
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
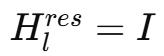
文章圖片
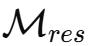
文章圖片
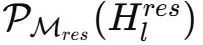
文章圖片
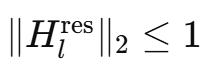
文章圖片
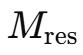
文章圖片
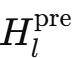
文章圖片
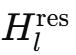
文章圖片
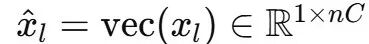
文章圖片
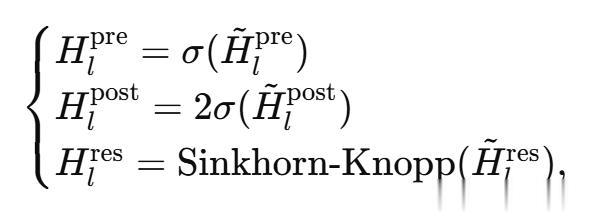
文章圖片
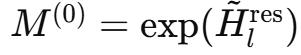
文章圖片
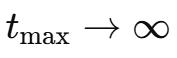
文章圖片
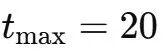
文章圖片
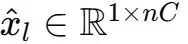
文章圖片
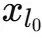
文章圖片
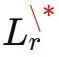
文章圖片
文章圖片
文章圖片
文章圖片
編輯:編輯部
【新智元導讀】2026新年第一天 , DeepSeek發表了梁文鋒署名的重磅新論文 , 提出了一種名為「mHC(流形約束超連接)」的新架構 , 在27B參數模型上 , 僅增加約6.7%的訓練時間開銷 , 即可實現顯著性能提升 。
重磅!
剛剛 , DeepSeek送上2026年新年第一個王炸 。
這次的創新是 , mHC(流形約束超連接)新架構 。
【剛剛,DeepSeek扔出大殺器,梁文鋒署名!暴力優化AI架構】
標題:mHC:Manifold-Constrained Hyper-Connections
鏈接:https://arxiv.org/abs/2512.24880
在這篇論文中 , DeepSeek提出了流形約束超連接(mHC) , 將矩陣投影到約束流形上優化殘差連接空間 , 從而確保穩定性 , 徹底顛覆了傳統AI架構認知——
可以擴大殘差流通道寬度(residual stream width) , 而在算力和內存上的代價卻微乎其微 。
圖1: 殘差連接范式示意圖
繼Hyper-Connections(HC)開辟「殘差連接寬度可擴展」路線之后 , mHC直接把這一思路推上實用化的快車道 。
