
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
智東西6月21日消息 , 6月18日 , 前OpenAI聯合創始人、深度學習專家安德烈·卡帕西(Andrej Karpathy)在Y Combinator(YC)于美國舊金山Moscone會議中心舉辦的AI創業學院(AI Startup School)活動上 , 以《軟件正在發生根本變化》(Software Is Changing (Again))為題發表40分鐘主題演講 , 系統闡釋了大語言模型是如何將軟件開發從“寫代碼/調參數”轉向“自然語言指揮AI” 。
卡帕西在演講中透露 , 軟件開發已進入“Software 3.0”階段 。 他提出 , 傳統的手寫代碼時代 , 即Software 1.0 , 以及訓練神經網絡權重的Software 2.0時代 , 正被“提示詞即程序”的Software 3.0所取代 。 自然語言正成為直接控制計算機的新編程接口 。
同時 , 卡帕西定義了大語言模型的三重核心屬性:大語言模型兼具類似電網的基礎設施服務屬性、類似芯片晶圓廠的百億級資本密集投入屬性 , 以及類似操作系統的復雜生態構建與分層管理屬性 。
當提到大語言模型存在的認知缺陷時 , 卡帕西說大語言模型主要有兩大關鍵認知缺陷:一是“鋸齒狀智能”(Jagged Intelligence) , 表現為處理復雜任務能力突出 , 卻在如數值比較、拼寫的基礎邏輯上頻繁出錯;二是信息一旦超出設定的上下文窗口便無法被保留 。
針對大語言模型的自主性控制挑戰 , 卡帕西提出了仿鋼鐵俠戰甲的動態控制框架 。 這個框架的核心是通過自主性調節器 , 實現類似特斯拉Autopilot的L1-L4分級決策權限分配 。
就像鋼鐵俠的戰衣一樣 , 人們可以根據任務的復雜性和風險程度 , 動態調整AI的自主程度 , 從簡單的輔助建議到完全自主決策 , 讓人類始終保持對系統的最終控制權 。
以下是卡帕西所發表演講的完整編譯(為提高可讀性 , 智東西在不違背原意的前提下進行了一定的增刪修改):
01 軟件進化路徑:從寫代碼、教電腦 , 到“說話”指揮AI今天我很興奮能在這里和大家聊AI時代的軟件 。 我聽說你們很多人是學生 , 本科生、碩士生、博士生等等 , 即將進入這個行業 。 現在進入行業其實是一個極其獨特、非常有趣的時刻 。
根本原因在于軟件正經歷根本性變革 。 我說“再次” , 是因為它持續劇變 , 這讓我總有新材料創作新演講 。
粗略地說 , 我認為軟件在根本層面上70年沒大變 , 但最近幾年快速變化了兩次 。 這帶來了海量的軟件編寫和重寫工作 。 我幾年前觀察到軟件在變化 , 出現了一種新型軟件 , 我稱之為Software 2.0 。
我的想法是:Software 1.0是你編寫的計算機代碼;Software 2.0本質上是神經網絡的權重 。 你不是直接編寫它 , 而是通過調整數據集和運行優化器來創建這些參數 。
當時神經網絡常被視為另一種分類器 , 但我認為這個框架更貼切;現在 , 我們在Software 2.0領域有了類似GitHub的存在 , 我認為Hugging Face是Software 2.0領域的GitHub , 其推出的Model Atlas也在其中扮演著重要角色 。
作為一個極具影響力的平臺 , Hugging Face為開發者提供了豐富的資源與便捷的工具 , 就像GitHub在傳統軟件開發中所做的那樣 , 它推動著Software 2.0領域的技術交流與創新發展 , 而模型地圖(Model Atlas)如同一個龐大的模型資源庫 , 進一步豐富了平臺的生態 , 讓開發者能夠更輕松地獲取和使用各類模型 , 助力不同項目的開發與落地 。 模型地圖是一種可視化模型倉庫的開源工具 , 針對Software 2.0設計 。
