
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
Google DeepMind團隊開發的DataRater可以全自動評估數據質量 , 通過元學習自動篩選有價值的數據 , 提升模型訓練效率 。 DataRater使用元梯度優化 , 能有效減少訓練計算量 , 提高模型性能 , 尤其在低質量數據集上效果顯著 , 且能跨不同模型規模進行泛化 。
機器學習領域有一條鐵律 , 「Garbage In Garbage Out.」 , 就是說模型的質量很大程度上取決于訓練數據的質量 。
大模型在預訓練階段會吸收海量的數據 , 其中數據的來源非常雜 , 導致質量參差不齊 。
大量的實驗和經驗已經證明了 , 對預訓練數據進行質量篩選是提高模型能力和效率的關鍵 。
常規做法是直接人工篩選數據源 , 或是對不同數據源編寫啟發式規則篩選出高質量數據 , 再手動調整 , 工作量非常大 。
隨著合成數據的盛行 , 把一些偏差、重復、質量低下的數據都加入到預訓練數據集中 , 進一步擾亂了模型的性能分析 。
最近 , Google DeepMind的研究人員發布了一個數據質量評估框架DataRater , 可用于估計任意數據對最終訓練效果的價值 , 即數據質量 。
論文鏈接:https://arxiv.org/pdf/2505.17895
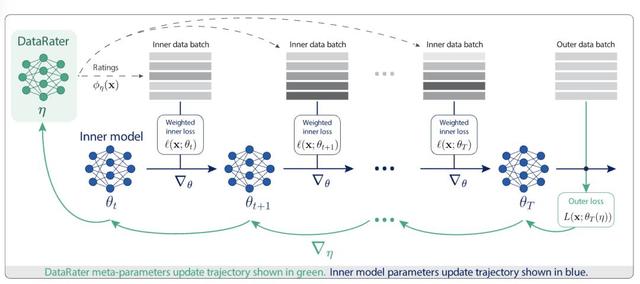
DataRater的核心思路是使用「元學習」來自動學習篩選或混合數據流的標準 , 以一種數據驅動的方式 , 讓數據展現出本身的價值 。
指定訓練目標(提高在保留數據上的訓練效率、更小的驗證損失值)后 , DataRater使用元梯度(根據數據與性能之間的聯系進行計算)進行訓練 , 可以極大減少訓練計算量以匹配性能 , 提升樣本效率 , 高效地篩選出低質量訓練數據集 。
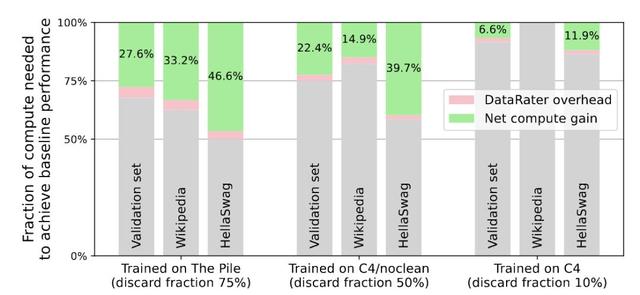
實驗表明 , 經過DataRater篩選的數據大幅減少了訓練所需的浮點運算次數(最高可達46.6%的凈計算收益) , 并且可以提高跨多種預訓練語料庫(例如 , Pile、C4/noclean)語言模型的最終性能 。
在性能分析上 , DataRater也能夠學會識別并降低「符合人類對低質量數據直覺」的數據權重 , 比如文本編碼錯誤、OCR錯誤或者無關內容等 。
最重要的是 , 使用固定規模內部模型(4億參數)進行元訓練的DataRater模型 , 能夠有效地將其學到的數據估值策略泛化 , 以對更大規模模型(5000萬到10億參數)的訓練也同樣有效 , 并且最佳數據丟棄比例也是一致的 。
數據質量評估器DataRater 過濾問題假設我們的訓練目標是開發一個預測器 , 可以根據輸入數據做出預測 , 對于大語言模型來說 , 輸入數據是一組token序列 , 比如一段文本 。
構造訓練集后 , 需要定義一個「損失函數」來衡量其在該數據集上預測的準確性;
在另一個不同分布的測試集上 , 可能需要定義一個新的損失函數來評估其性能 。
學習算法會從訓練集中隨機選取一批數據 , 然后根據這些數據來更新模型參數 , 經過多次迭代后 , 模型參數最終確定下來 。
