
文章圖片
文章圖片
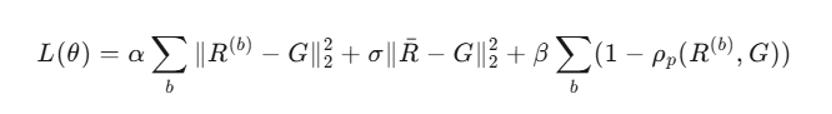
文章圖片

文章圖片
在 LLM 評估體系日益依賴 \"大模型擔任評估者\"(LLM-as-a-Judge)的今天 , 一個隱秘且嚴重的問題正在扭曲大模型的評估生態:偏好偏差 。
即使是性能強勁的 GPT-4o 和 DeepSeek-V3 , 在進行成對答案比較時 , 也會系統性地偏愛特定輸出 —— 尤其是自己生成的內容 。 這種偏差導致不同裁判模型給出的評分和排名天差地別 。 論文中的實驗數據顯示 , 在 ArenaHard 數據集上 , 自我偏好偏差幅度從 - 38% 到 + 90% 不等 。 當模型既是 \"運動員\" 又是 \"裁判\" 時 , 公平性無從談起 。
現有解決方案依賴提示工程、模型集成或博弈論重排等 , 但這些方法要么缺乏理論支撐 , 要么成本爆炸 , 要么難以擴展 。 更重要的是 , 它們都依賴人工設計的規則 , 沒有辦法讓大模型輸出統一的結果 。
UDA 的出現 , 為破解這一困局提供了新思路 。 來自智譜 AI 的研究團隊將無監督學習引入成對 LLM 評判體系 , 讓模型能夠自主動態調整評分規則 , 實現去偏對齊 。
該論文已被 AAAI 2026 錄用 。
論文標題:UDA: Unsupervised Debiasing Alignment for Pair-wise LLM-as-a-Judge 論文鏈接:https://arxiv.org/pdf/2508.09724 代碼倉庫:https://github.com/zhang360428/UDA_Debias
評判偏差:大模型擔任評估者的 \"偏好之困\"
現有的 LLM 評判系統(如 Chatbot Arena)普遍采用 Elo 評分機制 , 但面臨著三類挑戰:
自我偏好固化:模型系統性高估自己生成的答案 , 導致 \"誰當裁判誰占優\" 的荒謬局面; 異質性偏差:不同模型的偏差方向與強度各異 , 從激進自夸到過度謙遜不一而足; 靜態評分缺陷:傳統 Elo 使用固定 K 因子 , 無法區分關鍵對決與平庸比較 , 小樣本下信噪比極低 。
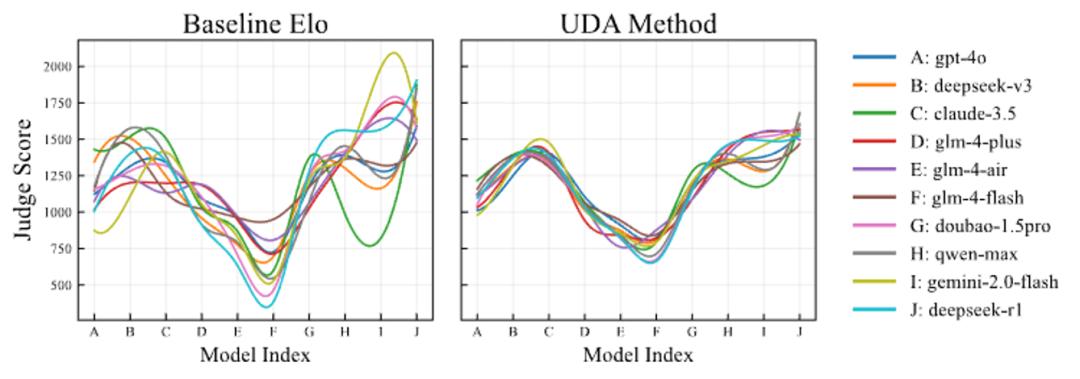
結果就是 \"評分失準\"、\"排名震蕩\" 頻發:如下圖所示 , 在未經優化前 , 10 個主流 LLM 裁判對同一組答案給出的 Elo 分數標準差最高能達到 158.5 分 , 評分軌跡如脫韁野馬般離散 。 而經過 UDA 對齊后 , 各裁判軌跡顯著收斂 , 共識穩定度提升近 60% 。
UDA 的核心貢獻在于將去偏問題轉化為一個可通過動態校準優化的序列學習問題 。 與以往依賴人工規則或監督信號的方法不同 , UDA 讓評判者在處理每對比較時自主探索最優的評分策略 , 并通過共識最小化目標直接獲得反饋 。 這種無監督的優化方式使模型能夠學習到較為公平的對齊機制 。
