智能體如何學會想象?深度解析世界模型嵌入具身系統三大技術范式

文章圖片

文章圖片

文章圖片
長期以來 , 具身智能系統主要依賴「感知 - 行動」的反應式回路 , 缺乏對未來的預測能力 。 而世界模型的引入 , 讓智能體擁有了「想象」未來的能力 。
具身智能機器人通過世界模型想象抓杯子任務
那么關鍵問題來了:世界模型應該如何「放進」具身系統中?是作為一個獨立的模擬器?還是作為策略網絡的一部分?
近日 , 依托北京中關村學院 , 來自中科大、哈工大、南開大學、清華大學、寧波東方理工大學等機構的研究團隊發布了一篇全面綜述 , 首次從架構集成(Architectural Integration) 的視角 , 將現有研究劃分為三大范式 。
- 論文標題: Integrating World Models into Vision Language Action and Navigation: A Comprehensive Survey
- 原文鏈接: https://doi.org/10.36227/techrxiv.176531987.77979037/v1
本文將帶你一覽這篇硬核綜述的核心精華 。
基于世界模型的具身智能體框架
為什么具身智能需要「世界模型」?
【智能體如何學會想象?深度解析世界模型嵌入具身系統三大技術范式】在 LLM 爆發之前 , 具身指令跟隨系統通常將語言、感知和動作視為分離的組件 。 雖然端到端(End-to-End)模型不僅簡化了流程 , 但純反應式(Reactive)的方法面臨兩大瓶頸:
- 缺乏前瞻性: 無法預測未來狀態 , 難以處理長程規劃任務;
- 泛化性差: 難以適應未見過的環境或任務配置 。
世界模型的核心思想源于認知科學:人類不僅是對刺激做出反應 , 更是在腦海中構建了一個能夠預測未來的「內部模型」 。 引入世界模型 , 能為具身智能體帶來樣本效率提升、長程推理能力、安全性增強以及主動規劃能力 。
人類認知科學 → 具身智能的世界模型
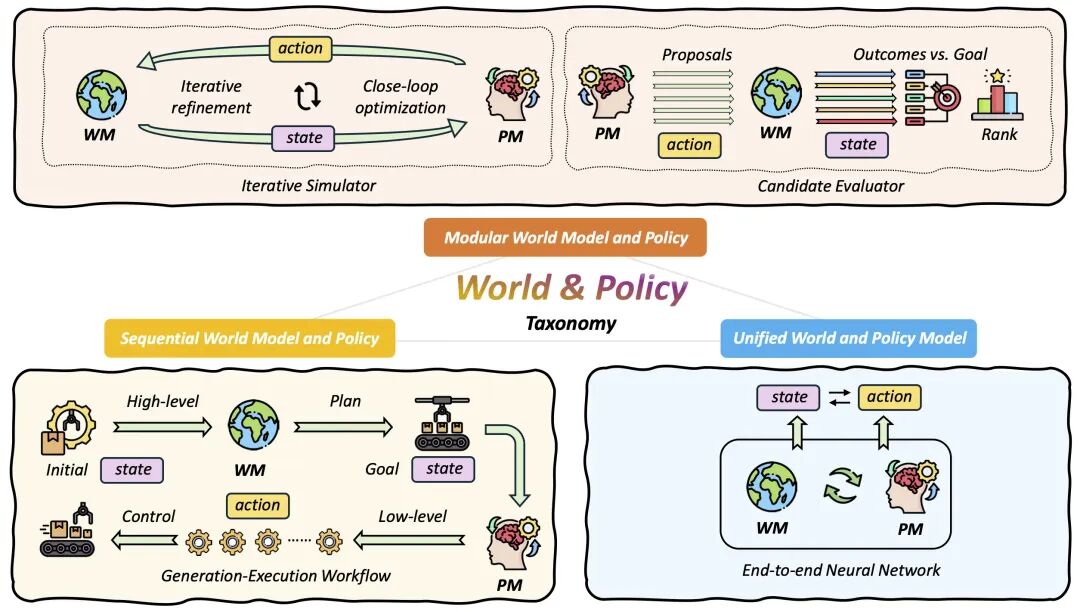
核心分類:三種架構融合范式
作者認為 , 世界模型(World Model WM)與策略(Policy or Policy Model PM)之間的架構關系 , 其實可以看作是一條「耦合強度光譜」 。 簡單來說 , 不同方法在多大程度上讓「世界模型」和「策略」互相依賴、互相影響 , 是可以從弱到強排成一條線的 。 作者將這種耦合強度分成兩個相互獨立的維度來理解:
- 梯度流動(G:Gradient Flow):策略的優化目標產生的梯度 , 能不能直接反向傳播到世界模型里 , 從而更新 WM 的參數?
- 信息依賴(I:Information Dependency):在推理的一個前向過程中 , 策略輸出動作時 , 是否顯式依賴于世界模型預測的狀態?也就是 , 策略做決策的時候 , 是不是「要先看看世界模型怎么預測下一步世界會怎樣」 。
深度拆解:三種范式的權衡與博弈
分類架構圖
范式一:模塊化架構 (Modular Architecture)
關鍵詞:獨立、互操作、弱耦合
模塊化架構將世界模型和策略作為兩個獨立的單元 , 二者之間沒有梯度流動 , 策略輸出動作時也不依賴于未來狀態 。 世界模型在這個架構中作為世界模擬器 , 關注動作與狀態間的因果變化 。
在這樣的設計中 , 世界模型更像是一個「思考環境的內在模擬器」 。 給定當前觀察(或抽象狀態)以及候選動作 , 世界模型會根據學習到的因果規律預測下一個狀態 —— 可以是像素級的圖像 , 也可以是結構化的潛空間表示 。 這讓智能體能夠在內部「根據動作預演未來」:如果現在采取某個動作 , 會發生什么?這種能力讓策略模型能夠更好地判斷哪些動作可行、哪些風險更大以及哪些方案能帶來長遠收益 。
范式二:順序架構 (Sequential Architecture)
關鍵詞:分層、意圖生成、中等耦合
