文章圖片

文章圖片
文章圖片
隨著大模型的迅猛發展 , 混合專家(MoE)模型憑借其獨特的架構優勢 , 成為擴展模型能力的重要方向 。 MoE通過創新性的路由機制 , 動態地將輸入token分配給不同的專家網絡 , 不僅高效實現了模型參數的規模化擴展 , 更在處理復雜任務時展現出顯著優勢 。 然而 , 將MoE模型在分布式集群環境下進行訓練時 , 訓練效率不足 , 已成為亟待解決的難題 。
MoE大規模訓練難題:一半以上的訓練時間在等待?實踐表明 , MoE模型訓練集群的效率面臨兩方面挑戰:(1)專家并行引入計算和通信等待 , 當模型規模較大時 , 需要切分專家到不同設備形成并行(EP) , 這就引入額外All-to-All通信 , 同時MoE層絕大部分EP通信與計算存在時序依賴關系 , 一般的串行執行模式會導致大量計算單元空閑 , 等待通信;(2)負載不均引入計算和計算等待 , MOE算法核心是“有能者居之” , 在訓練過程中會出現部分熱專家被頻繁調用 , 而冷專家使用率較低;同時 , 真實訓練數據的長度不一 , 不同的模型層(如稀疏層、嵌入層等)的計算量也存在明顯差異 , 造成不同卡之間計算也在互相等待 。
形象地說 , MoE訓練系統就像一個交通擁塞嚴重的城區:1)人車混行阻塞 , 所有車輛(計算)必須等待行人(通信)完全通過斑馬線才能通行 , 造成大量無效等待;2)車道分配僵化 , 固定劃分的直行、左轉車道就像靜態的專家分配 , 導致熱門車道(熱專家)大排長龍 , 而冷門車道(冷專家)閑置 。 為此 , 華為團隊構建了一套叫做Adaptive PipeEDPB的優化方案 , 就像一個“上帝視角的智慧樞紐” , 讓MoE訓練集群這個“城市交通”實現無等待的流暢運行 。
DeployMind仿真平臺 , 小時級自動并行尋優
華為構建了名為AutoDeploy的仿真平臺 , 它是一個基于昇騰硬件訓練系統的“數字孿生”平臺 , 通過計算/通信/內存三維度的多層級建模、昇騰硬件系統的高精度映射、全局化算法加速運行等技術 , 能在1小時內模擬百萬次訓練場景 , 實現MoE模型多樣化訓練負載的快速分析和自動找到與集群硬件規格匹配的最優策略選擇 。 在訓練實踐驗證中 , 該建模框架可達到90%精度指標 , 實現低成本且高效的最優并行選擇 。
針對Pangu Ultra MoE 718B模型 , 在單卡內存使用約束下 , 華為通過AutoDeploy以訓練性能為目標找到了TP8/PP16/VPP2/EP32(其中TP只作用于Attention) , 這一最適合昇騰集群硬件規格的并行方案 , 綜合實現計算、通信、內存的最佳平衡 。
Adaptive Pipe通信掩蓋98% , 讓計算不再等待通信
華為構建了一套稱為Adaptive Pipe的通信掩蓋框架 , 在AutoDeploy仿真平臺自動求解最優并行的基礎上 , 采用層次化All-to-All降低機間通信和自適應細粒度前反向掩蓋 , 實現通信幾乎“零暴露” 。
層次化專家并行通信 。 針對不同服務器之間通信帶寬低 , 但機內通信帶寬高的特點 , 華為創新地將通信過程拆成了兩步走:第一步 , 讓各個機器上“位置相同”的計算單元聯手 , 快速地從所有機器上收集完整的數據塊(Token);第二步 , 每臺機器內部先對數據塊進行整理 , 然后利用機器內部的高速通道 , 快速完成互相交換 。 這種分層設計的巧妙之處在于 , 它把每個數據塊最多的復制分發操作都限制在單臺機器內部的高速網絡上完成 , 而在跨機器傳輸時 , 每個數據塊只需要發送一份拷貝 , 相比傳統All-to-All通信加速1倍 。
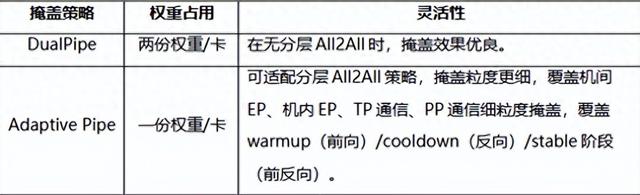
自適應細粒度前反向掩蓋 。 在DualPipe掩蓋框架的基礎上 , 華為基于虛擬流水線并行技術 , 實現了更精密的調度 , Adaptive Pipe(圖1) 。 相比DualPipe , Adaptive Pipe僅利用一份權重 , 不僅將流水線并行所需的內存占用減半 , 有效降低了計算“空泡” , 釋放了流水線的峰值性能潛力;同時 , 該策略能夠額外實現與分層通信的完美協同 , 無縫覆蓋機間與機內兩層通信的掩蓋 。 在這種層次化通信和細粒度計算通信切分調度優化下 , Adaptive Pipe可實現98%以上的EP通信掩蓋 , 讓計算引擎不受通信等待的束縛 。