例如 , 那個巨大的中心圓圈代表Flux圖像生成器的參數 , 每次在其基礎上調整 , 就相當于一次git commit , 創建一個新的圖像生成器 。
所以 , Software 1.0通過編寫代碼對計算機進行編程 , Software 2.0則借助如AlexNet等神經網絡的權重實現對神經網絡的編程 。
直到最近 , 這些神經網絡都是固定功能的 。 我認為一個根本性的變化是:神經網絡通過大語言模型變得可編程了 。 我認為這非常新穎獨特 , 是一種新型計算機 , 值得稱為Software 3.0 。
在Software 3.0中 , 你的提示詞就是編程大語言模型的程序 。 值得注意的是 , 這些提示是用英語寫的 , 這是一種非常有趣的編程語言 。
比如你想讓電腦進行一下情感分類 , 完成判斷一條評論是夸人還是罵人的任務 , 有不同的方法 。
Software 1.0的老方法:你得像個老師傅 , 自己動手寫一堆代碼 , 告訴電腦看到哪些詞算夸、哪些詞算罵;進化一點的Software 2.0:你像個教練 , 找一堆標好了“夸”或“罵”的評論例子 , 讓電腦自己琢磨學習規律;Software 3.0:你像個老板 , 直接對大語言模型下命令:“看看這條評論是夸還是罵?只準回‘夸’或‘罵’!”就這一句話 , AI就懂了 , 馬上給你答案 。 你要是把命令改成“分析下這條評論是積極還是消極” , 它回答的方式也跟著變 。
我們看到GitHub上的代碼不再僅是代碼 , 還夾雜著英語 , 這是一種正在增長的新代碼類別 。 這不僅是一個新范式 , 同樣令我驚訝的是它使用英語 。 這讓我幾年前震驚并發布了推文 。
我在特斯拉研發Autopilot時觀察到:起初棧底是傳感器輸入 , 經過大量C++(1.0)和神經網絡(2.0)處理 , 輸出駕駛指令 。 隨著Autopilot改進 , 神經網絡能力和規模增長 , C++代碼被刪除 。 許多原本由1.0實現的功能遷移到了2.0 。 Software 2.0棧實實在在地“吃掉”了1.0棧 。
在特斯拉研發Autopilot時觀察到的2.0吞噬傳統代碼棧
我們正再次看到同樣的事情發生:Software 3.0正在“吃掉”整個棧 。 現在我們有了三種完全不同的編程范式 。 我認為進入行業時精通三者是明智的 , 它們各有優劣 。 你需要決定:某個功能該用1.0、2.0還是3.0實現?是訓練神經網絡還是提示大語言模型?這該是顯式代碼嗎?我們需要做這些決定 , 并可能需要在范式間流暢轉換 。
02 大語言模型成為新操作系統 , 計算呈分時共享模式軟件正在經歷根本性的變化 , 這種變化在過去70年中從未如此劇烈 。 大約70年來 , 軟件的底層范式幾乎未變 , 但在過去幾年里 , 它連續發生了兩次結構性巨變 。 現在 , 我們正站在軟件重寫的浪潮上 , 有大量的工作要做、大量的軟件要寫 , 甚至重寫 。
幾年前 , 我注意到軟件開始向一種新形式演化 , 我當時給它取名叫Software 2.0 。 Software 1.0是傳統意義上我們手寫的代碼 , 而Software 2.0指的是神經網絡的參數 。 我們不再直接寫“代碼” , 而是調數據、跑優化器 , 生成參數 。
如今 , 在Software 2.0世界中也有了類似GitHub的東西 , 比如Hugging Face和模型地圖 , 它們就像代碼庫一樣存儲著不同的模型 。 每次有人在Flux模型基礎上進行調整 , 就相當于在這個空間創建了一次代碼提交 。
