
文章圖片
文章圖片

文章圖片

你或許遇到過這樣的場景:讓 AI 畫一張圖 , 對于圖片中要呈現的內容 , 你有著明確的數量和文字要求 。 比如你讓AI畫一張圖 , 包含1個蘋果、2根香蕉、3個桃子和4個柚子 , 并在每個水果下面寫上英語單詞和發音 。
但是 , 它要么數不對蘋果個數 , 要么文字寫成亂碼 , 要么畫風完全不對味 。 同樣是文生圖大模型 , 為什么有的像“聽話的設計師” , 有的只是“會臨摹的畫師”?問題根源 , 藏在模型的“底模”里 。 底模和架構 , 共同構建成了底層建筑 , 它直接決定了上層能力!
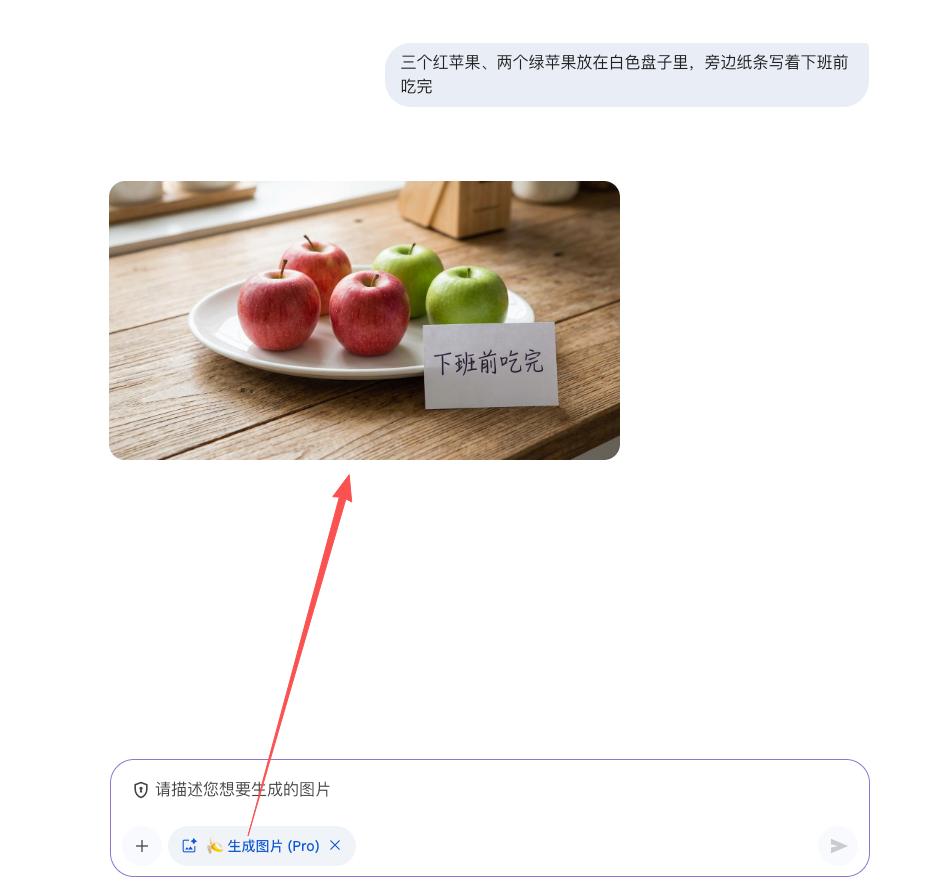
一、一個真實場景:當 AI 聽不懂人話場景一:你讓 AI 畫“三個紅蘋果、兩個綠蘋果放在白色盤子里 , 旁邊紙條寫著下班前吃完” 。
模型 A 可能給你六個蘋果 , 要么紙條上是亂碼 , 要么盤子變形 。 提示詞越細 , 它越懵 。模型 B 能準確畫出五個蘋果 , 顏色、字體、排版全對 , 甚至能理解“下班前”的傍晚氛圍 。模型 C 把蘋果畫得像照片 , 光影一流 , 但字可能有點小瑕疵 , 數量偶爾錯一個 。
場景二:把產品 3D 渲染圖改成“日落時分、北歐風木桌、配一杯咖啡” 。
模型 A 換了背景 , 但產品材質和光影完全對不上 。模型 B 能記住產品細節、logo , 環境和光影合理 , 像同一場景拍的 。模型 C 畫面電影感極強 , 但產品細節可能丟了一點 , 或者 logo 字體有點歪 。
為什么差距這么大?因為不同模型的“底模”在三個層次上的能力分配完全不同 。
二、“底模”的三層架構【AI 繪圖,怎么都畫不出你想要的?教你一招,全搞定!】想象你在管理一個設計團隊 , 團隊成員有三類角色:
第一層:世界知識庫 + 邏輯引擎(大腦層)
作用:理解 prompt 里每個詞的真實含義、關系、常識、物理規律 。
舉例:知道蘋果是圓的、會反光;明白三個紅蘋果加兩個綠蘋果等于五個;理解“下班前”是傍晚 , 光線要暖;能識別“公司 logo 不能被篡改” 。
技術:這不是 SDXL 那種小文本編碼器能做到的 。 它需要一個真正的大規模多模態大模型(VLM) , 比如 Nano Banana 用的 Gemini 2.5/3 Pro , FLUX.2 用的 Mistral3 24B 。
這一層決定了模型能不能聽懂人話 , 會不會犯常識性錯誤 。
