問題處理中!
- 高通與聯(lián)發(fā)科將獨(dú)享LPDDR6內(nèi)存:漲價已成定局
- 高通驍龍X2 Elite硬剛蘋果M5:Arm芯片的終極逆襲!
- 雙旗艦28日同臺!華為Mate80首發(fā)無網(wǎng)通訊,X7紅楓定制滿血版來了
- 華為Mate 80系列雙機(jī)曝光:8000尼特屏幕與eSIM四網(wǎng)通重塑旗艦標(biāo)準(zhǔn)
- 爆料稱榮耀有3臺萬級mAh電池新機(jī)|谷歌Pxiel分享功能已與蘋果互通
- 高通:驍龍X2能兼容約90%的游戲,GPU性能是上一代2.3倍
- 通往通用人工智能?DeepMind放大招,3D世界最強(qiáng)AI智能體SIMA 2
- 高通第五代驍龍8突然官宣:架構(gòu)細(xì)節(jié)均已清晰,11月26日發(fā)布