【75%預訓練數據都能刪,Jeff Dean新作:全自動篩除低質量數據】模型在該測試集上的表現 , 可以用來衡量算法性能 。
過濾過程的目標是從訓練集中找到最合適的子集 , 使得最終模型在測試集上的誤差最小 。
因為學習算法通常無法找到最優的參數 , 所以在精心挑選的數據子集上訓練速度會更快 。
DataRater算法研究人員采用了一種連續的松弛方法 , 用三步來選擇要保留哪些數據:
1. 在每一步的梯度計算中 , 決定哪些數據點要包括進去 , 類似于給每個數據點分配一個「重要性」權重;
2. 將「重要性」權重從二進制(選/不?。 ┍湮鬧擔ǚ段Т?到1) , 可以用來做梯度加權 , 同時確保每個批次中所有權重的總和為1 , 以保持梯度的規模不變 。
3. 用一個評分函數來表示權重 , 無需為每個數據點單獨列出一個權重 , 其中評分函數會根據每個數據點的價值來給出一個分數 , 然后通過softmax函數將分數轉化為歸一化的權重 。
在每一步 , DataRater會從訓練集中隨機選取一批數據 , 然后根據數據的權重來更新模型的參數 , 最終可以得到一個參數向量 。
為了優化過濾算法 , 算法的目標是找到一個評分函數的參數 , 使得最終模型在測試集上的預期誤差最小 。
元優化研究人員采用元梯度方法 , 通過隨機梯度法來大致優化參數:
計算損失函數(外層損失 , outer loss)相對于參數的梯度 , 其梯度通過反向傳播經過多次針對模型參數的優化更新(內層損失 , inner loss)來計算 。
元學習目標:假設訓練數據集和測試數據集具有相同的分布 , DataRater算法無需針對某個特定的下游任務進行優化 , 只需要最大化給定數據集的訓練效率 。
數據評估的外層損失所依據的「保留數據」是「輸入訓練數據的一個不相交的子集」 , 其目標是「生成給定原始數據集的一個精選變體」 , 實現更快的學習效率 。
內層和外層損失具有相同的函數形式 , 即針對下一個token預測的交叉熵損失 。
研究人員使用non-causal Transformer來實現DataRater模型 , 基于元梯度下降法來優化其參數 。
實驗結果為了評估DataRater在構造數據集方面的有效性 , 研究人員用三步方法進行評估:
1. 為指定輸入數據集「元學習」出一個數據評分模型(DataRater);
2. 使用訓練好的數據評分模型來構造測試集;
3. 從隨機初始化開始 , 在構造的數據集上訓練不同規模(5000萬、1.5億、4億和10億參數)的語言模型 , 隨后評估其性能 。
語言模型和DataRater模型都基于Chinchilla架構 , 模型從隨機初始化開始訓練 , 遵循Chinchilla的訓練協議和token預算 。
研究人員在C4、C4/noclean和Pile驗證集以及英文維基百科上測量負對數似然(NLL)值 , 在HellaSwag、SIQA、PIQA、ARC Easy和Commonsense QA下游任務上測量準確率 。
達到10億參數模型基線性能所需的計算量的比例 , 以在DataRater模型篩選后的數據集上達到最終基線性能所需的訓練步數為指標
DataRater模型能否加速學習?對于像Pile和C4/noclean這樣質量較差的數據集 , 節省了大量的浮點運算(FLOPS) 。
對于10億參數的模型 , 下圖展現了使用DataRater模型相比基線訓練節省的計算量 , 包含了數據篩選過程的計算開銷 。