圖1 :自適應細粒度前反向掩蓋方案:(a) warmup階段純前向;(b) cooldown階段純反向;(c) stable階段前反向掩蓋;第一行為計算算子 , 第二行為機內EP通信 , 第三行為機間EP通信;F代表前向算子 , B代表反向算子 , R代表重計算算子 , PP P2P代表stage間的P2P通信 。
EDPB全局負載均衡 , 讓計算之間不再互相等待 , 訓練再加速25%在最優并行和通信掩蓋基礎上 , 由于MoE模型訓練過程中天然存在的負載不均問題 , 集群訓練效率時高時低 。 華為團隊創新性地提出了EDPB全局負載均衡 , 實現專家均衡調度(圖2) , 在最優并行和通信掩蓋基礎上 , 再取得了25.5%的吞吐提升收益 。
圖2:集群P2P通信分析對比
專家預測動態遷移(E) 。 MoE模型訓練中 , 設備間的專家負載不均衡如同“蹺蹺板”——部分設備滿載運行 , 另一些卻處于“半休眠”狀態 。 團隊提出了基于多目標優化的專家動態遷移技術 , 讓專家在分布式設備間“智能流動” 。 該技術主要有三個特點:
· 預測先行:讓專家負載“看得見未來”:預測負載趨勢 , 實現“計算零存儲開銷 , 預測毫秒級響應”;
· 雙層優化:計算與通信的黃金分割點:提出節點-設備雙層貪心優化架構 , 在讓計算資源“齊步走”的同時 , 給通信鏈路“減負”;
· 智能觸發:給專家遷移裝上“紅綠燈”:設計分層遷移閾值機制 , 通過預評估遷移收益動態決策 , 實現專家遷移的智能觸發 。
圖3:基于專家動態遷移的EP間負載均衡整體框架圖
數據重排Attention計算均衡(D) 。 在模型預訓練中普遍采用數據拼接固定長度的策略 , 但跨數據的稀疏Attention計算量差異顯著 , 會引入負載不均衡問題 , 導致DP間出現“快等慢”的資源浪費 。 為解決這一問題 , 華為團隊提出了一種精度無損的動態數據重排方案 , 其核心在于:通過線性模型量化單樣本計算耗時 , 在嚴格保持訓練精度無損下 , 批次內采用貪心算法構建最小化耗時的數據重排 , 實現負載均衡 。
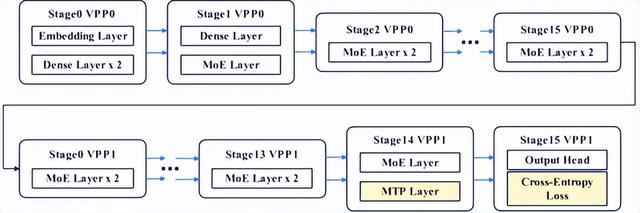
虛擬流水線層間負載均衡(P) 。 MoE模型通常采用混合結構 , Dense層、MTP層、輸出層所在的Stage與純MoE層所在的Stage負載不均 , 會造成的Stage間等待 。 團隊提出虛擬流水線層間負載均衡技術 , 將MTP層與輸出層分離 , 同時將MTP Layer的 Embedding計算前移至首個Stage , 有效規避Stage間等待問題 , 實現負載均衡 。
圖4:基于異構模塊設計的VPP并行負載均衡
整體系統收益回到最開始提到的城市交通場景 , Adaptive PipeEDPB這套方案 , 形象的說就是創新性地引入智慧化交通設施:首先 , 建造\"行人地下通道\"(通信掩蓋) , 徹底分離人車動線 , 使車輛(計算)無需等待即可持續通行 , 行人(通信)在底層獨立穿行;其次 , 部署\"智能可變車道\"(動態專家遷移) , 根據實時車流(數據分布)動態調整車道功能 , 讓閑置的左轉車道也能分擔直行壓力 , 實現負載均衡 , 整體讓城市交通實現無堵車流暢運行 。
在Pangu Ultra MoE 718B模型的訓練實踐中 , 華為團隊在8K序列上測試了Adaptive PipeEDPB吞吐收益情況 , 在最優并行策略的初始性能基礎上 , 實現了系統端到端72.6%的訓練吞吐提升 。
【上帝視角的昇騰MoE訓練智能交通系統讓訓練效率提升70%】
推薦閱讀










- SSM+擴散模型,竟造出一種全新的「視頻世界模型」
- AI拒絕機是人類自找的,因為算法有時候也會「自私」
- 高通的Centriq 2400和Falkor架構
- 國產手機這些新技術,讓我感覺iPhone17真的不香了
- 老人機≠低配機!講個道理,你真的低估老年人的用機習慣
- 看似無害的提問偷走RAG記憶,IKEA:隱蔽高效數據提取攻擊新范式
- 輕薄全能旗艦vivo S30,這個夏天最酷的科技潮品
- 即將發布的5款新機,每一款都很有看點!你最期待哪一款?
- vivo S30 Pro mini影像深度測評:氛圍感直出的藝術
- 原來 2124 元也能有提升幸福感的好手機