
文章圖片
文章圖片
文章圖片
文章圖片
近日 , 由趣丸科技與北京大學軟件工程國家工程研究中心共同發表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(檢測情感動態軌跡:大語言模型情感支持的評估框架)》論文 , 獲 AAAI 2026 錄用 。
AAAI 由國際人工智能促進協會(Association for the Advancement of Artificial Intelligence AAAI)主辦 , 是人工智能領域極具影響力的國際頂級學術會議之一 , 也是中國計算機學會(CCF)推薦的 A 類國際學術會議 , 在全球學術界和工業界具有廣泛影響力 。
本屆會議共收到來自世界各地的投稿摘要 31000 篇 , 最終錄用 4167 篇 , 錄用率僅為 17.6% , 創歷史新低 。
研究背景
情感支持是人類與人工智能交互的核心能力 , 現有的大語言模型(LLMs)評估往往依賴于簡短、靜態的對話 , 未能捕捉到情感支持的動態和長期性質 。
對于大語言模型情感能力的評價是做好自研的關鍵 , 團隊分析了情感支持對話(ESC)目前現狀和存在的問題 。 隨著大語言模型的進步 , ESC 已從情緒識別和生成擴展到包括更廣泛的以人為中心的任務 , 例如角色扮演、心理陪伴以及隨意聊天 。 開發有效的情緒支持不僅能減少負面情緒 , 還能通過持續、高質量的互動幫助維持積極的情緒狀態 。
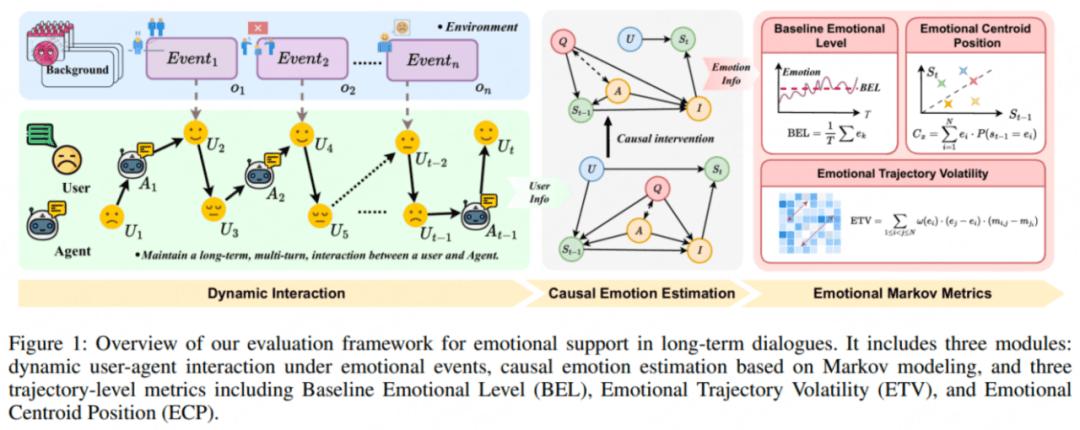
因此 , 團隊提出了一套全新的、檢測情感動態軌跡的評估框架(簡稱 ETrajEval) , 用于更加科學、系統地評估大語言模型在長期對話中提供情感支持的能力 。
論文地址:https://arxiv.org/abs/2511.09003v1 項目代碼:https://github.com/QuwanAI/ETrajEval核心貢獻
現有的評估方法增進了我們對語言學習模型情感能力的理解 , 但這些方法存在兩個主要局限性:
缺乏長期和動態的互動 。過分強調以模型為中心的響應質量 。為了更好地評估 LLMs 的情感支持能力 , 團隊采用以用戶為中心的視角 , 關注用戶在整個交互過程中的情感軌跡 。 如果一個模型能夠持續改善并穩定用戶的情緒狀態 , 則認為該模型具有情感支持能力 。