DeepSeek這次直擊AI痛點 , 給同行上了一課!
值得一提的是 , 這次梁文鋒署名 , 但解振達、韋毅軒、Huanqi Cao為核心貢獻者 , 解振達為通訊作者 。
DeepSeek , 或敲響ResNet喪鐘
這簡直是為「模型優化玩家」量身打造的王牌秘方 。
過去 , 超連接(hyper-connections)更多只是學術圈的小眾嘗試 。
而現在 , DeepSeek直接把它升級為基礎架構的核心設計要素 。
這也正是擁躉一直以來對DeepSeek的期待:數學上的洞察力+硬件層面的極致優化 。
頂級大語言模型(LLM)中 , ResNet結構或許即將被淘汰 。
畢竟 , 殘差流通道寬度一直是擴展模型的「煩人瓶頸」 。
這波操作 , 也再次展現了DeepSeek典型的風格:對同行的溫和降維打擊——
你們兩年時間都在打磨微結構 , 調整DS-MoE?挺可愛哈 。 來看看我們怎么玩:把一個理論上看起來還不夠成熟的高級原語 , 直接做實 , 順手解鎖游戲下一關 。
他們在論文中寫道:「我們的內部大規模訓練實驗進一步驗證了mHC在大規模應用中的有效性 。 」
這句話在DeepSeek的原生稀疏注意力(Natively trainable Sparse Attention , NAS)那篇論文里可沒有 。
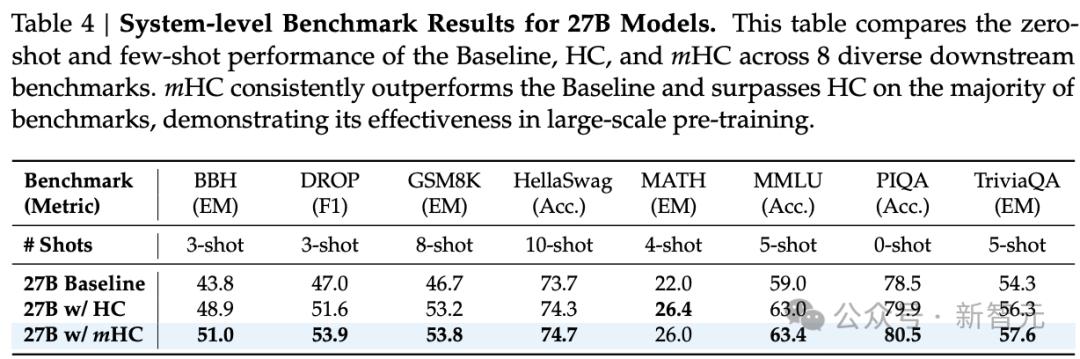
在27B模型的系統級基準測試結果中 , 新架構mHC在絕大多數基準測試中持續超越基線模型并優于HC , 這證明其在大規模預訓練中的有效性 。
換句話說 , DeepSeek信心十足 , 不怕同行知道自己的「殺招」 。
這給了DeepSeek的鐵粉Teortaxes很大信心 , 他有九成把握:mHC會進入DeepSeek V4 。
核心方法
Manifold-Constrained Hyper-Connections (mHC)
這個方法的關鍵目標 , 就是在Hyper-Connections的拓撲設計下恢復身份映射屬性 。 這樣 , 就可以在大規模訓練與現實基礎模型任務中體現實際價值 。
mHC與傳統殘差連接和HC的根本差異在于:傳統殘差連接只保留簡單的輸入 + 輸出形式(穩定但表達受限);Hyper-Connections (HC) 強化連接能力 , 但犧牲了穩定性與效率 。
而mHC的思路是:將Hyper-Connections的參數空間約束到特定的流形(manifold)上 , 以恢復恒等映射結構 。
技術細節
受恒等映射原則的啟發 , mHC的核心思想是在一個特定流形上對殘差映
進行約束 。 盡管原始的恒等映射通過強制
來保證訓練穩定性 , 但這種做法從根本上阻斷了殘差流內部的信息交互 , 而這種交互對于充分發揮多流(multi-stream)架構的潛力至關重要 。