而現在 , 大語言模型的出現帶來了更根本的改變 。 我認為這是一種全新的計算機 , 甚至值得被稱為Software 3.0 。 你的提示現在就是對大語言模型編程的程序 , 而且這些提示是用英語編寫的 。 這是一種非常有趣的編程語言 。
Andrew Ng曾說“AI是新時代的電力” , 這句話點出了關鍵點 , 比如OpenAI、谷歌、Anthropic等投入資本來訓練模型 , 然后用運營開銷通過API向開發者“輸送智能” , 模型按token計價 , 像電力一樣被“計量使用” 。 我們對這些模型的要求也非常像“基礎設施”:低延遲、高可用、穩定輸出 。
如OpenAI、Gemini、Anthropic投入資本訓練模型 , 類似構建電網
但大語言模型不僅具有公用事業的屬性 , 它們更像是復雜的軟件操作系統 。 OpenAI、Anthropic就像是Windows和macOS , 而開源模型則更像Linux 。 操作系統的作用不是“運行某個功能” , 而是構建一個“平臺”來承載更多功能 。
閉源供應商如Windows、Mac OS有開源替代方案Linux
更準確地說 , 大語言模型并非獨立完成任務 , 而是作為承載提示詞、工具及Agent等組件的“運行時系統”來發揮作用 。 這些組件如同插件般嵌入大語言模型框架中 , 通過模型的推理能力協調運作 , 共同實現復雜任務的處理 。
從計算模式來看 , 我們現在的大語言模型計算處于1960年代的階段 。 大語言模型推理成本仍然很高 , 模型計算集中部署在云端 , 我們如同瘦客戶端(Thin Client)通過網絡遠程訪問 。
這就像“分時共享”計算模式:多用戶排隊使用同一模型 , 云端以“批處理”方式依次執行任務 , 就像多人輪流使用一臺超級計算機 , 按序獲取計算資源 。
有趣的是 , 大語言模型顛倒了傳統技術擴散的方向 。 通常 , 新技術首先由政府和企業使用 , 之后才擴散到消費者 。 但大語言模型不同 , 它首先服務的是普通人 , 比如幫助用戶煮雞蛋 , 而政府和企業反而在落后地采用這些技術 。
大語言模型幫助用戶煮雞蛋
這完全顛倒了傳統路徑 , 也可能啟示我們:真正的殺手級應用會從個人用戶端長出來 。
總結來看 , 大語言模型本質上是復雜的軟件操作系統 , 我們正在“重新發明計算” , 就像1960年代那樣 。 而且它們現在以“時間共享”的方式提供服務 , 像公用事業一樣被分發 。
真正不同的是 , 它們不是掌握在政府或少數企業手里 , 而是屬于我們每一個人 。 我們每個人都有電腦 , 而大語言模型只是軟件 , 它可以在一夜之間傳遍整個星球 , 進入數十億人的設備 。
現在 , 輪到我們進入這個行業 , 去編程這個“新計算機” 。 這是一個充滿機遇的時代 , 我們需要熟練掌握Software 1.0、2.0和3.0這三種編程范式 , 在不同場景下靈活運用 , 以發揮它們的最大價值 。
03 擁有超強記憶 , 卻存在“記憶碎片”式健忘癥與認知錯誤研究大語言模型時 , 我們得花些時間思考它們究竟是什么 。 我尤其想聊聊它們的“心理” 。 在我看來 , 大語言模型有點像人的靈魂 , 是對人類的靜態模擬 。 這里的模擬工具是自回歸變換器 , 變換器本質上是一種神經網絡 , 它以token為單位 , 一個token接一個token地處理信息 , 處理每個token所耗費的計算量幾乎相同 。
當然 , 這個模擬過程涉及一些參數權重 , 我們根據互聯網上的所有文本數據對其進行擬合 , 最終得到這樣一個模擬工具 。 它是基于人類文本數據訓練的 , 因此產生了類似人類的“心理”特征 。
首先 , 我們會注意到 , 大語言模型擁有百科全書式的知識和超強的記憶力 。 它們能記住的內容比任何一個普通人都要多得多 , 因為它們“閱讀”了海量信息 。 這讓我想起電影《雨人》 , 強烈推薦大家去看看 , 這是一部很棒的電影 。
