
文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片
機器之心報道
【OpenAI久違發了篇「正經」論文:線性布局實現高效張量計算】編輯:Panda
OpenAI 發論文的頻率是越來越低了 。
如果你看到了一份來自 OpenAI 的新 PDF 文件 , 那多半也是新模型的系統卡或相關增補文件或基準測試 , 很少有新的研究論文 。
至于原因嘛 , 讓該公司自家的 ChatGPT 來說吧:「截至目前 , OpenAI 在 2025 年在 arXiv 上公開發布的論文數量相對較少 , 可能反映了其對研究成果公開策略的謹慎態度 , 可能出于商業保密或安全考慮 。 」
不過近日 , OpenAI 也確實發布了一份完全由自己人參與的、實打實的研究論文 , 其中提出了一種用于高效張量映射的統一代數框架 Linear Layouts 。 這是一種使用二元線性代數而非比特表示(bit representation)的張量布局的通用代數形式 , 解決了 Triton 等深度學習編譯器中長期存在的難題 。
- 論文標題:Linear Layouts: Robust Code Generation of Efficient Tensor Computation Using ?
- 論文地址:https://arxiv.org/pdf/2505.23819.pdf
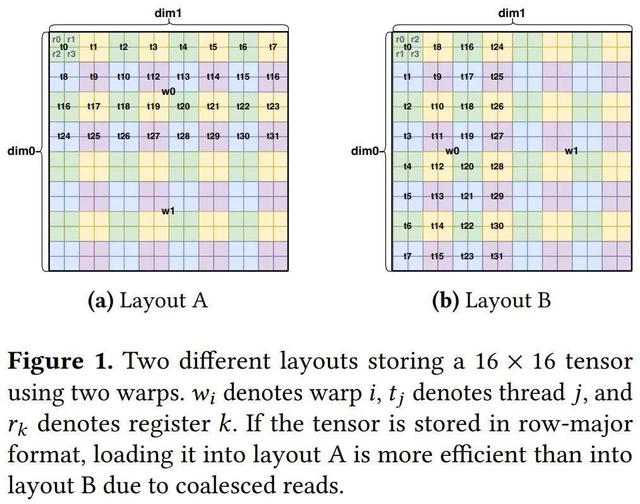
簡單來說:張量布局 = 邏輯張量與硬件資源(例如內存、線程、向量單元)之間的映射關系 。 下圖給出了兩個布局示例 。
對于現代深度學習工作負載而言 , 所需要的張量布局需要滿足幾個要求:
- 高效(為了性能) 。
- 靈活(以支持多種算子) 。
- 可組合(為了變換和優化) 。
- 需要根據實際需求設計 , 而且往往是硬編碼的(需要手動編寫規則) 。
- 不可擴展(每一對布局都需要二次組合) 。
- 容易出錯 , 尤其是在像 Triton 這樣的低層級的后端中 —— 截至目前 , Triton 的 GitHub 庫中提交的 12% 的 Bug 與布局有關 。
例如 , 為了實現高效的矩陣乘法 , 英偉達在 Ampere、Hopper 和 Blackwell 等不同代際的 GPU 上采用了不同的使用 Tensor Core 的布局 , 并且每種布局在使用不同數據類型時都有不同的變體 。 AMD 和英特爾等其它 GPU 供應商在利用其類似 Tensor Core 的技術進行加速時 , 也使用了不同的布局 。 因此 , 硬件架構的快速發展和多樣化的深度學習模型需要一種新的張量布局建模方法 。
為此 , 需要解決一些技術難題:
- 在將張量映射到硬件資源方面 , 需要一種通用且可組合的表示方法 。
- 布局轉換應該用統一的形式來表達 , 甚至需要包含諸如數據交換(data swizzling)等復雜變換 。
- 這種表示必須與低級硬件優化無縫集成 , 以確保高效的數據訪問和計算 。
相關背景知識
GPU 架構
在設計上 , 現代 GPU 的目標是通過包含多層硬件資源的分層執行模型來充分利用并行性 。
其關鍵執行單元包括協作線程陣列 (CTA)、Warp 和線程 。 每個 GPU 線程都可以訪問私有寄存器 —— 這些寄存器提供最低延遲的存儲空間 , 但容量有限 。 常規指令可以由各個線程獨立執行 。 然而 , 某些特殊功能單元必須在更高的粒度級別上執行 。