因此 , 作者提出將殘差映射投影到一個既能維持跨層信號傳播穩定性、又能促進殘差流之間相互作用的流形上 , 從而在保證穩定性的同時保留模型的表達能力 。
為此 , 他們將
約束為雙隨機矩陣 , 即矩陣元素非負 , 且每一行與每一列的元素之和均為 1 。
形式化地 , 記
為雙隨機矩陣所構成的流形(亦稱Birkhoff多面體) , 將
約束在其投影
上 , 其定義為:
需要注意的是 , 當n=1時 , 雙隨機條件會退化為標量1 , 從而恢復為原始的恒等映射 。 選擇雙隨機性能夠帶來若干對大規模模型訓練具有重要意義的嚴格理論性質:
1.保范性:雙隨機矩陣的譜范數有上界 1 , 即
。
這意味著該可學習映射是非擴張的 , 從而能夠有效緩解梯度爆炸問題 。
2.組合閉包性:
雙隨機矩陣集合在矩陣乘法下是封閉的 。 這保證了跨越多層的復合殘差映射
仍然是雙隨機的 , 從而在整個模型深度范圍內保持穩定性 。
3.通過Birkhoff多面體的幾何解釋:
集合
構成Birkhoff多面體 , 即置換矩陣集合的凸包 。
這提供了清晰的幾何直觀:殘差映射可以被看作是若干置換的凸組合 。
從數學上看 , 此類矩陣的反復作用會單調地增強不同信息流之間的混合程度 , 從而有效地充當一種魯棒的特征融合機制 。
參數化與流形投影
在本節中 , 作者詳細介紹了mHC中
、
以及
的計算過程 。
給定第l層的輸入隱藏矩陣
, 首先將其展平成向量
, 以保留完整的上下文信息 。 隨后 , 遵循原始HC的建模方式 , 得到動態映射和靜態映射 , 具體如下:
隨后 , 通過如下方式得到最終滿足約束的映射:
其中 ,
表示Sigmoid函數 。
Sinkhorn–Knopp(?) 算子首先通過指數運算保證所有元素為正 , 然后執行交替的迭代歸一化過程 , 使矩陣的行和列分別歸一到1 。
具體而言 , 以正矩陣
作為初始值 , 歸一化迭代過程為:
隨著迭代次數增加 , 當
時 , 該過程收斂到一個雙隨機矩陣
。
在實驗中 , 取
作為一個實用的近似值 。
高效的基礎設施設計
通過一系列嚴格的工程優化 , 作者成功將mHC(取n=4)部署到大規模模型中 , 訓練開銷僅增加約 6.7% 。
內核融合
作者觀察到 , 在mHC中 , 當對高維隱藏狀態
進行操作時 , RMSNorm會帶來顯著的延遲 。
為此 , 他們將「除以范數」的操作重新排序 , 使其發生在矩陣乘法之后 。 該優化在數學上是等價的 , 但在工程實現上顯著提升了效率 。
此外 , 我們采用混合精度策略 , 在不犧牲計算速度的前提下最大化數值精度 , 并將多個具有共享內存訪問模式的算子融合為統一的計算內核 , 以降低內存帶寬瓶頸 。
基于公式(10)至(13)中給出的輸入與參數設置 , 作者實現了三個專用的 mHC計算內核 。
利用上述內核計算得到的系數 , 他們又引入了兩個額外的計算內核來應用這些映射 。
該框架能夠簡化復雜計算流程內核的實現 , 并在較小工程代價下充分發揮內存帶寬的潛力 。