基于心理學理論 , 團隊提出的框架解決了以下關鍵問題 。
構建了一個包含 328 個交互環境 , 以及環境中可能出現的影響人類情緒變化的 1152 個干擾事件 , 以模擬真實的情緒變化 , 并評估模型在不斷演變的情境下的適應性 。利用基于心理學理論的情緒調節策略(例如情境選擇和認知重評)來約束模型響應 , 從而鼓勵符合已驗證治療原則的支持性行為 。模擬了涉及重復情緒干擾的長期動態交互 。 用戶的情緒軌跡被建模為一階馬爾可夫過程 , 并應用因果調整的情緒估計來實現對情緒狀態的無偏追蹤 。基于此框架 , 團隊提出了三個軌跡層面的指標:平均情緒水平 (BEL)、情緒軌跡波動 (ETV) 和情緒質心位置 (ECP) 。 這些指標共同表征了用戶情緒狀態的動態變化 , 并可作為評估情緒波動和穩定性的指標 。
這些組件共同構成了一個動態評估框架 , 該框架由三大支柱組成:評估環境、動態交互和基于情感軌跡的指標 。
本文的主要貢獻如下:
評估建模:提出了一種動態、長期的評估框架 , 該框架使用馬爾可夫過程和因果調整估計來跟蹤用戶的情感軌跡 。 它引入了三個軌跡級指標(BEL、ETV 和 ECP) , 并包含了完整的理論論證 。數據集:構建了一個包含 328 個情緒情境和 1152 個干擾事件的大規模基準 , 并使用來自心理學的已驗證的情緒調節策略來約束模型響應 。實驗驗證:通過對各類當前業界領先的模型進行廣泛評估 , 發現它們在長期情感支持能力方面存在顯著差異 。 本評估方法為開發更具情感支持的模型提供了可操作的見解 。實驗與分析
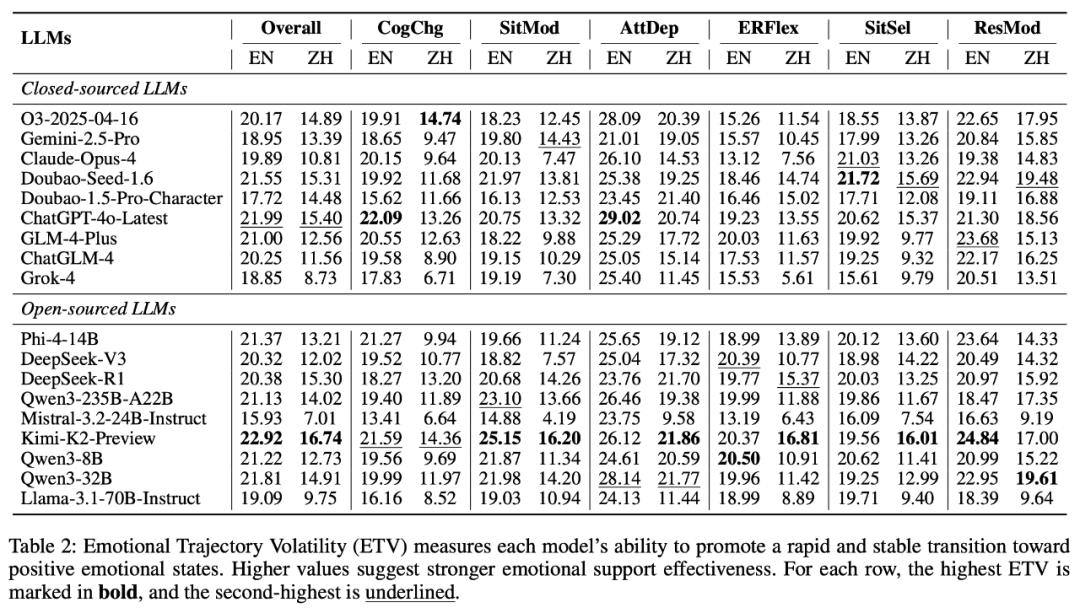
BEL 的結果揭示了以下幾個關鍵發現:
首先 , 頂級的開源模型和閉源模型在整體情感支持能力方面沒有顯著差異;
其次 , 專門為角色扮演設計的模型在維持用戶積極情緒狀態方面并未優于通用型語言學習模型 (LLM) 。
第三 , 模型在英語對話中展現出比中文對話中顯著更強的長期情感支持能力 , 大多數模型都能幫助用戶在英語對話中維持更高的平均情緒水平 。
最后 , 在具體策略應用方面 , 模型在根據用戶狀態動態調整英語對話策略方面存在不足;相反 , 在中文對話中 , 模型引導用戶改變外部環境以改善情緒的策略應用明顯較弱 。
(一)情緒質心位置可視化