達斯汀·霍夫曼在影片中飾演一位患有自閉癥的天才 , 擁有近乎完美的記憶力 , 他可以讀完一本電話簿 , 并記住所有的姓名和電話號碼 。 我覺得大語言模型和他很相似 , 它們能輕松記住哈希值等各種各樣的信息 , 在某些方面確實擁有“超能力” 。
不過 , 大語言也存在一些認知缺陷 。 它們經常會產生幻覺 , 編造一些內容 , 而且缺乏足夠完善的自我認知內部模型 。 雖然這方面已經有所改善 , 但仍不完美 。
它們的智能表現參差不齊 , 在某些問題解決領域展現出超人的能力 , 但也會犯一些人類幾乎不會犯的錯誤 , 比如堅稱9.11大于9.9 , 或者認為“strawberry”里有兩個“r” , 這些都是很有名的例子 。 總之 , 它們存在一些容易讓人“踩坑”的認知盲區 。
此外 , 大語言模型還存在遺忘問題 。 打個比方 , 如果有新同事加入公司 , 隨著時間推移 , 這位同事會逐漸了解公司 , 掌握大量公司相關背景信息 , 晚上回家休息時鞏固知識 , 久而久之積累專業知識 。
但大語言模型天生不具備這種能力 , 在大語言模型的研發中 , 這一問題也尚未得到真正解決 。 上下文窗口就好比工作記憶 , 我們必須非常直接地對其進行編程設定 , 因為大語言模型不會默認自動變得更智能 。
我認為很多人會被流行文化中的一些類比誤導 , 我建議大家看看《記憶碎片》和《初戀50次》這兩部電影 。 在這兩部電影中 , 主角的記憶權重是固定的 , 每天早上上下文窗口都會被清空 。 在這種情況下 , 去工作或者維持人際關系都變得非常困難 , 而這恰恰是大語言模型經常面臨的情況 。
我還想指出一點 , 就是使用大語言模型時在安全方面的相關限制 。 例如 , 大語言模型很容易被欺騙 , 容易受到提示注入風險的影響 , 可能會泄露你的數據等等 , 在安全方面還有許多其他需要考慮的因素 。
簡而言之 , 大語言模型既是擁有超能力的“超人” , 又存在一系列認知缺陷和問題 。 那么 , 我們該如何對它們進行編程 , 如何規避它們的缺陷 , 同時又能充分利用它們的超能力呢?
04 最大機遇是做帶自主調節功能的半自動化應用 , 有好用的界面和操作體驗現在 , 我想轉而談談如何利用這些模型 , 以及其中最大的機遇是什么 。 我最感興趣的是“部分自主化應用”這一方向 。 以編程場景為例 , 你可以直接使用ChatGPT復制粘貼代碼、提交bug報告 , 但為什么要直接與操作系統交互呢?更合理的方式是構建專用應用 。
我和在座很多人一樣在用Cursor , 它是早期大語言模型應用的典范 , 具備幾個關鍵特性:保留傳統手動操作界面的同時集成大語言模型處理大塊任務;大語言模型負責大量上下文管理;編排多輪模型調用 , Cursor底層實際上整合了代碼嵌入模型、聊天模型以及用于代碼差異應用的模型 。
專用GUI的重要性常被低估 。 文本交互難以閱讀和操作 , 而可視化diff以紅色標識刪除、綠色標識新增 , 配合Command+Y/N快捷鍵能大幅提升審查效率;還有“自主滑塊”設計 , 比如Cursor中從代碼補全到修改整個文件甚至整個代碼庫的不同自主層級 , 用戶可根據任務復雜度調整放權程度 。
【說話就能編程的時代來了,AI大神卡帕西40分鐘演講精華】另一個成功案例是Perplexity , 它同樣整合多模型調用、提供可審計的GUI , 用戶能點擊查看引用來源 , 也設有自主滑塊 , 提供快速搜索、深度研究等不同模式 。
我認為未來大量軟件將走向部分自主化 , 這需要思考幾個核心問題:大語言模型能否感知人類所見、執行人類所行?人類如何有效監督這些尚不完美的系統?傳統軟件的交互設計如何適配大語言模型?