例如 , 英偉達的 mma(矩陣乘法累加)指令利用 Tensor Core 的方式是并行執行由各個 Warp 發出的多個乘加運算 。 而 wgmma(Warp 組矩陣乘法累加)等高級變體則是通過在多個 Warp 上同時執行矩陣乘法而對這些功能進行了擴展 。 AMD 也引入了類似的原語 , 例如 mfma(矩陣融合乘加)指令 。
請注意 , 這些指令要求數據分布在線程和 Warp 之間 , 或者以特殊布局駐留在共享內存或特殊內存單元(例如 Blackwell 上的 Tensor Memory)中 , 才能產生正確的結果 。
然而 , 這些布局通常不會為加載 / 存儲等其他操作帶來最佳性能 , 而且并非總是可以使用特定指令將數據直接從全局內存復制到特殊內存單元 。
因此 , 通常必須對數據進行重新排列 , 以便將用于內存訪問的布局轉換為計算單元偏好的布局 。
簡而言之 , 要實現峰值性能 , 不僅需要利用這些專用單元 , 還需要精心設計張量布局和轉換 。
Triton 語言和編譯器
Triton 是一種類似于 Python 的用于特定領域的語言 , 其設計目標是提供用于編寫高性能深度學習原語的靈活接口 。 Triton 的編譯器后端使用了 MLIR , 支持多層次抽象表達 。
究其核心 , Triton 內核遵循單程序多數據 (SPMD) 模型 , 其中計算被劃分為多個抽象的 Triton 程序實例 。 這種設計允許開發者主要關注 CTA 級別的并行性即可 。 在 Triton 中 , 「張量」一詞指的是從原始 PyTorch 張量中提取的塊 , 它們用作 GPU 核的輸入和輸出 。
在編譯過程中 , Triton 的 Python 代碼首先被翻譯成 Triton 方言 (tt) , 然后進一步翻譯成 TritonGPU 方言 (ttg) 。 在此過程中 , 每個張量都與特定的布局相關聯 , 以充分利用現代 GPU 上可用的硬件功能單元 。 例如 , 當遇到 dot 類算子(例如 tt.dot 和 tt.dot_scaled)時 , 會采用 mma 布局并使用 Tensor Core 和類似的單元 。
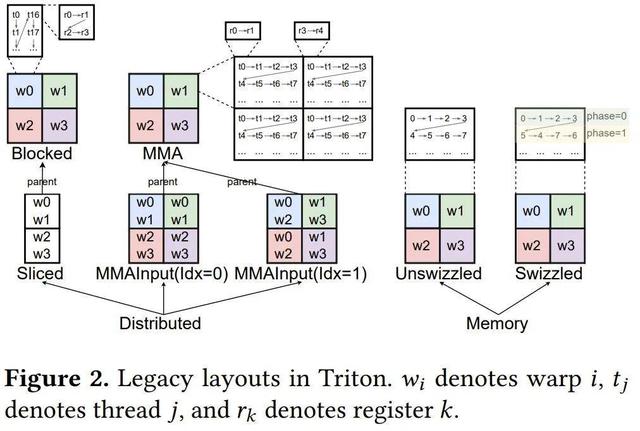
傳統布局
圖 2 列出了 Triton 中所有可用的布局 。
在最高層級 , 布局分為分布式(Distributed)布局和內存((Memory)布局 。 前者是指張量元素分布在不同的執行單元中 , 而后者是指張量元素存儲在特定的特殊內存中 。
分布式布局又可進一步分為 Blocked、Sliced、MMA 和 MMA Input 布局等類型 , 而內存布局又可進一步分為 Unswizzled 和 Swizzled 布局 。
Blocked 布局通常用于連續的內存訪問 。 MMA 和 MMA 輸入布局用于矩陣乘法運算(例如 tt.dot)的輸出和輸入 。 MMA 布局可以根據其映射到的硬件指令進一步分類 , 例如英偉達 GPU 上的 mma 和 wgmma , 或 AMD GPU 上的 mfma 。 Sliced 布局是從其父布局中提取一個維度 , 用作廣播或某個歸約運算的輸出 。
傳統 Triton 布局系統要求每個布局定義自己的接口方法 , 例如每個線程的元素數量和連續元素的數量 。 此外 , 必須為每個布局顯式實現對張量元素的索引以及布局之間的轉換 。 這種方法導致布局構造和轉換常出現 bug 。
Linear Layouts(線性布局)
