
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
【搜索智能體RAG落地不佳?UIUC開源s3,僅需2.4k樣本,訓練快效果好】
當前 , Agentic RAG(Retrieval-Augmented Generation)正逐步成為大型語言模型訪問外部知識的關鍵路徑 。 但在真實實踐中 , 搜索智能體的強化學習訓練并未展現出預期的穩定優勢 。 一方面 , 部分方法優化的目標與真實下游需求存在偏離 , 另一方面 , 搜索器與生成器間的耦合也影響了泛化與部署效率 。
我們(UIUC & Amazon)提出的 s3(Search-Select-Serve)是一種訓練效率極高、結構松耦合、生成效果導向的 RL 范式 。 該方法使用名為 Gain Beyond RAG (GBR) 的獎勵函數 , 衡量搜索器是否真的為生成帶來了有效提升 。 實驗表明 , s3 在使用僅 2.4k 訓練樣本的情況下 , 便在多個領域問答任務中超越了數據規模大百倍的強基線(如 Search-R1、DeepRetrieval) 。
- 論文標題:s3: You Don’t Need That Much Data to Train a Search Agent via RL
- 論文鏈接:https://arxiv.org/pdf/2505.14146
- 代碼倉庫:https://github.com/pat-jj/s3
研究動機
RAG 的發展軌跡:從靜態檢索到 Agentic 策略
我們將 RAG 系統的發展分為三階段:
1.Classic RAG:使用固定 query、BM25 等 retriever , 生成器對結果無反?。 ?
2.Pre-RL-Zero Active RAG:引入多輪 query 更新 , 如 IRCoT、Self-RAG 等 , 部分通過 prompt 引導 LLM 檢索新信息 。 Self-RAG 進一步通過蒸餾大型模型的行為 , 訓練小模型模擬多輪搜索行為;
3.RL-Zero 階段:強化學習開始用于驅動檢索行為 , 代表方法如:
- DeepRetrieval:以 Recall、NDCG 等搜索指標為優化目標 , 專注于檢索器本身的能力;
- Search-R1:將檢索與生成聯合建模 , 以最終答案是否 Exact Match 作為強化信號 , 優化整合式的搜索 - 生成策略 。
當前 RL-based Agentic RAG 落地表現不佳的原因
我們對當前 Agentic RAG 方案效果不穩定、訓練難、遷移能力弱的原因 , 歸納為三點:
1. 優化目標偏離真實下游任務
Search-R1 等方法采用 Exact Match (EM) 作為主要獎勵指標 , 即答案是否與參考答案字面一致 。 這一指標過于苛刻、對語義變體不敏感 , 在訓練初期信號稀疏 , 容易導致模型優化「答案 token 對齊」而非搜索行為本身 。
例如 , 對于問題「美國第 44 任總統是誰?」 ,
- 回答「Barack Obama」:?
- 回答「The 44th president was Barack Obama.」:?(EM=0)
2. 檢索與生成耦合 , 干擾搜索優化
將生成納入訓練目標(如 Search-R1) , 雖然可以提升整體答案準確率 , 但也會帶來問題:
- 無法判斷性能提升究竟來自「更好的搜索」 , 還是「更強的語言生成對齊能力」;
- 對 LLM 參數依賴強 , 不利于模型遷移或集成;
- 微調大模型成本高 , 限制了訓練效率和模塊替換的靈活性 。
3. 現有評價標準無法準確衡量搜索貢獻
EM、span match 等傳統 QA 指標主要關注輸出結果 , 與搜索質量關聯有限 。 而 search-oriented 指標(如 Recall@K)雖可度量 retriever 性能 , 卻無法體現這些信息是否真的被模型「用好」 。 這些偏差直接導致現有 RL Agentic RAG 方法在評估、訓練和泛化上均存在瓶頸 。
s3 - 專注搜索效果優化的 search agent RL 訓練框架
s3 的出發點很簡單:
如果我們真正關心的是「搜索提升了生成效果」 , 那就應該只訓練搜索器、凍結生成器 , 并以生成結果提升為獎勵 。
這便是「Gain Beyond RAG(GBR)」的定義:
即:用 s3 搜索到的上下文喂給 Frozen Generator 之后的生成效果 , 相比初始的 top-k 檢索結果是否更好 。 值得注意的是 , s3 訓練時始終初始化于相同的原始 query , 從而能清晰對比 s3 檢索對結果帶來的真實「增益」 。
準確率(Acc)評估標準
我們采用了更語義友好的 Generation Accuracy(GenAcc)指標 。 它結合了兩種機制:
- Span Match:判斷生成答案是否包含參考答案的任意 token span
- LLM Judge:由一個輕量 LLM 判斷答案是否語義正確
訓練與優化 - 僅需 2.4k 樣本即可完成 ppo 訓練:
