
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
本文第一作者杜恒輝為中國人民大學二年級碩士生 , 主要研究方向為多模態大模型視聽場景理解與推理 , 長視頻理解等 , 師從胡迪副教授 。 作者來自于中國人民大學 , 清華大學和北京騰訊 PCG AI 技術中心 。
我們人類生活在一個充滿視覺和音頻信息的世界中 , 近年來已經有很多工作利用這兩個模態的信息來增強模型對視聽場景的理解能力 , 衍生出了多種不同類型的任務 , 它們分別要求模型具備不同層面的能力 。
過去大量的工作主要聚焦于完成單一任務 , 相比之下 , 我們人類對周圍復雜的的世界具有一個通用的感知理解能力 。 因此 , 如何設計一個像人類一樣對視聽場景具有通用理解能力的模型是未來通往 AGI 道路上一個極其重要的問題 。 當前主流的學習范式是通過構建大規模的多任務指令微調數據集并在此基礎上直接做指令微調 。 然而 , 這種學習范式對于多任務學習而言是最優的嗎?
最近中國人民大學高瓴人工智能學院 GeWu-Lab 實驗室 , 清華大學和北京騰訊 PCG AI 技術中心合作發表的 CVPR 2025 論文指出 , 當前這種主流的學習范式忽視了多模態數據的異質性和任務間的復雜關系 , 簡單地將所有任務聯合訓練可能會造成任務間的相互干擾 。
為了有效實現任務間的顯示互助 , 作者團隊提出了多模態大模型學習的新范式 , 分別從數據和模型兩個角度實現了多模態場景理解任務的高效一統 , 并在多個場景理解任務上超過了垂類專家模型 , 數據集、模型和代碼全部開源 。 目前工作還在進一步拓展中 , 歡迎感興趣的領域專家加入 , 共同構建一個統一的理解、生成與推理的框架 。 如有興趣 , 請郵件聯系 dihu@ruc.edu.cn 。
- 論文標題:Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
- 論文鏈接:https://arxiv.org/abs/2503.13068
- 項目主頁:https://github.com/GeWu-Lab/Crab
統一的多模態場景理解能力展示
時序定位
輸入一段音視頻 , 讓模型找到發生的音視頻事件并定位出時序片段 。
空間定位
輸入一段音頻和一張圖像 , 讓模型定位出圖片中發聲的物體為止 。
時空推理
輸入一段樂器演奏的音視頻場景 , 讓模型回答相關問題 , 涉及到時序和空間信息的理解以及推理 。
像素級理解
輸入一段音頻和一張圖片 , 讓模型分割出圖片中發聲的物體 , 具體包含 S4 MS3 AVSS 和 Ref-AVS 等多種分割任務 。
視覺和聽覺信息是我們人類接觸最多的兩類信息 , 近年來已經有很多工作開始探究基于這兩個模態的視聽場景理解任務 , 主要可以分為時序定位、空間定位、像素級理解和時空推理等四種不同類型的任務 , 它們分別要求模型具備不同層面的能力 。 過去大量的工作聚焦于完成單一任務 , 相比之下 , 我們人類對周圍復雜的世界具有一個通用的感知理解能力 。 因此 , 讓模型也像人類一樣具有統一的視聽場景理解能力是具有重要意義的 。
隨著多模態大語言模型的發展 , 構建大規模的指令微調數據集并將各種不同的任務直接進行聯合訓練已經成為當前主流的學習范式 。 然而 , 這種學習范式忽視了多模態數據的異質性和任務間的復雜關系 , 簡單地將所有任務聯合訓練可能會造成任務間的相互干擾 , 這種現象在之前的工作中已經被證實 , 并且這個問題對于任務間差異較大的視聽場景理解任務來說則更為重要 。 為了有效解決上述問題 , 本文分別從數據和模型的角度針對性地提出了一個統一的顯示互助學習范式來有效實現任務間的顯示互助 。 為了明確任務間的互助關系 , 首先構建了一個具有顯示推理過程的數據集 AV-UIE , 它包含具體的時序和空間信息 , 可以有效建立任務間的互助關系 。 然后為了進一步在學習過程中促進任務間的相互協助 , 本文提出了一種具有多個 Head 的類 MoE LoRA 結構 , 每個 Head 負責學習多模態數據交互的不同層面 , 通過這種結構將模型的不同能力解耦 , 讓任務間的互助關系顯示地展現出來 , 共享的能力在不同任務間建立起相互協助的橋梁 。
