
文章圖片
文章圖片

文章圖片
文章圖片

AI從醫療工具變身為協作隊友 , 斯坦福大學研究揭示:醫生診斷準確率竟飆升10%!70名美國執業醫生參與的真實測試 , AI-first、AI-second與傳統診斷 , 誰能更精準破解臨床謎題?
你敢讓AI幫你看病嗎?
斯坦福大學的一群醫生和工程師 , 最近做了一項研究:讓AI和人類醫生組隊 , 共同破解復雜的診斷難題 。
論文鏈接:https://www.medrxiv.org/content/10.1101/2025.06.07.25329176v1.full.pdf
結果讓人驚訝:當AI從「工具」變成「隊友」 , 醫生的診斷準確率直接飆升了10% 。
【98%醫生點贊的AI隊友,斯坦福實驗揭秘:診斷準確率飆升10%】網友驚嘆:顛覆的臨界點即將到來!
「充滿熱情的醫生加上AI將勢不可擋 。 」
「AI驅動的臨床決策支持 , 仍然是該領域最有力的杠桿之一 。 」
還有人表示 , 「對于一個背負數十萬美元債務的醫生來說 , 這種發現有點令人害怕 。 這還只是用GPT 4 , 無法想象o3會有多厲害 。 」
AI當醫生 , 搶飯碗還是遞扳手?過去幾年 , AI在醫療領域的存在感越來越強 , 從影像識別到藥物研發 。
但醫生把它當搜索工具 , 用來查指南、找文獻 , 卻不敢真正把它當作「搭檔」 。
為什么會這樣?斯坦福的研究團隊發現 , 關鍵問題出在交互模式上 。
早期的AI就像個沉默的助手 , 醫生輸入問題 , 它輸出答案 。
這導致醫生很難信任AI的判斷 , 甚至出現過「醫生用AI輔助診斷 , 結果反而比AI單獨診斷更差」的情況 。
于是 , 他們決定做一個顛覆性實驗:把AI變成會討論的隊友 。
實驗設計很巧妙:讓醫生和AI各自先獨立分析病例 , 然后AI生成一份聯合報告 , 不僅列出雙方的共識和分歧 , 還會像資深醫生一樣點評每個診斷的合理性 。
比如 , 當醫生考慮真性紅細胞增多癥 , AI會補充低EPO水平支持這一診斷 , 但需排除罕見的EPO分泌腫瘤 。
當醫生漏掉淋巴瘤的可能性 , AI會提醒瘙癢和尿酸升高可能是這個方向 。
團隊基于GPT-4開發了一款定制化的AI系統 , 設計了兩種協作工作流程 , 分別測試AI-first和AI-second時的效果 。
70名美國執業的內科或家庭科醫生參與了這項試驗 , 他們被隨機分配到以下三種組別之一:
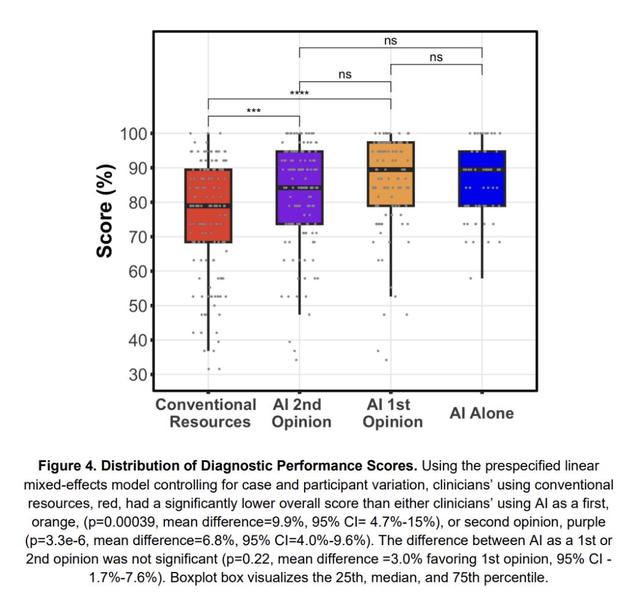
AI-first組:醫生首先輸入病例信息 , 查看AI生成的診斷建議(包括五個可能的診斷和七個后續步驟) , 然后結合自己的判斷形成最終診斷 。AI-second組:醫生先獨立完成診斷(可以使用傳統資源如UpToDate、PubMed等) , 再將病例和自己的初步診斷輸入AI系統 , AI會生成獨立分析并與醫生的診斷進行整合 , 生成一份綜合報告 。對照組:醫生僅使用傳統資源完成診斷 , 不與AI互動 。實驗使用了六個基于真實患者的臨床病例 , 涵蓋了復雜診斷場景 。每個病例包含病史、體檢和實驗室檢查結果 , 醫生需要提供三個可能的診斷、支持和反對的證據、最終診斷及三個后續步驟 。研究通過19分制的評分系統評估診斷的準確性 , 評分由兩位內科認證醫生獨立完成 , 且評分者不知道答案來自醫生還是AI , 以確保公平 。AI系統的核心設計在于協作 。它不僅生成自己的診斷 , 還會對比醫生和AI的判斷 , 生成一份綜合報告 , 清晰列出雙方提出的診斷、共識點、分歧點 , 并對每個診斷提供評論 。這種設計旨在激發醫生的批判性思考 , 而非簡單依賴AI的輸出 。研究結果:AI顯著提升診斷準確性 研究結果令人振奮 , AI協作組的醫生表現明顯優于僅使用傳統工具的對照組 。診斷準確性: 對照組(傳統工具):平均得分75% 。AI-first組:平均得分85% , 比對照組高9.8%(p AI-second組:平均得分82% , 比對照組高6.8%(p AI單獨運行:平均得分90% , 略高于協作組但差異不顯著 。醫生和AI協作后 , 雖然沒超過AI單獨水平 , 卻比醫生單打獨斗強 。 這說明 , AI能補全人類思維的漏洞 。在最終診斷和后續步驟(即臨床上可操作的決策)方面 , AI-first比AI-second組表現更好(高8.9% , p=0.026) 。