我們采用 PPO 進行策略優化 。 為了提升訓練效率:
- 我們預篩除掉了「naive RAG 就能答對」的樣本;
- 將訓練樣本集中在需要真正檢索的新信息的任務上;
- Generator 完全凍結 , 訓練代價完全集中在 Searcher 。
s3 訓練總時間只需 114 分鐘(vs Search-R1 的 3780 分鐘) , 數據也減少約 70 倍 。
實驗分析
General QA w/ RAG
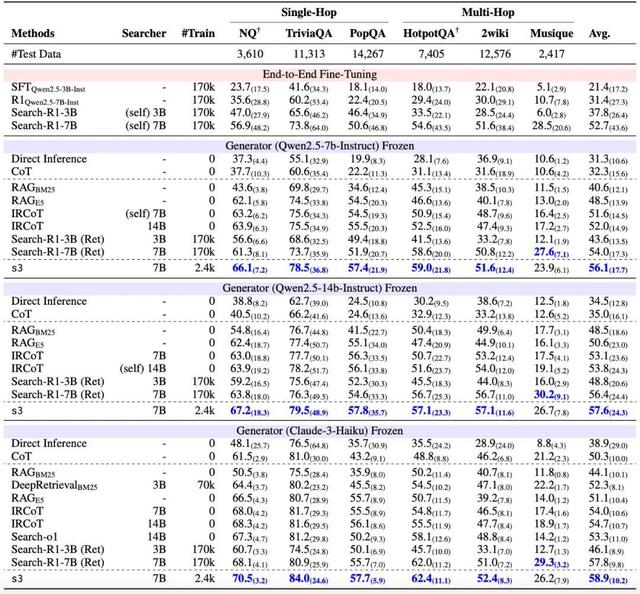
實驗一:通用 QA 任務 , s3 優于 Search-R1 和 DeepRetrieval 。
我們在六個通用數據集上評估了 Direct Inference、Naive RAG、IRCoT、DeepRetrieval、Search-o1、Search-R1 以及 s3 的性能 。 實驗中 , 我們使用了不同的下游 LLM , 包括 Qwen2.5-7B-Instruct , Qwen2.5-14B-Instruct 和 Claude-3-Haiku 。
盡管 s3 僅使用了 2.4k 條 NQ+HotpotQA 訓練數據(training source 和 Search-R1 一樣) , 它在其中五個數據集上實現了最優表現 , 展現出顯著的泛化能力 。
Medical QA w/ RAG
實驗二:醫學 QA 任務 , s3 展現驚人的跨領域能力
我們隨后在五個醫學領域的 QA 數據集上進一步評估了模型性能 , 測試使用了兩個語料庫:Wikipedia2018(與通用測試一致)和 MedCorp(ACL 2024) 。 結果顯示 , Search-R1 在其訓練語料上表現良好 , 但在語料變更后顯現出過擬合趨勢;相比之下 , s3 能穩定遷移至不同的數據集與語料庫 , 凸顯出其基于 searcher-only 優化策略的強泛化能力 。
reward 優化曲線
圖 5 展示了我們的 reward 曲線 , 可以看出 s3 在接近 10 個訓練步驟(batch size 為 120)內便迅速「收斂」 。 這一現象支持兩個推斷:(1)預訓練語言模型本身已具備一定的搜索能力 , 我們只需通過合理的方式「激活」這種能力;(2)在一定范圍內 , 適當增加每輪搜索的文檔數量和最大輪次數 , 有助于提升最終性能 。
消融實驗
在不同配置下 , 移除組件對性能的影響(平均準確率) 。 我們使用了三組設定進行對比 , 結果表明 s3 的設計在準確性與效率之間達到了最優平衡 。
我們進一步通過消融實驗 , 驗證了 s3 框架中兩個關鍵設計的必要性:
- 「從原始問題開始檢索」是方向正確的保障:我們發現 , 以用戶原始問題作為第一輪檢索的起點 , 有助于模型明確搜索目標、建立有效的檢索路徑 。 若不設置這一初始點 , 搜索策略往往偏離主題 , 導致性能顯著下降 。
- 「文檔選擇」機制顯著降低 token 消耗:該機制允許模型在每輪檢索后主動篩選信息 , 從而避免將所有檢索結果一股腦送入生成器 。 通過這一設計 , s3 的輸入 token 平均減少了 2.6 至 4.2 倍 , 不僅提升了效率 , 也減少了噪聲干擾 , 對生成效果有正面作用 。
FAQ
Q1:為什么我們報告的 Search-R1 結果與原論文不一致?
A1:Search-R1 原文使用 Exact Match(EM)作為 reward 和評估指標 , 并對模型進行了針對性微調 。 將這種針對 EM 優化的模型 , 與其他 zero-shot 方法比較 , 略顯不公平 , 也難以衡量搜索本身的效果 。 因此我們采用更語義友好的 Generation Accuracy(GenAcc) , 結合 span 匹配和 LLM 判斷 , 與人類評估一致率達 96.4% 。 相比之下 , EM 只能捕捉字面一致 , 反而容易誤導模型優化方向 。
Q2:s3 為什么不訓練生成器?這樣是否限制了模型性能?
A2:我們設計 s3 的核心理念是:如果我們想真正優化搜索效果 , 不應讓生成器被訓練 , 否則會混淆「搜索變好」與「語言模型變強」帶來的增益 。 凍結生成器不僅提升了訓練效率(節省大模型微調成本) , 也便于模型遷移到不同任務與生成器 , 真正做到「搜索能力即插即用」 。
推薦閱讀











- 亮度不打折,體驗不縮水:哈趣H3是如何重新定義百元真投影的?
- 馬克龍:法國必須掌握2至10納米先進制程半導體制造能力
- 不同價位段的智能手機,電池安全性有差異嗎
- 多智能體在「燃燒」Token!Anthropic公開發現的一切
- 性能、質感全面升級 富士X-E5上手體驗
- 華為智能穿戴十年,一場智能手表的健康革命
- PConline攜手微星校園行 | 龍魂燃動北京體育大學
- 小米首款真AI智能眼鏡來了:雙芯架構、自帶鏡頭
- 連尚集團推出專為銀齡群體打造的社交分享工具“好靈AI”
- 蔡司超級潛望長焦+天璣9400+,vivoX200s值得體驗!