
文章圖片
文章圖片
在大語言模型蓬勃發展的背景下 , Transformer 架構依然是不可替代的核心組件 。 盡管其自注意力機制存在計算復雜度為二次方的問題 , 成為眾多研究試圖突破的重點 , 但 Transformer 在推理時靈活建模長距離上下文的能力 , 使得許多線性復雜度的替代方案(如 RNN、Linear Attention、SSM 等)難以真正取代它的地位 。
尤其是在大語言模型廣泛采用 decoder-only 架構之后 , 自注意力機制的重要性進一步凸顯 。 然而 , 這種機制也帶來新的挑戰:推理過程中每一步都需要訪問 Key-Value(KV)緩存 , 該緩存的大小隨著生成序列長度線性增長 , 逐漸成為影響推理效率的關鍵瓶頸 。 隨著模型參數維度不斷擴大 , KV 緩存所需的顯存和帶寬開銷顯著上升 , 限制了模型的推理長度與可支持的 batch size 。
值得一提的是 , 近期由 DeepSeek 團隊提出的 MLA 機制 , 通過在隱空間維度對 KV 緩存進行壓縮 , 顯著提升了推理效率 , 推動了大模型在低資源場景下的高效部署 。 但隨著生成序列的持續增長 , 時間維度的冗余信息也逐漸暴露 , 壓縮其所帶來的潛力亟待挖掘 。 然而 , 如何在保持性能的前提下壓縮時間維度 , 一直受到增量式推理復雜性的限制 。
為此 , 劍橋大學機器智能實驗室最新提出了 Multi-head Temporal Latent Attention(MTLA) , 首次將時序壓縮與隱空間壓縮相結合 , 在 KV 緩存的兩個維度上同時施加時空壓縮策略 。 MTLA 利用超網絡動態融合相鄰時間步的信息 , 并設計了步幅感知的因果掩碼以確保訓練與推理的一致性 , 在顯著降低推理顯存與計算成本的同時 , 保持甚至略優于傳統注意力機制的模型性能 , 為大語言模型推理效率的提升提供了新的解決思路 。
- 論文標題:Multi-head Temporal Latent Attention
- 論文地址:https://arxiv.org/pdf/2505.13544
- 項目地址:https://github.com/D-Keqi/mtla
在構建大語言模型時 , KV 緩存帶來的顯存與計算開銷問題早已受到廣泛關注 。 當前主流的大模型通常采用基于自注意力的 Grouped-Query Attention(GQA)機制 , 對標準 Transformer 中的 Multi-Head Attention(MHA)進行改進 。 GQA 通過減少 Key/Value 頭的數量來減小 KV 緩存的規模 , 具體做法是將多個 Query 頭分組 , 每組共享同一個 KV 頭 。
當 GQA 的組數等于 Query 頭數量時 , 其等價于標準 MHA;而當組數為 1 時 , 即所有 Query 頭共享同一組 KV , 這種極端形式被稱為 Multi-Query Attention(MQA) 。 雖然 MQA 極大地減少了顯存占用 , 但顯著影響模型性能;相比之下 , GQA 在效率與效果之間取得了更好的平衡 , 因此成為當前大語言模型中最常見的注意力變體 。
與此不同 , DeepSeek 團隊提出的 Multi-head Latent Attention(MLA)采用了另一種思路:不減少頭的數量 , 而是在隱空間中壓縮 KV 的特征維度 。 實驗結果表明 , MLA 相較于 GQA 表現出更優的性能與效率 。 然而 , 這種壓縮方式仍存在上限 , 為了維持模型性能 , 隱空間維度的壓縮幅度不能過大 , 因此 KV 緩存的存儲開銷依然是限制模型推理效率的一大瓶頸 。
除了在隱空間對 KV 緩存進行壓縮之外 , 時間維度也是一個極具潛力但尚未充分挖掘的方向 。 隨著生成序列變得越來越長 , KV 緩存中在時間軸上的信息冗余也日益明顯 。 然而 , 由于自注意力機制在生成時通常采用自回歸的增量推理模式 , KV 緩存與每一個生成的 token 是一一對應的 , 這使得在保持模型性能的前提下壓縮時間維度成為一項挑戰 , 也導致了該方向長期缺乏有效解決方案 。
MTLA 的提出正是對這一空白的回應 。 它通過引入時間壓縮機制和步幅感知的因果掩碼 , 巧妙解決了訓練與推理行為不一致的問題 , 在保持高效并行訓練能力的同時 , 實現了推理過程中的 KV 時間壓縮 。 進一步地 , MTLA 還結合了 MLA 的隱空間壓縮策略 , 從空間與時間兩個維度同時優化 KV 緩存的表示 , 將自注意力機制的效率推向了新的高度 。
MTLA 的核心技術與訓練策略