重計算
n路殘差結構在訓練過程中會引入顯著的內存開銷 。
為緩解這一問題 , 作者在前向傳播結束后丟棄mHC內核產生的中間激活 , 并在反向傳播階段通過重新執行mHC內核(不包含計算量較大的層函數F)來即時重計算這些激活 。
因此 , 對于連續的L_r個層組成的一個模塊 , 只需存儲第一層的輸入
。
在忽略輕量級系數、同時考慮到F中的pre-norm開銷后 , 表3總結了在反向傳播中需要保留的中間激活以及在L_r個連續層中被重計算的瞬時激活 。
隨后 , 他們通過最小化與L_r對應的總內存占用來確定最優的塊大小
。
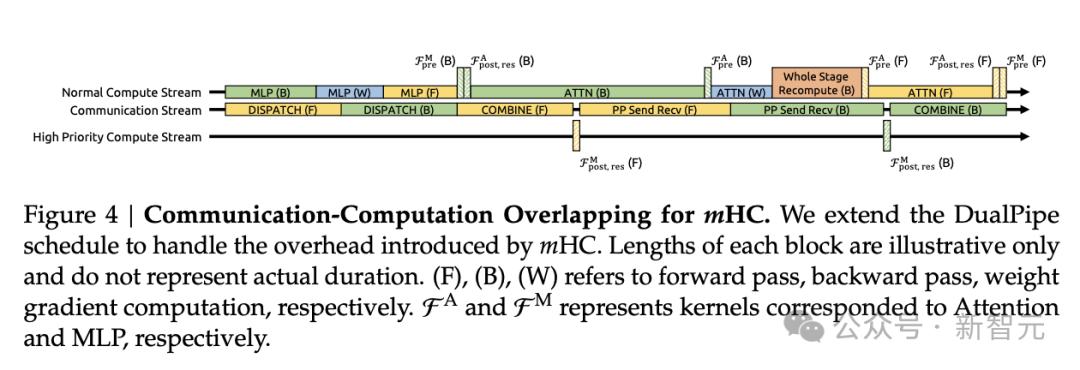
DualPipe中的通信重疊
在大規模訓練中 , 流水線并行(pipeline parallelism)是緩解參數與梯度內存占用的標準實踐 。
具體而言 , 他們采用了DualPipe調度策略 , 該策略能夠有效地重疊跨節點(scale-out)的互連通信流量 , 例如專家并行與流水線并行中的通信開銷 。
然而 , 與單流(single-stream)設計相比 , mHC中提出的n-流殘差結構會在流水線階段之間引入顯著的通信延遲 。
此外 , 在階段邊界處 , 對所有Lr層重新計算mHC內核也會帶來不可忽略的計算開銷 。 為了解決這些瓶頸 , 作者對DualPipe調度進行了擴展(見下圖) , 以在流水線階段邊界實現更高效的通信與計算重疊 。
原文圖4:mHC的通信–計算重疊機制 。
具體而言 , 為避免阻塞通信流 , 他們把MLP(即FFN)層的
內核放置在一個獨立的高優先級計算流上執行 。
同時 , 在注意力層中 , 他們刻意避免使用長時間運行的持久化內核(persistent kernels) , 以防止產生長時間的停頓 。
該設計允許對已重疊的注意力計算進行搶占 , 從而在保持計算設備處理單元高利用率的同時 , 實現更加靈活的調度 。
此外 , 重計算過程被與流水線通信依賴解耦 , 這是因為每個階段的初始激活x0l已經被緩存在本地 。
實驗結果
DeepSeek團隊首先檢驗了27B模型的訓練穩定性和收斂性 。
如下圖(a)所示 , mHC有效緩解了在HC中觀察到的訓練不穩定性 , 相比基線最終降低了0.021的損失 。
下圖(b)中的梯度范數分析 , 進一步證實了這種改善的穩定性 , 表明mHC展現出顯著優于HC的穩定性 , 與基線相當 。
原文圖5: 流形約束超連接(mHC)的訓練穩定性 , 展示了 (a) mHC與HC相對于基線的絕對訓練損失差距 , 以及 (b) 三種方法的梯度范數 。 所有實驗均采用27B模型 。
在多樣化基準測試集上 , mHC全面提升了下游性能 , 在所有任務上持續超越基線 , 并在大多數任務上優于HC 。
值得注意的是 , 與HC相比 , mHC進一步增強了模型的推理能力 , 在BBH上實現了2.1%的性能提升 , 在DROP上實現了2.3%的提升 。