AI-second相較于對照組在這些決策上的得分提升了14.9%(p=0.00092) , 其中36%的病例在與AI互動后有所提高 。AI-first完成每個病例的平均時間為631秒 , 略快于AI-second的688秒 。 在剔除未嚴格遵循流程的病例后 , AI-first的優勢更明顯 。所有醫生在試驗后對AI的態度顯著改善 , 98.6%表示愿意在復雜臨床推理中使用AI(試驗前為91.4% , p=0.011) 。為什么AI當隊友更厲害? 信息過載與遺漏:臨床診斷就像拼拼圖 , 每個病例可能包含幾十條線索 。醫生很容易漏掉某個實驗室指標(比如「血清LDH升高」提示細胞破壞) , 但AI能瞬間掃描所有數據 , 精準關聯高LDH+巨幼細胞貧血可能指向骨髓增生異常綜合征 。經驗依賴的陷阱:資深醫生容易被典型病例固化思維 。比如看到老年女性、乏力、舌炎 , 可能優先考慮缺鐵性貧血 , 但AI會跳出經驗框架 , 提出維生素B12缺乏或甲狀腺功能減退的可能性 。決策鏈的邏輯性:AI的診斷報告就像思維流程圖:先列出3個最可能的診斷 , 再用支持證據和反對證據逐條論證 , 最后給出3個下一步檢查建議 。AI的「人性化改造」 為了讓AI更懂醫生 , 研究團隊給它加了三個補丁 。1. 會「吵架」的批判性思維:當醫生的診斷和AI不一致時 , AI不會直接服從 , 而是會說:「您提到的原發性膽汁性膽管炎可能性較低 , 因為患者缺乏膽汁淤積的證據 , 但需要注意罕見變異型 。 」 這種挑戰不是對抗 , 而是逼醫生重新審視自己的邏輯漏洞 。2.能「翻譯」的溝通能力:傳統AI輸出的是學術化的語言 , 但實驗中的AI會用口語化表達:「目前看 , 真性紅細胞增多癥是最可能的 , 但淋巴瘤不能完全排除 , 建議先查血清EPO水平和骨髓活檢 。 」 這種說人話的能力 , 讓醫生更容易理解和接受 。3.可「追溯」的透明化決策:每個診斷結論 , AI都會標注證據來源 , 比如「支持淋巴瘤的證據是瘙癢和尿酸升高(引用文獻X) , 反對證據是缺乏淋巴結腫大(引用指南Y) 。 」 這解決了醫生對AI黑箱決策的不信任感 , 讓協作建立在可驗證的基礎上 。AI的「錨定效應」 研究發現 , AI-second組中 , AI的獨立分析有時會受到醫生初步診斷的影響 。實驗中有個有趣的細節:AI-second組中 , 48%的病例中AI的診斷和醫生初始意見完全重疊 , 而AI-first組僅為3% 。說明如果醫生先入為主給出思路 , AI可能會「迎合」人類判斷 , 未能完全遵循獨立分析的指令 。比如 , 有個病例中醫生誤判缺鐵性貧血 , AI在后續分析中居然也把這個診斷放在了第一位 。 盡管按照數據 , 維生素B12缺乏才是更合理的方向 。這意味著 , AI的批判性依賴于獨立思考的空間 , 一旦被人類思維錨定 , 反而會降低協作價值 。但反過來 , 當AI先發言時 , 醫生會更主動地挑戰它的結論 。有位住院醫師在看到AI提出骨髓瘤時 , 立刻反駁:患者沒有骨痛和蛋白尿 , 這個診斷可能性太低 , 并最終通過追問病史排除了這一方向 。這種「對抗性協作」 , 反而激發了更深入的臨床推理 。參考資料 https://x.com/emollick/status/1931907652118069510 https://www.medrxiv.org/content/10.1101/2025.06.07.25329176v1 本文來自微信公眾號“新智元” , 作者:英智, 36氪經授權發布 。
推薦閱讀












- 好評率高達98%,銷量早已突破100萬臺!這款“千元旗艦”值得買
- 新華社點贊小米,華為新機開售,OPPO新機曝光
- 雷軍再秀紐北成績,華為Pura 80全網點贊,vivo直接放出真機
- 599元拍立得平替!小米發布米家口袋照片打印機Pro,相紙僅1.98元
- watchOS 26:Apple Watch會點贊了
- 這椅子不簡單!9800X3D+RTX 4060塞進電競椅:一根線即可運行
- Hinton夢想的AI醫生要來了,斯坦福哈佛實測:o1以78%正確率超人類
- 7200mAh+京東方屏,紅米K80至尊版最強對手“大跳水”,僅1989
- 激活銷量498萬!華為mate 70系列降價后,銷量暴漲
- 真我“踢館”,天璣9400+芯片、7200mAh電池,補貼到1989元