第二層:圖像生成架構(畫手層)
作用:把大腦理解的畫面描述 , 一筆一筆在潛空間里畫出來 , 再解碼成像素 。
舉例:決定用什么筆觸、顏色、光影、材質;控制生成步數、效率、穩定性;處理高分辨率、多參考圖融合 。
技術:SDXL是 UNet 加傳統擴散 , 像臨摹 , 步數多 , 容易畫糊 。 FLUX.2是 Latent Flow Matching Transformer , 更像連續塑形 , 步數少 , 畫質高 。 Nano Banana 系列是原生多模態 Transformer 自帶圖像頭 , 大腦和畫手更一體化 。
這一層決定了畫得快不快、畫質精不精、風格像不像 。
第三層:微調、安全策略與生態(風格與合規層)
作用:讓模型在特定畫風、審美、安全合規上更專業 。
舉例:喂一萬張宮崎駿畫風 , 它就學會吉卜力;加上嚴格 NSFW 過濾 , 它就畫不出敏感內容;開放 API 和插件生態 , 開發者就能在上面蓋房子 。
技術:微調(Fine-tune)在底模基礎上用特定數據集繼續訓練 。 LoRA/Adapter 像給模型戴個風格帽子 , 輕量快速切換 。 安全策略包括審查規則、SynthID 水印、內容過濾 。
這一層決定了畫風是否對目標用戶胃口、能不能過審、好不好集成 。
三、三者如何配合畫圖?當你輸入 prompt , 模型內部是這樣的:
- 大腦層先解析:這是五個蘋果 , 紅綠分開 , 有文字 , 傍晚光線 , 盤子是白的 。
- 大腦層調用世界知識:蘋果的形狀、材質、反光特性;傍晚光線的色溫;紙條的排版邏輯 。
- 畫手層接手:在潛空間里構建場景結構 , 先放盤子 , 再擺蘋果 , 再調整光影 , 最后渲染材質 。
- 風格層收尾:根據微調過的審美偏好 , 決定是寫實風還是插畫風;根據安全策略 , 檢查有沒有違規元素 。
大家應該對于AI繪畫能力差異的底層邏輯 , 有個大概的了解了對吧 。 說到這兒 , 順便提一嘴:我前天的文章()也提到 , 大家千萬不要覺得AI繪圖模型只能畫畫 , 干不了別的 。 所以你畫畫的時候 , 先用別的模型確認prompt提示詞 , 再到繪畫模型里畫畫 , 這是錯的!以NanoBanana為例 , 它的推理模型時Gemini3 , 這么強大你還用啥別的模型 , 繪畫需求、反推prompt提示詞 , 都直接跟NanoBanana聊 , 最后直接讓它畫就完了 , 一條龍搞定!