這證明其在大規模預訓練中的有效性 。
原文表4:27B模型的系統級基準測試結果 。本表比較了基線、HC和mHC在8個不同下游基準測試中的零樣本和少樣本性能 。
為了評估方法的擴展性 , DeepSeek報告了mHC在不同規模下相比基線的相對損失改進 。
結果表明 , 即使在更高的計算預算下 , mHC依然穩健保持性能優勢 , 僅輕微衰減 。
此外 , 研究團隊考察了訓練過程中的動態變化 , 展示了3B模型的token擴展曲線 。
綜合來看 , 這些發現驗證了mHC在大規模場景下的有效性 。 這一結論得到了我們內部大規模訓練實驗的進一步證實 。
原文圖6:mHC相比基線的擴展特性 。(a) 計算擴展曲線:實線展示了不同計算預算下的性能差距 。 每個點代表模型大小和數據集大小的特定計算最優配置 , 從3B和9B擴展到27B參數 。 (b) Token擴展曲線:3B模型在訓練期間的軌跡 。 每個點代表模型在不同訓練token數下的性能 。
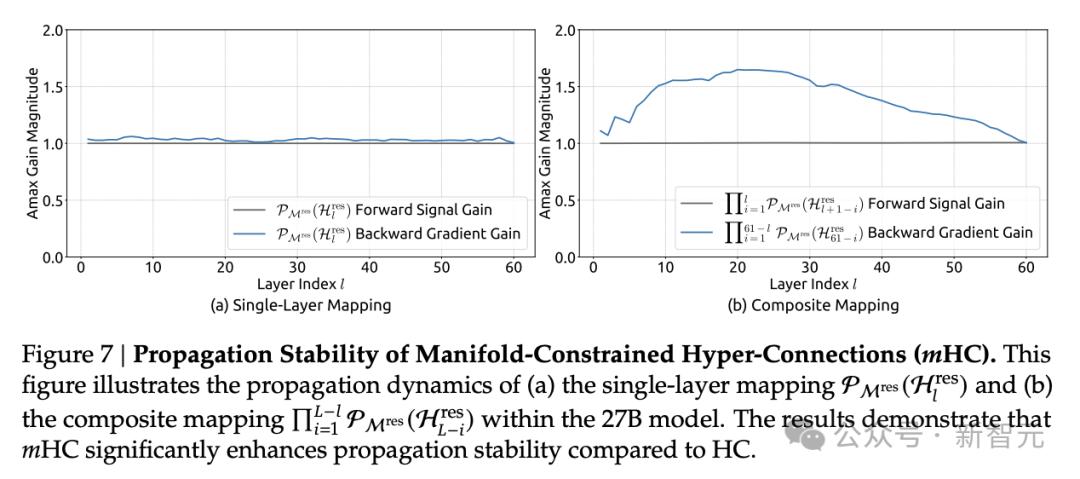
理想情況下 , 單層映射應滿足雙隨機約束 , 即前向信號增益與后向梯度增益均等于1 。
然而 , 為提升計算效率 , 實際實現中使用的Sinkhorn-Knopp算法必須限制迭代次數 , 這次實驗中為20次 。
因此 , 如下圖(a)所示 , 后向梯度增益會略微偏離1 。 在下圖(b)所示的復合映射情況下 , 偏離有所增加但仍保持有界 , 最大值約為1.6 。
原文圖7:流形約束超連接(mHC)的傳播穩定性 。本圖展示了27B模型中 (a) 單層映射與 (b) 復合映射 的傳播動態
值得注意的是 , 與HC中近3000的最大增益幅度相比 , mHC將其降低了三個數量級 。
這些結果表明 , mHC相比HC顯著增強了傳播穩定性 , 確保了前向信號與后向梯度的穩定流動 。
此外 , 團隊觀察到 , 對于HC , 當最大增益較大時 , 其他值也往往顯著 , 這表明所有傳播路徑普遍存在不穩定性 。 相比之下 , mHC始終產生穩定的結果 。
推薦閱讀















- 又是量化基金,第二個DeepSeek時刻到來了?
- 剛剛,稚暉君發布的人形機器人Q1,小到能塞進書包
- 豆包和DeepSeek們,再不做小程序就晚了
- 剛剛,釘釘掀桌子!狠人無招狂甩 20+AI 新品,AI 工作操作系統來了
- 剛剛,讓谷歌翻身的Gemini 3,上線Flash版
- 雷軍千萬年薪挖人,“天才少女”首秀小米AI,比DeepSeek還強?
- 剛剛,OpenAI推出全新ChatGPT Images,奧特曼亮出腹肌搞宣傳
- 蘋果剛剛差點失去了iPhone和Mac的優勢
- DeepSeek、Gemini誰更能提供情感支持?趣丸×北大來了波動態評估
- 剛剛,2026年英偉達獎學金名單公布,華人博士生霸榜占比80%