文章插圖
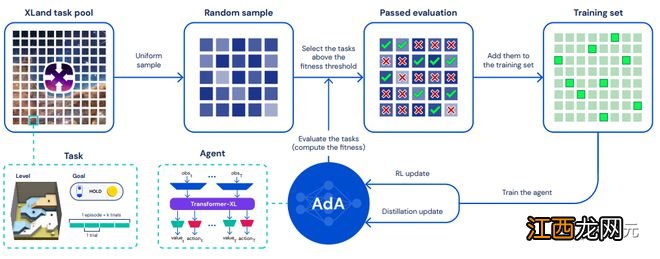
該訓(xùn)練方法結(jié)合了三個(gè)關(guān)鍵部分:1)指導(dǎo)智能體學(xué)習(xí)的課程(curriculum);2)基于模型的RL算法來(lái)訓(xùn)練具有大規(guī)模注意力記憶的代理;以及,3)蒸餾以實(shí)現(xiàn)擴(kuò)展 。
1. 開(kāi)放端任務(wù)空間:XLand 2.0
XLand 2.0相比XLand 1.0擴(kuò)展了生產(chǎn)規(guī)則的系統(tǒng),其中每條規(guī)則都表達(dá)了一個(gè)額外的環(huán)境動(dòng)態(tài),從而具有更豐富、更多樣化的不同過(guò)渡功能 。
XLand 2.0是一個(gè)巨大的、平滑的、多樣化的適應(yīng)問(wèn)題的任務(wù)空間,不同的任務(wù)有不同的適應(yīng)性要求,如實(shí)驗(yàn)、工具用法或分工等 。
例如 , 在一個(gè)需要實(shí)驗(yàn)的任務(wù)中,玩家可能需要識(shí)別哪些物體可以有用地結(jié)合,避免死胡同,然后優(yōu)化他們結(jié)合物體的方式,就像一個(gè)玩具版的實(shí)驗(yàn)化學(xué) 。

文章插圖
每個(gè)任務(wù)可以進(jìn)行一次或多次試驗(yàn),試驗(yàn)之間的環(huán)境會(huì)被重置,但智能體記憶不會(huì)被重置 。
上圖中突出顯示的是兩個(gè)示例任務(wù),即「Wrong Pair Disappears」和「Pass Over Wall Repeatedly」,展示了目標(biāo)、初始物體、生產(chǎn)規(guī)則以及智能體需要如何與它們互動(dòng)以解決任務(wù) 。
2. 元強(qiáng)化學(xué)習(xí)
根據(jù)黑箱元RL問(wèn)題的設(shè)置,研究人員將任務(wù)空間定義為一組部分可觀察的馬爾科夫決策過(guò)程(POMDPs) 。
對(duì)于一個(gè)給定的任務(wù),試驗(yàn)的定義為從初始狀態(tài)到終端狀態(tài)的任意轉(zhuǎn)換序列 。
在XLand中,當(dāng)且僅當(dāng)某個(gè)時(shí)間段∈[10s, 40s]已經(jīng)過(guò)去時(shí) , 任務(wù)才會(huì)終止,每個(gè)任務(wù)都有具體規(guī)定 。環(huán)境以每秒30幀的速度變化 , 智能體每4幀觀察一次 , 因此任務(wù)長(zhǎng)度以時(shí)間為單位,范圍為[75, 300] 。
一個(gè)episode由一個(gè)給定任務(wù)的試驗(yàn)序列組成 。在試驗(yàn)邊界,任務(wù)被重置到一個(gè)初始狀態(tài) 。
在領(lǐng)域內(nèi) , 初始狀態(tài)是確定的,除了智能體的旋轉(zhuǎn),它是統(tǒng)一隨機(jī)抽樣的 。
在黑箱元RL訓(xùn)練中,智能體利用與廣泛分布的任務(wù)互動(dòng)的經(jīng)驗(yàn)來(lái)更新其神經(jīng)網(wǎng)絡(luò)的參數(shù),該網(wǎng)絡(luò)在給定的狀態(tài)觀察中智能體的行動(dòng)政策分布提供參數(shù) 。
如果一個(gè)智能體擁有動(dòng)態(tài)的內(nèi)部狀態(tài)(記憶),那么元RL訓(xùn)練通過(guò)利用重復(fù)試驗(yàn)的結(jié)構(gòu),賦予該記憶以隱性的在線學(xué)習(xí)算法 。
在測(cè)試時(shí) , 這種在線學(xué)習(xí)算法使智能體能夠適應(yīng)其策略,而無(wú)需進(jìn)一步更新神經(jīng)網(wǎng)絡(luò)權(quán)重 , 也就是說(shuō),智能體的記憶不是在試驗(yàn)邊界被重置,而是在episode邊界被重置 。
3. 自動(dòng)課程學(xué)習(xí)(Auto-curriculum learning)
鑒于預(yù)采樣任務(wù)池的廣度和多樣性,智能體很難用均勻采樣進(jìn)行有效地學(xué)習(xí):大多數(shù)隨機(jī)采樣的任務(wù)可能會(huì)太難(或太容易),無(wú)法對(duì)智能體的學(xué)習(xí)進(jìn)度有所幫助 。
相反,研究人員使用自動(dòng)化的方法在智能體能力的前沿選擇相對(duì)「有趣 」(interesting)的任務(wù),類似于人類認(rèn)知發(fā)展中的「近側(cè)發(fā)展區(qū)間」(zone of proximal development) 。
具體方法為對(duì)現(xiàn)有技術(shù)中的no-op filtering和prioritised level replay(PLR)進(jìn)行擴(kuò)展,能夠極大提升智能體的性能和采樣效率,最終成為了一個(gè)新興的課程,能夠隨著時(shí)間的推移選擇越來(lái)越復(fù)雜的任務(wù) 。
4. RL智能體
學(xué)習(xí)算法
RL算法選擇Mueslie,輸入為一個(gè)歷史相關(guān)的編碼(history-dependent encoding),輸出為RNN或Transformer,AdA學(xué)習(xí)一個(gè)序列模型(LSTM)對(duì)后續(xù)多步預(yù)測(cè)價(jià)值、行動(dòng)分布和獎(jiǎng)勵(lì) 。

文章插圖
記憶架構(gòu)
在每個(gè)時(shí)間步,將像素觀察、目標(biāo)、手、試驗(yàn)和時(shí)間信息、生成規(guī)則、之前的行動(dòng)和獎(jiǎng)勵(lì)嵌入化并合并為一個(gè)向量 。
相關(guān)經(jīng)驗(yàn)推薦
















- 怎樣教孩子學(xué)習(xí)繪畫 如何教孩子學(xué)習(xí)繪畫
- 怎么能讓孩子主動(dòng)學(xué)習(xí)
- 一輪復(fù)習(xí)地理學(xué)習(xí)重點(diǎn) 有哪些重點(diǎn)地理知識(shí)點(diǎn)
- 《仙樂(lè)傳說(shuō)加強(qiáng)版》游戲強(qiáng)化功能和畫面參數(shù)公布
- 松乳菇的種植技術(shù)在哪里可以學(xué)習(xí)
- 對(duì)話華創(chuàng)資本合伙人熊偉銘:冰封重啟,2023年投資市場(chǎng) “有風(fēng)景也有迷霧”
- 孩子怎樣才能學(xué)習(xí)好
- 學(xué)習(xí)書法的好處有哪些?,學(xué)書法的好處是什么?
- 怎么學(xué)習(xí)溫室工程
- 古人也有食物造假嗎,古代怎么監(jiān)管食品安全