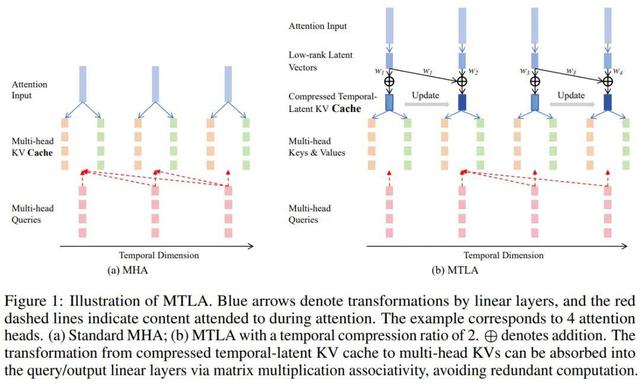
在增量推理階段 , MTLA 會對經過隱空間壓縮后的 KV 緩存進行時間維度的增量式合并 , 進一步壓縮存儲空間 。 上圖展示了該過程的示意 , 并與標準的 MHA 進行了對比 。
以時間壓縮率 s=2 為例 , 每兩個相鄰的 KV 緩存將合并為一個 。 在生成第一個字符時 , KV 緩存長度為 1;生成第二個字符后 , 新生成的 KV 與前一個被合并 , KV 緩存長度仍然保持為 1 。 這種動態合并機制有效壓縮了時間維度上的冗余信息 。
然而 , 這也帶來了并行訓練上的挑戰:雖然兩個時間步的 KV 緩存長度相同 , 但它們所包含的信息不同 , 若不加以區分 , 容易導致訓練與推理行為不一致 。
【時空壓縮!劍橋大學注意力機制MTLA:推理加速5倍,顯存減至1/8】MTLA 通過一種優雅的方式解決了這一問題 。 正如下圖所示 , 在訓練階段 , MTLA 保留了所有中間狀態的 KV 表達 , 并引入了步幅感知因果掩碼(stride-aware causal mask) , 確保每個 query 在訓練時訪問到與推理階段一致的 KV 區域 , 從而準確模擬增量推理中的注意力行為 。
得益于這一設計 , MTLA 能夠像標準注意力機制一樣通過矩陣乘法實現高效并行計算 , 在保持訓練效率的同時完成對時間維度的壓縮 。
此外 , MTLA 還引入了解耦的旋轉位置編碼(decoupled RoPE)來建模位置信息 , 并對其進行了時間維度上的壓縮 , 進一步提升了整體效率 。
值得強調的是 , MTLA 不僅是一種更高效的自注意力機制 , 它還具備極強的靈活性與可調性 。 例如 , 當將時間壓縮率 s 設置得足夠大時 , MTLA 在推理過程中幾乎只保留一個 KV 緩存 , 這種形式本質上就退化為一種線性序列建模方法 。 換句話說 , 線性序列建模可以被視為 MTLA 的極端情況 , MTLA 在注意力機制與線性模型之間架起了一座橋梁 。
然而 , 在許多復雜任務中 , 傳統注意力機制所具備的二次計算復雜度雖然代價高昂 , 卻提供了更強的建模能力 。 因此 , MTLA 所引入的 “可調時間壓縮率 s” 這一設計思路 , 恰恰為模型提供了一個在效率與性能之間靈活權衡的可能空間 。
MTLA 的卓越性能
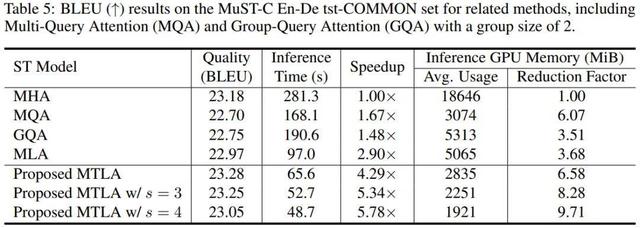
MTLA 在一系列任務中展現了出色的性能 , 包括語音翻譯 , 文本摘要生成 , 語音識別和口語理解 。 例如在語音翻譯中 , MTLA 在保持與標準 MHA 相當的翻譯質量的同時 , 實現了超過 5 倍的推理速度提升 , 并將推理過程中的 GPU 顯存占用降低了超過 8 倍 。
值得注意的是 , 僅當時間壓縮率 s=2 時 , MTLA 對 KV 緩存的壓縮程度就已經與 MQA 相當 , 且在模型性能上更具優勢 。 而相比之下 , MQA 所采用的減少 KV 頭數量的方法已達上限 , 而 MTLA 還有進一步的空間 。
未來發展
MTLA 具備在大規模場景中部署的顯著潛力 , 尤其是在大語言模型參數規模不斷擴大、以及思維鏈等技術推動下生成序列日益增長的背景下 , 對 KV 緩存進行時空壓縮正是緩解推理開銷的關鍵手段 。 在這樣的趨勢下 , MTLA 有望成為未來大語言模型中自注意力模塊的重要替代方案 。
當然 , 與 DeepSeek 提出的 MLA 類似 , MTLA 相較于 GQA 和 MQA , 在工程落地方面的改動不再是簡單的一兩行代碼可以實現的優化 。 這也意味著要將其大規模應用到現有 LLM 框架中 , 還需要來自社區的持續推動與協同開發 。
為促進這一過程 , MTLA 的實現代碼已全面開源 , 希望能夠為研究者與工程實踐者提供便利 , 共同推動高效注意力機制在大模型時代的落地與普及 。
推薦閱讀















- 不止實時翻譯,時空壺用L1-L5分級,揭示AI同傳的未來
- 影視颶風“開炮”視頻下架,“畫質壓縮”事件平臺冤不冤?
- 動了誰的奶酪 “揭露各平臺壓縮視頻畫質”的視頻為何全網下架?
- 看了網飛的1080P才知道什么叫做真正的高清視頻,無銳化無壓縮
- 格力空調e1是什么故障
- 冰箱發出響聲是怎么回事
- 冷藏柜噪音大是什么原因
- 壓縮面膜敷多久效果最好,壓縮面膜怎么用?
- 壓縮機工作原理是什么,壓縮機工作原理
- 時空伴隨是綠碼就不用隔離嗎,時空伴隨者需要隔離14天嗎 時空伴隨者黃碼幾天可以變綠碼