下面將簡單介紹線性布局的定義、一些基本的線性布局算子、創建各種 Triton 布局以作為線性布局實例 , 以及應用于 Triton 的通用布局引擎 。
一個示例
在 GPU 編程中 , 大多數參數都是 2 的冪:一個 Warp 由 32 或 64 個線程組成 , 一個 Warp 組包含 4 個 Warp , 矩陣乘法內聯函數(例如 mma 和 wgmma)要求 Tile 尺寸為 16 ×, 其中 ≥ 1 。
此外 , 在 Triton 的編程模型中 , 張量的維度以及與每個張量相關的布局子部分(例如每個線程的寄存器和線程數量)都被限制為 2 的冪 。 在圖 1 中 , 布局 A 有一個 16 × 16 的張量 , 其使用了多個 2 × 2 的寄存器、4 × 8 的線程和 2 × 1 的 Warp 。
由于這些量都是 2 的冪 , 因此使用其坐標的比特表示 , 可以直觀地可視化布局 A 中元素的分布(如圖 1 所示) 。 所有線程的寄存器 0 (_0) 都位于坐標 ( ) , 其中 和 的最后幾位(bit)均為 0 。 例如 , 線程 _1 的 _0 位于 (0 2) = (000 010) 。 作為對比 , _1 元素的坐標中 ,的最后一位始終為 0 , 而 的最后一位始終為 1 。 例如 , _9 的 _1 位于 (2 3) = (010 011) 。
此外 , 對于任何偶數線程 _ ,的最后一位與 _0 中 的倒數第二位匹配 ,的倒數第二位與 _0 中 的倒數第三位匹配 。 例如 , _10 = _01010 的 _0 位于 (2 4) = (010 0100) 。 這種系統性對齊持續存在 , 表明二次冪結構足以清晰地決定了每個線程元素的分布 。
綜上所述 , 假設一個大小為 8 的向量 表示一個 Warp 中線程的一個元素 , 其中前 2 位表示寄存器 (Reg) , 接下來的 5 位表示線程 (Thr) , 最后一位則表示 Warp (Wrp) , 則可以如此定義布局 :
當需要從邏輯張量的坐標中恢復硬件索引時 , 需要使用求逆運算 。
對線性布局的更詳細完備性說明請訪問原論文 , 其中涉及到說明分塊布局、mma 和 wgmma 的輸入和輸出布局、線性布局的 slice、每個分布式布局、MMA swizzled 布局、內存布局都是線性布局 。 另外 , OpenAI 也在 Triton 說明了如何實現布局轉換以及形狀操作 。
不僅如此 , OpenAI 表示 , 線性布局為在語言前端和編譯器后端開發算法提供了結構化的基礎 。 他們也在論文中給出了一些關鍵示例 , 這里就不過多展開 。 接下來簡單看看新提出的線性布局的實際表現 。
評估
OpenAI 將優化版 Triton(集成了基于線性布局的優化 , 即 Triton-Linear)與未集成這些優化的基準 Triton 進行了比較 。 Triton 和 TritonLinear 之間的主要區別如下:
- Triton 使用傳統的數據布局 , 不支持任意分布式布局的實用程序或它們之間的轉換 , 因此容易出現 bug 。
- Triton 未采用論文中描述的優化代碼生成 。 例如 , 布局轉換始終通過共享內存進行 , 對高效硬件原語的使用有限 。
為了比較 Triton 和 Triton-Linear 的性能 , 該團隊構建了一些合成微基準來進行測試 , 這方面的結果請訪問原論文查看 。 這里僅看看它們在實際基準測試中表現 。