方法框架
如圖所示 , UDA 將成對評估建模為實例級自適應過程 。 對每個裁判模型 k , 當比較答案對 (ai aj) 時 , 系統提取多重特征 , 通過輕量級網絡動態生成調整參數 , 最終輸出校準后的 Elo 更新 。 訓練過程中通過共識錨定目標獲得反饋 。 被訓練的適配器 () 專注學習去偏策略 , 固定的 Elo 系統 (??) 負責基礎評分 。
特征工程與自適應網絡
UDA 的精髓在于人類標注無關的特征構建 。 對每對比較 , 系統提取基于語義的特征向量 φ(k) ij , 涵蓋:
高維特征:答案嵌入間的 element-wise 差值、歸一化積 , 捕捉語義風格差異 標量特征:余弦相似度、KL 散度、長度差異 , 量化分布距離 自我感知特征:裁判自身答案與候選答案的相似度 , 作為偏差預警信號
這些特征無需任何人工標注 , 完全從響應分布中自動構建 。
一個三層 MLP 網絡 fθ 隨后將特征映射到自適應參數:
實例級 K 因子 Kij:動態調整每輪比較的權重 , 可疑對決自動降權 軟標簽 (si sj):替代硬判決 , 緩解偏好噪聲 , 實現平滑更新
共識錨定:無監督對齊的基石
UDA 的核心創新是無監督的共識驅動訓練 。 在缺乏 \"黃金標準\" 的困境下 , UDA 將所有裁判的集體共識視為一個現實可用的優化目標 。 雖然共識并非完美真值 , 但實證表明 , 異質性偏差在聚合時傾向于相互抵消 。
訓練目標巧妙設計為多任務損失:
三項分別驅動:(i) 各裁判軌跡向共識收斂 , (ii) 保持排名相關性 , (iii) 強化集體一致性 。 最終 , UDA 不追求復制共識 , 而是以共識為錨 , 壓制極端個體偏好 。
理論動機:為什么共識對齊能減少偏差?
UDA 的核心理論洞見是:對齊多樣化裁判的共識 , 將降低系統總偏差 。
證明:設 Ri 為模型 i 的真實 Elo 分數 , ε(k) i 為裁判 k 的偏差項 。 在線性收縮模型下(實際情況當然會比該假設復雜 , 但這種趨勢是相同的) , UDA 對齊后的預期總絕對偏差不超過基線:
證明思路:對齊過程可視為向平均偏差的凸組合收縮 , 通過三角不等式和 Jensen 不等式即可得證 。 雖然個別校準良好的裁判可能輕微犧牲精度 , 但集體方差縮減主導了個體成本 。
這一理論為無監督對齊提供了動機:即使共識本身有噪聲 , 減少離散度仍能提升整體可信度 。
實驗結果
UDA 在 ArenaHard(500 問題 , 10 大模型 , 45 萬對比較)上訓練 , 在零樣本遷移中展現了非常好的效果:
主實驗
訓練集與測試集上不同大模型評估的方差:
測試集上評估結果與人類評估的相關性系數:
四大核心發現:
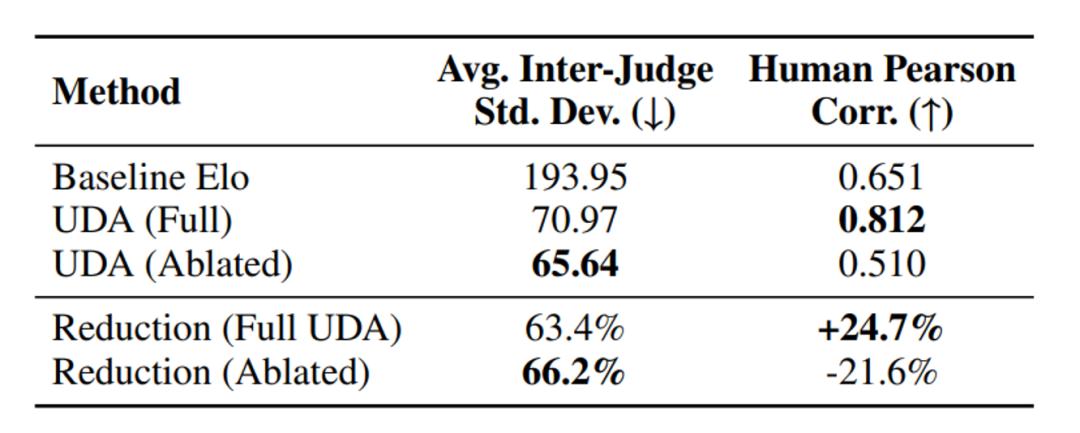
