
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
機器之心報道
編輯:Panda
當狀態空間模型遇上擴散模型 , 對世界模型意味著什么?在這個 AI 技術與應用大爆發的時代 , 我們最不缺的就是「熱詞」 , 從自回歸到擴散模型 , 從注意力機制到狀態空間模型 , 從思維鏈到推理模型…… 有時候 , 其中一些熱詞會聚攏一處 , 為 AI 世界創造出新的可能性 。
今天我們要介紹的這項研究便是如此 , 集齊了長上下文、狀態空間模型(SSM)、擴散模型、世界模型等「熱詞」 , 創造了一種全新的「視頻世界模型」 。 該研究來自斯坦福大學、普林斯頓大學和 Adobe Research , 在社交網絡上引起了不少關注 。
- 論文標題:Long-Context State-Space Video World Models
- 論文地址:https://arxiv.org/pdf/2505.20171
而視頻擴散模型已成為一種頗具前景的世界建模方法 。 不過 , 早期的視頻擴散模型僅限于生成固定長度的視頻 , 因此不適用于交互式應用 , 而近期的架構已可通過自回歸式的滑動窗口預測實現無限長度的視頻生成 。 這為一種新的范式鋪平了道路:基于交互式控制信號 , 視頻擴散模型可以通過連續生成視頻幀而實現對視覺世界的交互式模擬 。
然而 , 由于注意力機制的上下文長度有限 , 現有視頻世界模型的時間記憶非常有限 。 這一限制使它們難以模擬具有長期一致性的世界 。
例如 , 當使用現有視頻世界模型模擬游戲時 , 玩家只需向右看然后再次向左看 , 整個環境就可能完全改變(見圖 1) 。
原因很容易理解:模型的注意力窗口中已經沒有包含原始環境的幀了 。
雖然理論上可以通過更長的上下文窗口來擴展記憶 , 但這種方法有兩大問題:
- 訓練的計算成本會與上下文長度呈二次方增長 , 使其成本過高;
- 每幀推理時間隨上下文長度線性增長 , 導致生成速度越來越慢 , 這對于需要實時、無限長度生成的應用(例如游戲)來說 , 根本沒法用 。
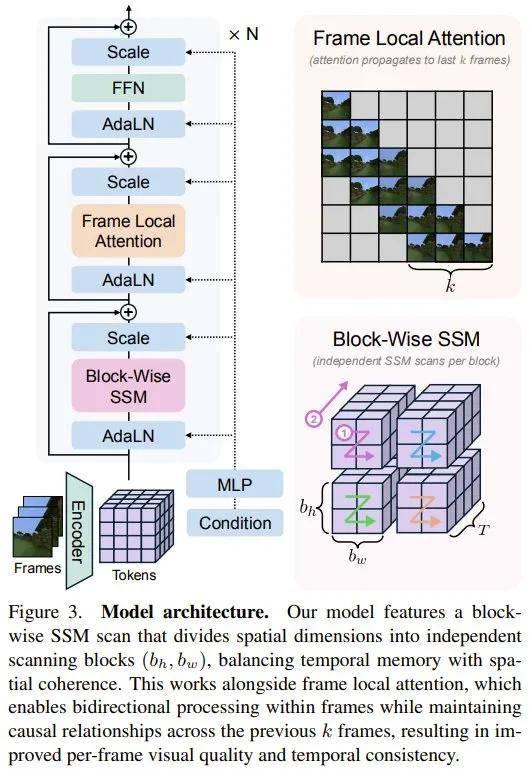
簡單來說 , 他們使用了狀態空間模型(SSM)來實現長期記憶 , 其中關鍵在于 Mamba 的逐塊掃描(block-wise scan)方案 —— 能在保留時間因果關系的同時 , 實現時間記憶與空間一致性的最佳平衡 。 另外 , 該團隊還對該方案進行了補充:在相鄰幀之間設置了密集的局部注意力機制 , 從而能以最小的計算開銷實現高保真度的生成 。
該團隊介紹說:「不同于以往針對非因果視覺任務改進 SSM 的方法 , 我們的方法有根本上的差異:我們專門使用了 SSM 來處理因果時間動態并追蹤世界狀態 , 充分利用了其在序列建模方面的固有優勢 。 」
對視頻擴散模型和狀態空間模型的基礎數學描述請參看原論文 , 下面將更詳細地介紹這項研究的創新 。
新方法詳解
模型架構
由于這個模型會以自回歸的方式(一次一?。 ┥墑悠抵?, 因此時間維度(幀序列)必須位于掃描順序的末尾 。 這種「空間主 / 時間次」的排序可確保模型在移動到下一幀之前處理完當前幀內的所有空間信息 , 從而保留因果約束并防止模型訪問未來幀的信息 。
然而 , 以空間為主的掃描順序會使得捕捉長期時間依賴性變得困難 , 因為在展平的 token 序列中 , 時間上相鄰的 token 彼此之間會變得相當遙遠 。
為了解決這一限制 , 該團隊提出了一種平衡時間記憶和空間一致性的方法 , 即對時空 token 進行逐塊重新排序(block-wise reordering) 。
逐塊 SSM 掃描 。 如圖 3(右下)所示 , 新提出的方法會將原始 token 序列沿空間維度分解為大小為 (b_h b_w T) 的塊 , 其中 b_h 和 b_w 是與層相關的塊高度 / 寬度 , T 是數據的時間維度 。