當前大語言模型應用的關鍵在于優化“生成-驗證”循環效率 。 一方面 , GUI利用人類視覺系統快速審查結果 , 讀文本費力而看圖輕松;另一方面 , 必須控制AI的“自主性”:10000行代碼的diff對開發者毫無意義 , 人類仍是質量瓶頸 。 我在實際編程中始終堅持小步迭代 , 避免過大變更 , 通過快速驗證確保質量 。
教育領域的應用設計也遵循類似邏輯:教師端應用生成課程 , 學生端應用提供結構化學習路徑 , 中間課程作為可審計的中間產物 , 確保AI在既定教學大綱和項目流程內工作 , 避免“迷失” 。
回顧在特斯拉的經歷 , 自動駕駛系統同樣采用部分自主模式:儀表盤實時顯示神經網絡感知結果 , 用戶通過“自主滑塊”逐步放權 。 2013年我首次體驗完全無干預的自動駕駛時 , 曾認為技術已成熟 。
當時朋友在Waymo工作 , 帶我在帕洛阿爾托的高速和街道上行駛了30分鐘 , 全程零干預 , 我用谷歌眼鏡記錄下了這一幕 。 但12年后的今天 , 即便能看到Waymo的無人駕駛車輛上路 , 背后仍依賴大量遠程操作和人工介入 。 這說明軟件系統的復雜性遠超預期 , AI Agent的發展將是長期過程 , 需保持謹慎 。
同樣地 , 類比鋼鐵俠戰衣可知:當前更應聚焦“增強型工具” , 而非“全自主機器人” 。
構建部分自主產品時 , 需做好兩點:一是設計定制化GUI與UX(用戶體驗) , 確保“生成-驗證”循環高效運轉;二是保留自主滑塊機制 , 以便逐步提升產品自主性 。 這正是我眼中的重要機會方向 。
05 自然語言編程讓人人能開發 , 加快Agent基礎設施轉型我認為大語言模型用英語編程這件事 , 讓軟件變得極具可訪問性!同時我想補充另一個獨特維度:如今不僅出現了允許軟件自主運行的新型編程語言 , 而且它以英語這種自然界面編程 。
突然之間 , 每個人都能成為程序員 , 因為人人都會說英語這樣的自然語言 , 這讓我感到非常振奮 , 也覺得前所未有的有趣 。 過去 , 你需要花5到10年學習才能在軟件領域有所作為 , 但現在完全不同了 。
不知道大家有沒有聽說過“Vibe Coding”(基于自然語言交互的編程方式)?這個概念最初由一條推文引入 , 現在已經成了一個熱門梗 。
說起來有趣 , 我在Twitter上待了15年左右 , 至今仍搞不懂哪條推文會爆火 , 哪條會無人問津 。 當時我發那條推文時 , 以為它會石沉大海 , 畢竟那只是我洗澡時的隨想 , 結果它成了全網梗 , 甚至有了維基百科頁面 , 這算是我對行業的一大貢獻吧 。
HuggingFace的Tom Wolf分享過一個很棒的視頻 , 里面是孩子們在“Vibe Coding” 。 我特別喜歡這個視頻 , 它太治愈了 , 看了這樣的畫面 , 誰還會對未來感到悲觀呢?我覺得這會成為軟件開發的“入門藥” 。 我對這代人的未來并不悲觀 , 真的很愛這個視頻 。 受此啟發 , 我也嘗試了“Vibe Coding” , 因為它太有趣了 。
比如當你想做一個特別定制化、市面上不存在的東西 , 又恰逢周六想隨性發揮時 , 這種編程方式就很合適 。 我曾用它開發了一個iOS應用 , 雖然我完全不會Swift , 但居然能做出一個超基礎的應用 , 過程很簡單 , 我就不細說了 , 但那天花了一天時間 , 晚上應用就在我手機上運行了 , 我當時真的覺得“太神奇了” , 不用花五天時間啃Swift教程就能上手 。