四、為什么有的模型聰明 , 有的只是手巧?Nano Banana vs FLUX.2把兩個明星模型套進三層框架 , 差異一目了然:
| 對比維度 | Nano Banana Pro | FLUX.2 |
| 大腦層 | 極強:Gemini 3 Pro 原生多模態 , 懂邏輯、計數、圖表、角色身份 | 較強:Mistral3 24B 提供 , 但 Flow 架構更側重畫質 |
| 畫手層 | 一體化設計 , 側重結構正確性與文本渲染 , 4K 輸出穩定 | Latent Flow Matching , 步數少 , 畫質與光影極具電影感 |
| 風格與合規層 | 閉源加強審查 , SynthID 水印 , 審美偏通用品牌安全 | 開源生態加靈活審查 , 社區 LoRA 活躍 , 亞文化審美更自由 |
| 結論 | 聰明的設計師:聽懂復雜需求 , 出圖結構準、文字對 , 適合商業內容 | 手巧的藝術家:出圖驚艷、風格靈活、成本低 , 適合創意探索 |
五、實用技巧:能力不夠 , JSON 來湊!通過上面的解釋 , 相信大家已經知道了 , AI繪圖軟件的工作原理 。 其實它就像一場接力賽一樣 , 你的prompt提示詞就是第一棒 , 它的理解是第二棒 , 最后的繪畫是第三棒 。
當然每一棒都很關鍵 , 但是最最關鍵的 , 還是第一棒!
所以 , 如果你對于大模型沒信心 , 或者你對于自己的表述沒信心 , 再或者 , 你就是希望找到一種能精準繪畫、少出錯的捷徑 , 當然是有的 , 我給你的推薦就是:使用JSON prompt 提示詞!
為什么?
如果大家稍微懂點技術 , 就知道 , 我們跟各種App交互的 , 本質上就是輸入和輸出 , 我們負責輸入 , 它們負責輸出 。 而我們的輸入是多種多樣的 , 有文字、圖片、聲音、視頻、點擊等等 , 這些輸入它們是無法直接理解的 , 都要先進行轉義 , 就是要轉義為機器、系統能理解的語言和指令 , 然后再去執行和反饋 。
所以我們輸入prompt提示詞也是一樣的 , 由于我們是大白話輸入 , 程序在理解的過程中 , 極大概率就會因為各種原因產生偏差 , 再加上它可能本來的模型能力就不高 , 那第一棒及一二棒交接就可能會有很大的偏差 。 進而傳到到第二棒和第三棒 , 最后出來的結果 , 可能跟我們想要的就會大相徑庭 。
因此呢 , 一個相對能簡單解決模型理解問題的方式 , 就是我們把prompt提示詞 , 以JSON格式的形式進行輸入 。
寫過代碼的朋友一定知道 , 我們開發各種app的時候 , 經常涉及到函數的傳參 , 而參數格式 , 我們最常使用的就是JSON 。 沒錯 , 這是非常高效的一種輸入輸出 。
不廢話 , 給你們看一張給常復雜的圖片↓
上圖 , 強如NanoBanana , 你如果用大段的大白話輸入 , 也要抽好幾次 , 但是如果用JSON格式輸入提示詞 , 那么NanoBanana可以說基本就信手拈來了 。 上圖prompt提示詞如下:
(直接粘貼效果很亂 , 我就貼圖了 , 想要原prompt提示詞 , 下面mark一下我會發你)
再給你們看幾張 , 其實這個圖最近很流行 , 我覺得喜歡時尚喜歡拍照的妹子們 , 可以搞一波↓
最后再提醒一點:我教大家使用JSON優化輸出這一招 , 有用 , 但不是根本解決方案 。 治本之道 , 還是選大腦層強的模型 , 這一點大家還是要明確 。
\u0002\u0002\u0002\u0002
推薦閱讀











- 超級VIP誰都要討好:NVIDIA表示顯存供應充足
- 王自如:iPhone 17一點兒都不蘋果 不是設計師設計出來的
- 蘋果造芯五年,Mac 怎么成了另一種電腦?|明日后視鏡
- 一場專利訴訟,為何英飛凌和英諾賽科都說自己贏了?
- 硅谷商戰變廚藝大賽?小扎曾親手煮湯挖人,OpenAI 說不慌都是演的
- 原來這屆中國AI年輕人,已經卷到業界都驚了
- 內存芯片吃獨食,手機、晶圓,PC、屏幕等等,都在被它吸血
- 不止 Sora2!拍我AI V5.5 更新:人人都能用 AI 視頻當導演了
- Runway Gen-4.5刷屏發布,把重量塵土和光影都做對了,網友:顛覆
- 30年數學難題,AI僅6小時告破!陶哲軒:ChatGPT們都失敗了