需要注意 , 這里并不會對所有 token 序列進行一次掃描 , 而是對每個 token 塊進行單獨的掃描 。 通過控制 b_h 和 b_w 的值 , 可以在時間相關性和空間一致性之間取得平衡 。 現在 , 時間上相鄰的 token 以 b_h × b_w token 分隔 , 而不是像傳統的以空間為主的掃描中那樣以 H × W token 分隔 , 其中 H、W 表示每幀的高度 / 寬度 。
然而 , 較小的塊會導致空間一致性更差 , 因為獨立的掃描會阻止不同塊中的 token 交互 。 因此 , 塊大小的選擇代表了一種在一致性長期記憶和短期空間一致性之間進行權衡的有效方法 。 通過在不同的層中采用不同的 b_h 和 b_w 值 , 該模型可充分利用大塊和小塊的優勢 。
由于固定維度的 SSM 狀態的表征能力有限 , 因此 SSM 在處理視覺生成等高復雜度任務時可能會遇到困難 。 新提出的逐塊掃描方法可通過有效地增加每層的 SSM 狀態的維度來緩解這一限制 , 因為每個塊都被分配了一個單獨的狀態 。
幀局部注意力機制 。 研究已經證明 , Mamba 等線性注意力機制的變體在與聯想回憶相關的任務中表現不佳 。 在視頻生成中 , Mamba 無法檢索精確的局部信息 , 導致幀間質量不佳 , 并會喪失短期時間一致性 。
之前有研究表明 , 將局部注意力機制與 SSM 相結合的混合架構可以提升語言建模的效果 。 在新提出的模型中 , 會在每次 Mamba 掃描后引入一個逐幀局部注意力模塊 , 如圖 3 所示 。 在訓練過程中 , 應用逐塊因果注意力機制 , 其中每個 token 只能關注同一幀中的 token 以及一個固定大小的前幾幀窗口 。 注意力掩碼 M 的形式為:
其中 i 和 j 是序列中幀的索引 , k 是窗口大小 。
動作條件 。 為了在自回歸生成過程中啟用交互式控制 , 該團隊的做法是將與每幀對應的動作作為輸入 。 這里 , 會通過一個小型多層感知器 (MLP) 處理連續動作值(例如 , 攝像機位置) , 并添加到噪聲級別嵌入中 , 然后通過自適應歸一化層將其注入到網絡中 。 對于離散動作 , 這里是直接學習與每個可能動作對應的嵌入 。
長上下文訓練
該團隊指出 , 盡管新提出的架構設計可增強模型維持長期記憶的能力 , 但使用標準的擴散訓練方案仍舊難以學習長時域依賴性 。 視頻數據包含大量冗余 , 這使得模型在大多數情況下主要依賴鄰近幀進行去噪 。 因此 , 擴散模型經常陷入局部最小值 , 無法捕捉長期依賴性 。
在訓練期間 , 標準的 diffusion forcing 始終會向每個幀獨立添加噪聲 。 在這種情況下 , 模型參考遠處上下文幀的動力有限 , 因為它們通常包含的有用信息少于局部幀 。
為了鼓勵模型關注遠處幀并學習長期相關性 , 該團隊將 diffusion forcing 與一種改進的訓練方案結合了起來 。 該方案可在訓練期間保持幀的隨機長度前綴完全干凈(無噪聲) , 如圖 4 所示 。
當向后續幀添加較大噪聲時 , 干凈的上下文幀可能比嘈雜的局部幀提供更多有用信息 , 從而促使模型有效地利用它們 。 這與 Ca2VDM 中的訓練方案類似 。
通過固定長度狀態進行高效推理
在推理過程中 , 再根據輸入動作自回歸地生成新的視頻幀 。 新提出的混合架構可確保恒定的速度和內存使用率 。
具體而言 , 該模型的每一層僅跟蹤:前 k 幀的固定長度 KV 緩存 , 以及每個塊的 SSM 狀態 。 這可確保整個推理過程中內存使用率的恒定 , 這不同于完全因果式的 Transformer—— 在生成過程中內存需求會隨著存儲所有先前幀的 KV 緩存而線性增長 。
同樣 , 新提出的方法可保持每幀生成速度恒定 , 因為局部注意力機制和逐塊 SSM 計算不會隨視頻長度而變化 。 此特性對于視頻世界模型應用至關重要 , 因為這些應用通常非常需要無限期地生成視頻幀而不降低性能 。
實驗表現
該團隊從訓練和推理效率以及長期記憶能力方面評估了新提出的方法 。
為此 , 他們使用了兩個長視頻數據集 , 并評估該模型在空間記憶任務中的表現 , 這些任務為了生成準確的預測 , 需要回憶遠距離幀的信息 。 有關數據集和評估方法的更詳細介紹請訪問原論文 , 下面重點來看實驗結果 。
首先 , 表 2 和表 3 給出了不同模型在 Memory Maze 上進行空間檢索和推理的定量結果 。