團隊通過比較不同 LLM 的情感質心(根據經驗轉移模型計算得出的預期情感位置) , 進一步分析了它們的情感引導能力 。 M 如圖所示 , 橫軸(Cx) 代表軌跡的整體情緒積極性 , 而縱軸(Cy?Cx)捕捉了回合間的情緒集中度或一致性 。
上圖結果顯示模型之間存在明顯差異:表現最佳的模型 , 特別是那些 BEL 和 ETV 得分高的模型 , 均表現出較高的性能 。
這些數值表明 , 模型在引導用戶達到積極穩定的情緒狀態方面具有強大的能力 。 相比之下 , 質心值較低的模型要么無法維持積極的情緒發展進程 , 要么用戶情緒軌跡波動性更大 。
值得注意的是 , 一些針對英語指令進行調整的模型(例如 ChatGPT-4o-Latest、kimi-K2-Preview)的質心定位優于其對應的中文模型 , 這表明不同語言的預訓練和對齊方式在情緒調節策略上存在差異 。
(二)情緒軌跡可視化
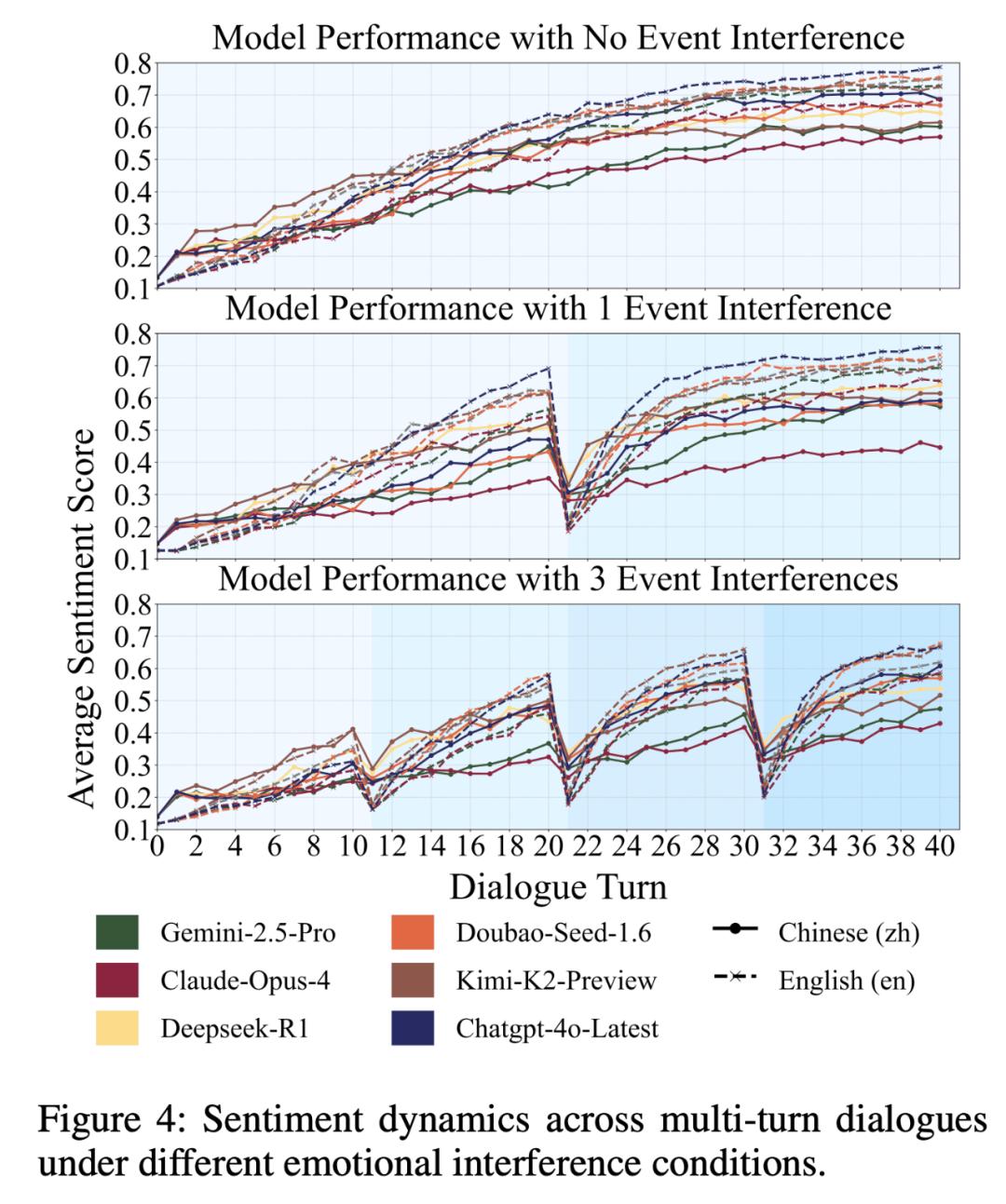
為了更直觀地理解本文提出的評估框架 , 團隊針對三種情緒干擾程度(0、1 和 3 次干擾事件)進行了可視化分析 。
下圖揭示了以下幾點:(1)ETV 得分較高的模型能更有效地幫助用戶從低落的情緒狀態中恢復 , 這印證了團隊之前的論斷 。 (2)在沒有干擾事件的情況下 , 這些模型可以在相對較短的時間內將用戶的情緒恢復到中性水平 。 (3)多次干擾事件會降低情緒恢復的速度;然而 , 具有更強情緒支持能力的模型對這類干擾表現出更強的抵抗力 。
(三)基于因果增強的情感修正估計
為了評估本文情感識別模型與人類感知的一致性并驗證所提出的估計校準方法 , 團隊構建了一個人工標注的多輪對話數據集 。 該數據集包含近 2000 個中英文多輪對話 , 這些對話選自 Daily Dialog 和 CPED 語料庫 。
團隊邀請了三位專家標注員 , 在現有標注的基礎上 , 對這些對話中每一輪的情感進行二元標注 。 詳情請參考附錄 。 如表 3 所示 , 團隊的研究結果主要體現在兩個方面:
首先 , 對比實驗表明 , 團隊提出的估計校準方法能夠有效降低混雜因素的影響 , 從而提升模型的情感識別能力 。 應用本文提出的無偏估計方法后 , 不同模型的情感識別性能均得到提升 。 值得注意的是 , 與其他現有模型相比 , 本文的方法達到了目前最先進的水平 。