【CVPR 2025 | 多模態統一學習新范式來了,數據、模型、代碼全部開源】
AV-UIE: 具有顯示推理過程的視聽場景指令微調數據集
從數據的角度來看 , 現有視聽場景理解數據集的標簽是簡單的單詞或者短語 , 這樣簡單的標簽在訓練過程中并不能顯著地幫助到其它任務 , 或者說只能以一種隱式的方式增強模型的訓練效果 , 我們并不能確保一定是對其它任務有幫助的 。 為了進一步地促進任務間的顯示互助并將互助關系顯示地體現出來 , 本文提出了具有顯示推理過程的視聽場景指令微調數據集 AV-UIE , 通過細化現有數據集的標簽 , 額外增加了顯示的推理過程 , 其中包含具體的時空信息 , 這些信息明確了任務間的互助關系 。
圖 1. 具有顯示推理過程的 AV-UIE 數集構造流程和統計分析
圖 1 展示了具體的構建過程以及對數據集的統計分析 , 通過 in-context learning 的方式利用現有的強大的多模態大模型進行標注 , 從不同任務中的數據中獲取音視頻場景 , 為了保證結果的準確性和推理過程的合理性 , 原有數據的標簽也作為輸入 , 讓 Gemini 1.5 Pro 針對該場景輸出帶有時序和空間等信息的顯示推理過程 。 為了保證數據的質量 , 最終再由人工進行檢查糾正 。 在訓練過程中這些細化后的標簽能夠鼓勵模型準確理解視聽場景內容并輸出相應的時空信息 , 以此來增強模型特定的能力 , 從而幫助到其它依賴這些特定能力的任務 。 圖 2 展示了 AVQA 和 AVVP 這兩種任務實現顯示互助的數據樣例 , 不同的顏色表示不同類型的時空信息 , 這兩個任務都能夠受益于增強后的空間定位和時序定位能力 。
圖 2. AVQA 和 AVVP 任務通過顯示推理過程實現相互幫助的示例
AV-UIE 數據集包含九種任務的數據 , 總共 200K 訓練樣本 。 其中 , 時序定位任務包含 AVE 和 AVVP , 數據占比 6.8% , 空間定位任務包含 ARIG , 數據占比 25.8% , 像素級理解任務包含 S4 , MS3 , AVSS 和 Ref-AVS , 數據占比 41.6% , 時空理解任務包含 AVQA , 數據占比 25.8% 。 相比于其它的指令微調數據集 , 盡管每一個任務的訓練樣本數比較小 , 但是在顯示推理過程的幫助下 , 任務間的顯示互助仍然可以增強模型在單個任務上的性能 。
Crab: 實現任務間顯示互助的統一學習框架
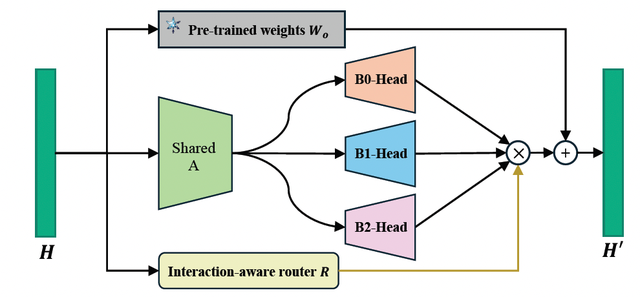
從數據的角度保證了模型可以輸出帶有時序信息的顯示推理過程 , 這是從結果上對模型進行約束 , 顯示地增強不同類型的能力 , 但是如何保證模型在學習過程中可以有效地學到這些不同的能力呢?為此 , 本文提出了一個視聽場景理解的統一學習框架 , 圖 3 展示了模型的整體架構 , 主要包括三個統一的多模態接口 , 分別用來處理 audio visual 和 segmentation mask 數據 , 一個具有 interaction-aware LoRA 結構的大模型 , 用于在學習過程中有效學習數據交互的不同層面從而實現任務間的顯示互助 。
圖 3. 模型總體架構
傳統的 LoRA 結構由一組對稱的 A 矩陣和 B 矩陣組成 , 用于在下游任務上高效微調模型 , 具有多組對稱的 AB 矩陣的 LoRA MoE 結構通常被用來多任務微調 , 每一組 LoRA 負責解決單個任務 。 為了進一步地促進任務間的相互協助 , 本文提出的 Interaction-aware LoRA 結構(如圖 4 所示)由一個共享的 A 矩陣和多個不同的 LoRA Head B 矩陣組成 , 每個 Head 期望去學習數據交互的不同層面 , 進而具備不同的能力 。 為了有效區分不同的 Head , 額外增加一個 Router 用來給不同的任務分配不同的權重 。 例如 , 在學習過程中 , 時空推理任務 AVQA 聚焦于增強模型的時序和空間定位能力 , 那么就會更多的激活對應 Head 的參數 , 增強它們特定的能力 , 而其它的時序定位和空間任務都可以受益于這些增強后的 Head 。 從這個角度來說 , 模型的能力被解耦成多個特定的能力 , 模型可以顯示地依賴這些能力完成不同類型的任務 , 而多個任務間共享的能力建立起了任務間協助的橋梁 。