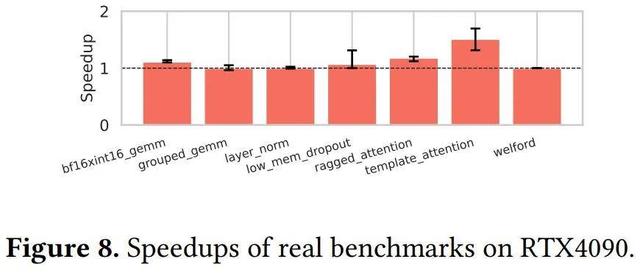
在三個不同的平臺上 , OpenAI 運行了 TritonBench 中的 18 個基準測試 。 圖 7、圖 8 和圖 9 中展示了 Triton-Linear 在三個平臺上的性能提升 。
由于每個基準測試包含多個輸入 , 總計 420 個案例 , 因此他們使用了誤差線(error bars)來表示每個基準測試的最小和最大加速 。
需要注意的是 , 由于硬件限制 , 并非所有基準測試都適用于每個平臺 。 例如 , 某些基準測試需要僅在 GH200 上才有的大型共享內存 , 而一些核使用的張量描述符依賴于 TMA 引擎 , 而 RTX4090 和 MI250 上均不支持 TMA 引擎 。
可以看到 , 在 GH200 上 , 他們實現了 0.92 倍到 1.57 倍不等的加速 , 所有基準測試的平均加速均超過 1.0 倍 。 加速最顯著的基準測試是 int4_gemm、ops_gemm 和 streamk_gemm 。
可以觀察到 , 高效的硬件原語(例如 ldmatrix 和 stmatrix)在這些核中被廣泛用于布局轉換以及共享內存的加載和存儲操作 。 值得注意的是 , layer_norm 實現了從 0.99 倍到 1.57 倍的加速 —— 在不同形狀之間表現出了顯著差異 。 對于某些輸入形狀 , Triton-Linear 能夠檢測「等效」布局之間的轉換 , 從而將轉換過程降低為 no-op(無操作) 。 這種優化在舊版布局系統中無法實現 , 因為它無法直接比較不同類型的布局(例如 , Blocked 布局和 Sliced 布局) 。
在 RTX4090 上 , 新方法實現了 1.00 倍到 1.51 倍的加速 。 由于 mma (RTX4090) 和 wgmma (GH200) 指令之間的差異 , 他們在 template_attention 上實現了更高的加速 。 在本例中 , tt.dot 運算的左操作數在循環外部定義 , 會重復從同一地址加載數據 , 因此 ldmatrix 和常規共享內存指令均可實現高吞吐量 。 雖然右操作數在每次迭代中都會更新 , 但 wgmma 會直接在共享內存中訪問它 , 只有在 RTX4090 上 , 經過優化后 , 它才會被降級到 ldmatrix 中 。 因此 , 在 GH200 上實現的加速相對較低 。 在 MI250 上 , 新方法實現了 0.98 倍到 1.18 倍的加速 。
總體而言 , 由于缺乏 ldmatrix 等高效的硬件原語 , Triton-Linear 在 AMD GPU 上實現的加速低于在英偉達 GPU 的 。
對于 OpenAI Open 的這個研究 , 你有什么看法呢
推薦閱讀















- 即將發布的5款新機,每一款都很有看點!你最期待哪一款?
- 最新發現!每參數3.6比特,語言模型最多能記住這么多
- 多模態擴散模型開始爆發,這次是高速可控還能學習推理的LaViDa
- 英特爾證實數代處理器正在研發:覆蓋不同領域
- 發布2025年度隱私保護廣告,蘋果重申領先地位
- 國產Top5廠商開始發力:四攝設計+外掛鏡頭,手機影像迎來新時代!
- 三星電子計劃下月引入AI編程助手 以提高軟件開發效率
- 任正非發聲:芯片的問題沒必要擔心
- 谷歌CEO皮查伊:AI才發展到AJI階段,實現AGI還需20年以上
- AMD 25.6.1正式版顯卡驅動發布:FSR 4游戲爆發式增長14款