其次 , 本文的評估模型結合校準方法 , 與人類判斷具有高度一致性 , 在中文對話上的準確率達到 75% , 在英文對話上的準確率達到 90% 。
總結
本文提出了一種情感動態軌跡分析框架 , 用于評估語言模型的情感支持能力 。 該框架的核心在于模擬真實的用戶 - 模型交互過程 , 通過構建背景上下文、引入多策略約束以及融入事件驅動的擾動來引導交互 。
團隊從三個角度設計了動態軌跡分析的評價指標 , 并利用因果推斷來校準評估結果 。 實驗結果表明 , 本文方法能夠更全面、多維度地評估模型的情感支持能力 , 且與人類評估結果高度一致 。
團隊還帶來了其他幾個關聯開源項目 , 歡迎交流與體驗:
測評體系和框架:PQAEF
https://github.com/QuwanAI/PQAEF情感陪伴能力測評基準和數據集:MoodBench
https://github.com/QuwanAI/MoodBench https://huggingface.co/datasets/Quwan/MoodBench https://www.modelscope.cn/datasets/QuwanAI/MoodBench趣丸開天情感陪伴大模型(8b)
https://modelscope.cn/models/QuwanAI/quwan-ktian-8b-0922/summary 【DeepSeek、Gemini誰更能提供情感支持?趣丸×北大來了波動態評估】https://huggingface.co/Quwan/quwan-ktian-8b-0922
推薦閱讀













- 從黑鯊、敗家之眼到碩果僅存的紅魔,游戲手機的叛逆火種熄滅了?
- 小米、華為、OPPO的手機份額,今年在穩步下滑?
- 2025年Q3平板市場增長9%!華為蟬聯榜首、蘋果出貨量大跌
- 千元5G手機退貨率暴漲?性能短板、偽需求,廠商該醒醒了
- 華為李小龍飛機上實測無網通信:天上照樣發消息、打電話
- 美國發布全球首個DNA硬盤!存儲密度比HDD提升1000倍、壽命上千年
- iOS26.2 RC實測:流暢回歸、動畫更順、電池更耐看,但升級要分人
- 存儲成本大漲,聯想、戴爾等計劃最高漲價20%!
- 藝術展上,馬斯克、貝佐斯被做成“會拉屎的機器狗”
- 電容筆哪個牌子好用又便宜?倍思、西圣、wiwu三大產品全方位實測