可以看到 , 新提出的模型在檢索和推理這兩個任務的所有指標上都是最優的 。
如圖 5 和圖 6 所示 , 對于這兩項任務 , 其他次二次模型的幀預測在一段時間后會偏離 ground truth , 而新方法在整個軌跡范圍內都能保持準確的預測 。
圖 7 進一步分析了每種方法在檢索任務上的性能 , 展示了隨著生成幀和檢索幀之間距離的增加 , 檢索準確率的變化 。
因果 Transformer 在其訓練上下文中表現良好 , 但超過其最大訓練長度后會迅速下降 。 其他線性復雜度方法(例如 Mamba 和 Mamba2 + Frame Local Attn)由于狀態空間表達能力有限而表現不佳 。
相比之下 , 本文的新方法在所有檢索距離上都保持了較高的準確度 , 與在完整上下文上訓練的因果 Transformer 相當 。
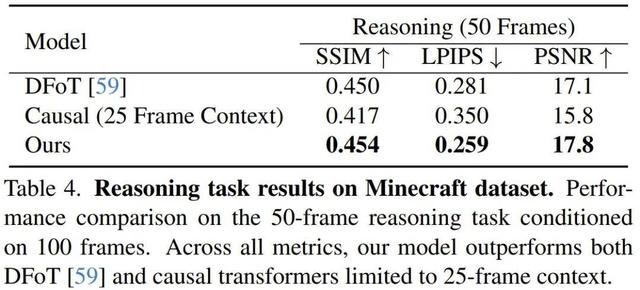
另外 , 該團隊也在 TECO Minecraft 上進行了實驗 , 表 4 和圖 2 分別給出了定量和定性結果 。 這里參與對比的模型是 diffuion forcing transformer(DFoT)—— 一種在 diffuion forcing 機制下訓練的雙向 Transformer , 算得上是當前自回歸長視頻生成領域最先進的架構 。 然而 , 由于其模型的二次復雜度 , DFoT 是在 25 幀的有限上下文長度上訓練的 。
可以看到 , 新方法可以準確預測先前探索過的區域 , 而上下文窗口有限的方法則無法做到這一點 。
總體而言 , 新方法優于 DFoT 和在 25 幀上下文上訓練的因果 Transformer 。
由于軌跡較短 , 所有模型在該數據集上的相似度都較低 , 其中模型僅獲得 100 幀上下文來預測 50 幀 。 通常而言 , 100 幀的上下文不足以讓智能體完全觀察環境 , 從而可能導致任務軌跡冒險進入先前未見過的區域 , 在這種情況下 , 逐幀相似度的信息量會降低 。
該團隊也研究了新方法的訓練和推理成本 。 圖 8 使用三個指標評估模型性能:每次迭代的訓練成本(左)、生成期間的內存利用率(中)以及推理期間的計算時間(右) 。
可以看到 , 新提出的方法在所有指標上都表現出了卓越的擴展性:訓練時間會隨上下文長度線性擴展 , 同時能在推理期間保持恒定的內存和計算成本 。 為了比較推理運行時間 , 該團隊還比較了通過幀局部注意力機制加 SSM 更新進行單次前向傳遞的運行時間 , 以及對所有先前生成的幀進行 KV 緩存的完整注意力機制的運行時間 。
更多詳情請參閱原論文 。
順帶一提 , 正如 Meta 和蒙特利爾學習算法研究所研究者 Artem Zholus 在機器之心 帳號下評論的那樣 , 使用 SSM 來構建世界模型的研究一兩年就已經有了 , 感興趣的讀者可擴展閱讀 。
1. Mastering Memory Tasks with World Models
項目地址:https://recall2imagine.github.io/
2. Facing Off World Model Backbones: RNNs Transformers and S4
【SSM+擴散模型,竟造出一種全新的「視頻世界模型」】項目地址:https://fdeng18.github.io/s4wm/
推薦閱讀










- 大模型智能體如何突破規模化應用瓶頸,核心在于Agentic ROI
- 最新發現!每參數3.6比特,語言模型最多能記住這么多
- 多模態擴散模型開始爆發,這次是高速可控還能學習推理的LaViDa
- 刷新世界記錄,40B模型+20萬億token,散戶組團挑戰算力霸權
- 美國人又來搞事,“華為式”的制裁又要擴散了?
- AI瘋狂進化6個月,一張天梯圖全濃縮,30+模型混戰,大神演講爆火
- 華為昇騰AI準萬億MoE模型技術突破
- 通義發布QwenLong-L1, 長上下文大型推理模型, 強在哪里?
- 首次!不聽人類指揮,AI模型拒絕關閉
- 火山引擎密集上新:豆包全新視頻生成模型、視覺深度思考模型,Trae多個重點功能升級