10億參數模型訓練過程中的性能指標
結果表明 , 使用數據評分模型篩選后的數據集不僅加快了學習速度 , 還能提高模型的最終性能 。
元訓練一個DataRater模型大約需要訓練一個單個10億參數的大型語言模型(LLM)所需的58.4%的浮點運算 。
不過 , DataRater模型篩選后的數據集可以用于訓練更大規模的模型 , 可以分攤訓練成本 。
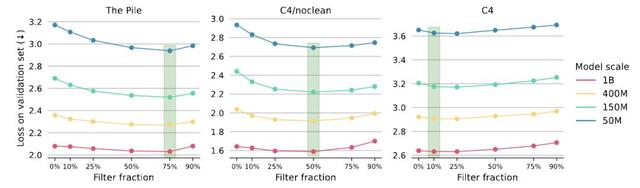
應該移除多少數據?為了確定每個數據集的最佳丟棄比例 , 研究人員測試了5種候選丟棄比例(10%、25%、50%、75%和90%) , 使用最小的模型(5000萬參數) , 并選擇了在驗證集上負對數似然(NLL)表現最佳的丟棄比例 。
結果顯示 , 使用最小尺寸模型是足夠的 , 因為最佳丟棄比例在不同模型大小之間是共享的 。
最優值取決于底層數據的質量:對于C4 , 丟棄10%;對于C4/noclean , 丟棄50%;對于Pile , 丟棄75%
DataRater是否穩?。 ?研究人員為每個數據集訓練了一個數據評分模型 , 內部模型尺寸固定為4億參數 。
DataRater模型能夠跨模型規模泛化:在對3個輸入數據集、4種模型規模和7種指標的實驗中 , 73/84個實驗都展現出了性能提升 。
對于質量較低的數據集 , 如C4/noclean和Pile , 在NLL指標和HellaSwag任務上 , 性能提升在不同尺寸模型上是一致的 , 但在下游評估中的差異則更多 。
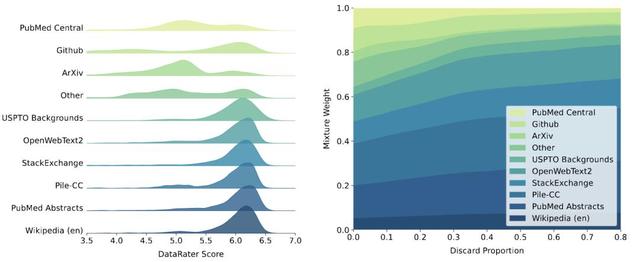
DataRater模型學到了什么?DataRater可以為不同的數據子集分配細致的評分 , 左長尾效應代表了「在很低丟棄比例下也仍然應該被丟棄的數據點」 。
隨著丟棄比例的增加 , DataRater模型還學會了在混合層面上重新加權數據 。
DataRater模型能夠識別低質量的數據 , 比如Pile數據集上被分配低評分的樣本往往是低質量的 。
上圖顯示的例子中 , 錯誤的文本編碼、光學字符識別(OCR)錯誤、大量空白符、非打印字符、高熵文本(如數字或字符串數據的列表和表格)以及私有SSH密鑰、全大寫的英文、多語言數據(Pile包含超過97%的英文數據)等都被識別出來了 。
參考資料https://x.com/fly51fly/status/1927120407796027465
推薦閱讀










- 紅米努力沖銷量,7550mAh+金屬中框低至1486元起,跑分可達240萬
- 小米MIX Flip 2開啟預約:搭載驍龍8至尊版 唯一滿配旗艦小折疊
- REDMI兩款新品預熱:K80至尊版+旗艦小平板,主打豪華性能體驗
- 搜索智能體RAG落地不佳?UIUC開源s3,僅需2.4k樣本,訓練快效果好
- 小米新機官方預熱:搭載「玄戒O1」,即將發布
- 英特爾退役銳炫A770/750顯卡:計劃為新產品讓路?
- 小米“續航王”突然變香了,1TB+7550mAh,沖上新機熱銷榜第一名
- 太菜,還得多練!蘋果AI Siri預計推遲到2026年春季才發布
- 紅米新機官方預熱:6月份,即將發布
- 瘋狂搶奪英偉達工程師!黃仁勛:不再將中國市場納入業績預測 業務被迫讓給華為