圖 2. 具有多個 LoRA head 的 Interaction-aware LoRA 結構
實驗與分析
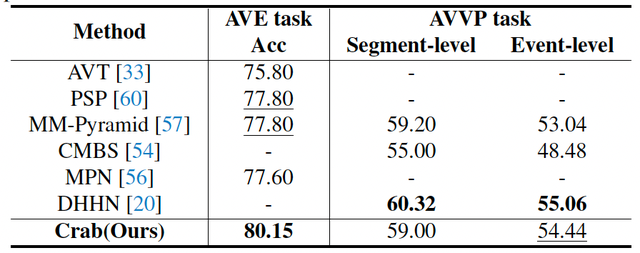
為了證明顯示互助學習范式的有效性 , 本文分別對比了在所有任務上通用的模型以及在單個任務上專有的模型 , 并提供了全面的消融實驗對比結果 。 表 1 展示了與多個任務上的通用模型的對比結果 , 相比于其它模型 , 本文提出的 Crab 統一學習框架在所有類型的任務上具有更加通用的理解能力 , 并且在多個任務上取得了更好的表現 。 這表明了 Crab 在視聽場景通用理解能力方面的優越性 。
表 1. 與多個任務上的通用模型的對比結果
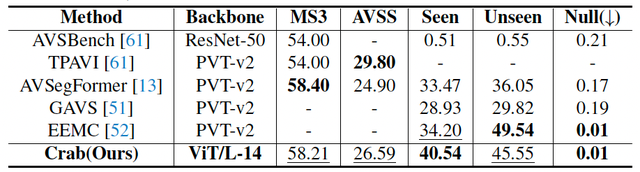
表 2 , 3 , 4 , 5 分別展示了與時序定位、空間定位、像素級理解和時空推理等四種類型任務的專有模型對比結果 , 可以看到在 AVE、ARIG、AVQA 等任務上 Crab 均優于單個任務上的專有模型 , 在 AVVP 和 AVS 任務上取得了相近的表現 。 表 6 展示了全面的消融實驗結果 , 相比于單個任務 , 簡單的多任務 LoRA 微調并不能充分實現任務間的相互協助 , 甚至在一些任務上可能會降低性能 。 相比之下 , 在顯示互助的學習范式下 , 任務間的相互干擾被有效緩解 , 任務間的相互協助提高了單個任務的性能 。
表 2. 與時序定位任務專有模型對比結果
表 3. 與空間定位任務專有模型對比結果
表 4. 與像素級理解任務專有模型對比結果
表 5. 與時空推理任務專有模型對比結果
表 6. 全面的消融實驗對比結果
為了進一步證明任務間顯示互助的過程 , 本文對多個 LoRA Head 進行了可視化分析實驗 。 在推理過程中 , 對于每個任務的多模態輸入數據 , 每個 LoRA Head 會產生一個權重 , 權重越大 , 表明完成該任務越依賴于這個 Head 。 圖 3 對比了 3 個 Head 在不同任務上的權重 , 左圖是 B1 和 B2 , 右圖是 B2 和 B3 。 可以發現兩點:1)相同類型的任務對不同 Head 的依賴程度是類似的 , 它們對不同 Head 的依賴權重分別形成不同的簇;2)不同任務對 3 個 Head 的不同依賴性表明每個 Head 具備不同的能力 。 這表明模型的能力被解耦成多種不同的能力 , 多個任務間可能會依賴于同一種能力 , 因此它們可以建立相互協助的關系 。
圖 3. 3 個 LoRA Head 的權重可視化
總述
本文分別從數據和模型的角度出發 , 提出了統一視聽場景理解的顯示互助范式來實現任務間的顯示互助 , 大量的實驗結果以及可視化分析均證明了該范式的有效性 。 我們希望本文提出的想法可以為該領域的發展提供新的研究視角 , 并且在未來的工作中我們將聚焦于多模態推理的新范式 , 希望將現有的多模態推理工作提升到一個新的高度 。
推薦閱讀













- IGN公布2025年度五大顯卡推薦,N卡僅兩款上榜
- SIGGRAPH 2025獎項出爐:上科大、廈大入選最佳論文
- 西部數據亮相 IDCE 2025 ,全矩陣數據中心產品引領存儲“底座”革新
- 新買的華為手機,一定要完成這4步設置,手機能多用好幾年!
- 這么多年了,為什么臺式機還處于組裝(DIY)階段?
- 博主曝vivo X Fold5三防性能:可以水下折疊,且填補了多項行業空白
- 美光宣布向多個關鍵客戶出樣 HBM4 36GB 12Hi 內存
- 小米千元機有多能打?這3款性價比高,618不要錯過了
- 華為新品震撼發布 鴻蒙5全面覆蓋手機、平板、電腦、穿戴等全場景多終端
- 藍牙音箱哪個牌子音質最好?2025年分享十大音質最好的小音箱!