1. 跨模型方差銳減:UDA 將平均裁判間標準差從 158.5 降至 64.8(↓59%) , 最激進的 gemini-2.0-flash 偏差從 341.9 壓縮至 128.8 , 證明對極端偏差的強效抑制 。
2. 人類對齊躍升:在人工標注遷移集上 , UDA 將平均 Pearson 相關性從 0.651 提升至 0.812(+24.7%) , 將弱裁判(如 glm-4-flash)提升至與頂尖行列大模型(deepseek-r1)相當水平 , 實現評估民主化 。
3. 零樣本遷移穩?。 涸諼醇男碌那ㄒ剖菁?, UDA 未經重新訓練仍實現 63.4% 的方差縮減 , 證明領域無關的去偏能力 。
4. 自我感知特征的決定性:消融實驗顯示 , 移除大模型自身回答相關特征后 , 雖然方差進一步降至 65.64 , 但人類相關性暴跌至 0.510 。 這可能是因為缺乏自我意識的模型會盲目收斂 , 卻是卻偏離人類真值 。
消融研究:自我感知特征的關鍵作用
為驗證所選特征的必要性 , 該研究團隊訓練了 UDA(Ablated)變體 , 剔除所有與裁判自身答案相關的特征:
實驗結果顯示:剔除自我感知相關特征后 , 模型過度優化共識一致性 , 犧牲了人類對齊 。 自我感知特征如同 \"偏差鏡子\" , 讓裁判能識別并折扣自身偏好 , 從而引導集體判斷朝向客觀真值 。
總結
UDA 讓我們看到一個重要趨勢: \"評判校準不再是提示工程問題 , 而是可以被學習的問題 。 \" 通過無監督共識信號 , 模型不再依賴人工撰寫的去偏提示 , 而是在交互中自主演化出公平評分策略 。
【大模型作為評估者的「偏好」困境:UDA實現無監督去偏對齊】這項研究針對現有評估中不同 LLM 評委存在的系統性自偏好偏差以及評分不一致問題 , 通過輕量級神經網絡動態調整 Elo 評分系統的 K 因子與勝負概率 , 實現實例級別的去偏矯正正 。 其核心思想是將所有評委評分的集體共識作為無監督優化目標 , 通過最小化各評委 Elo 軌跡的離散度來抑制極端個性偏差 , 同時利用評委自身回答的語義等特征檢測自偏好傾向 。 該框架有效提升了低質量評委的表現 , 使其接近高質量評委水平 , 顯著增強了評估的魯棒性、可復現性與人類對齊度 。
推薦閱讀














- 電子科技大學提出基于雙路徑注意力干預多模態大模型物體幻覺緩解
- 80后諾獎得主:AlphaFold下一步融合大模型
- Adam的穩+Muon的快?華為諾亞開源ROOT破解大模型訓練的兩難困境
- 百度新設兩個大模型研發部:直接向CEO李彥宏匯報!
- 大模型C端之戰:App更名改命,硬件短兵相接
- 卡帕西大模型橫評方法太好玩!四大AI匿名參賽評分,最強出乎意料
- 大模型瘦身術:上交大團隊創新異構計算,實現GPU計算零等待
- AI安全新漏洞:一首詩就能攻破頂級大模型?
- 毫無預兆的,Gartner給大模型開發平臺排了座次
- 火山引擎多媒體實驗室提出VQ-Insight,AIGC視頻畫質理解大模型