順序化架構先利用世界模型預測出未來狀態 , 策略基于該未來狀態預測未來動作 。 在該架構中 , 梯度傳遞分為兩個階段 , 第一階段由世界模型預測未來狀態的訓練目標決定 , 用于優化世界模型參數;第二階段由策略輸出動作的訓練目標決定 , 用于統一優化世界模型和策略參數 。 在該范式中 , 世界模型作為決策生成器 , 它的核心任務 , 是為智能體生成一個未來的目標狀態 , 并把復雜的長時序任務拆分成兩個更容易解決的子問題:
1. 生成一個有價值的目標(Goal Generation)
2. 根據目標執行行動(Goal-conditioned Execution)
在這種框架中 , 世界模型負責「想象」一個有意義的終點 , 例如未來的視覺觀察、場景狀態或抽象規劃;而真正找到抵達該目標的行動序列 , 則由底層模塊完成 , 比如逆動力學模型或點目標控制器 。
換句話說 , 世界模型最重要的貢獻 , 就是生成一個「夠好」的目標 , 從而讓后續的控制問題變得更簡單 。
范式三:統一架構 (Unified End-to-End Architecture)
關鍵詞:端到端、聯合優化、強耦合
統一架構則將世界模型和策略集成到一個端到端網絡當中 。 在這一配置下:
1. 世界模型不再單獨負責預測未來、建模環境;
2. 策略模型也不再單獨負責決策與行動生成 , 兩者被融合為一個統一的大網絡 , 共同參與訓練、共同被優化 。
整個模型在同一個損失目標下進行端到端訓練 , 使網絡能夠在同一條計算路徑中:
1. 預測未來狀態(anticipate future states)
2. 輸出合適的動作(produce appropriate actions)
這意味著智能體不再需要顯式地區分「模擬」與「決策」兩個步驟 , 而是在統一的結構中自然涌現出這兩項能力 。
未來展望:通往通用具身智能之路
綜述最后指出了幾個極具潛力的研究方向 :
1. 世界模型的表征空間選擇與耦合:視覺空間具備語義豐富度 , 但成本高且穩定性弱;狀態空間更緊湊高效 , 但表達能力似乎有限 。 未來趨勢是融合二者 , 通過統一潛變量實現表達能力與推理效率的平衡 , 為跨任務泛化奠基 。
2. 世界模型的想象應該是結構化意圖的生成與表達:未來的世界模型應生可解釋的未來結構(目標、軌跡、成因、時空信息等表征) , 而非僅預測下一步狀態 , 并且是其是否具備可約束的、物理一致的想象結構 , 可指導跨任務遷移并促進策略有效泛化 。 未來應該加入與語言和符號推理結合 , 若想象可在語言或符號空間中表達 , 則世界模型能夠顯式刻畫任務分解、物體關系與因果依賴 , 而這些信息在像素預測中沒有被直觀的表達和理解 。
3. 世界模型表征和想象對于指導具身智能的脆弱性:想象與執行解耦帶來可理解性提升 , 但也可能產生超出具身本體能力的目標 。 未來研究重點是引入可達性判別、可行性過濾、物理一致性評估 , 以降低失效風險 。 另外 , 通過顯式分離想象與控制 , 系統暴露中間表征 , 如目標假設、潛在軌跡、視覺推演等 , 使調試、干預和人類理解更加容易 。 但若模塊間缺乏對齊機制 , 也可能削弱終端性能 , 因此解釋性與最優性存在固有權衡 。
4. 統一的世界 - 策略模型構建范式:大規模預訓練模型天然具備世界建模與策略生成潛力 , 未來需探索如何以最小代價將其轉化為統一決策系統 , 關鍵難點在于狀態空間對齊、表示粒度選擇、避免視覺或語言表征偏置 , 構建有效、高效的統一世界 - 策略模型范式 。
推薦閱讀












- AI開始「內卷」?騰訊混元和上交聯合揭秘多智能體「饑餓游戲」
- 聯想天禧AI生態伙伴大會定檔26日 聚焦智能體發展,共啟新生態
- 英特爾酷睿Ultra第三代,如何推動AI PC規模化落地?
- TCL Q9M是如何解決技術頑疾,還將RGB-MiniLED價格打入萬元內的?
- 北京人形開源首個通過具身智能國標測試的具身大模型XR-1
- 自變量王潛:具身智能是物理世界的獨立基礎模型|MEET2026
- 多款Intel Panther Lake筆記本集體現身!起價7000元
- 國家人工智能應用中試基地(醫療)·浙江發布年度成果
- 管理AI智能體員工隊伍所需的8項核心技能
- 存儲集成問題如何破壞基礎設施自動化