我還“Vibe Coding”了一個叫Menu Genen的應用 , 現在已經上線 , 大家可以在menu.app試用 。 我開發它的初衷很簡單:每次去餐廳看菜單 , 我都不知道那些菜是什么 , 需要配圖 , 但市面上沒有這樣的工具 , 于是我就“Vibe Coding”了一個 。 用戶注冊后能獲得5美元credits , 但這對我來說是個巨大的成本中心 。
現在這個應用還在虧錢 , 我已經搭進去很多錢了 。 不過有趣的是 , 開發Menu Genen時 , “Vibe Coding”的代碼部分其實是最簡單的 , 真正難的是把它落地成可用的產品:認證系統、支付功能、域名注冊和部署 , 這些都不是寫代碼 , 而是在瀏覽器里點點點的DevOps工作 , 極其繁瑣 , 花了我一周時間 。
比如給網頁添加谷歌登錄時 , 文檔里全是“去這個URL , 點擊下拉菜單 , 選擇這個 , 再點那個”之類的指令 , 簡直像電腦在指揮我做事 , 為什么不是它自己做呢?這太瘋狂了 。
所以我演講的最后一部分想探討:我們能否為Agent構建基礎設施?大語言模型正在成為數字信息的新型主要消費者和操控者 , 我不想再做那些繁瑣的手動工作了 , 能不能讓Agent來做?
概括來說 , 數字信息的消費者和操控者范疇正在擴展:過去只有通過GUI交互的人類 , 或通過API交互的計算機 , 現在多了Agent , 它們是像人類一樣的計算機 , 是互聯網上的“數字精靈” , 需要與我們的軟件基礎設施交互 。
比如 , 我們可以在域名下創建lm.txt文件 , 用簡單的Markdown告訴大語言模型這個域名的內容 , 這比讓它們解析HTML更高效 , 因為HTML解析容易出錯 。 現在很多文檔還是為人類編寫的 , 有列表、粗體、圖片 , 但大語言模型難以直接理解 。
我注意到Vercel和Stripe等公司已經開始將文檔轉為大語言模型友好的Markdown格式 , 這是很好的嘗試 。
舉個例子 , 由斯坦福大學數學系畢業生格蘭特·桑德森(Grant Sanderson)創建的YouTube頻道3Blue1Brown的動畫視頻文檔寫得很棒 , 我不想通讀 , 就把文檔復制給大語言模型 , 告訴它我的需求 , 結果它直接幫我生成了想要的動畫 。
如果文檔能讓大語言模型讀懂 , 會釋放巨大的應用潛力 。 但這不僅是轉換格式的問題 , 比如文檔里的“點擊此處”對大語言模型毫無意義 , Vercel就把所有“點擊”替換成了大語言模型Agent可用的curl命令 。
此外 , Anthropic的模型上下文協議MCP(model context protocol)也是直接與Agent交互的新方式 , 我很看好這些方向 。
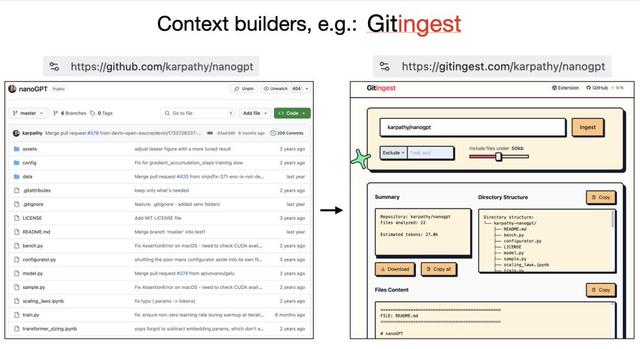
還有一些工具也在助力大語言模型友好的數據處理:比如把GitHub倉庫的URL改成get.ingest , 就能將所有文件合并成可直接喂給大語言模型的文本;Deep Wiki不僅提取文件內容 , 還能分析GitHub倉庫并生成文檔 , 方便大語言模型理解 。 這些工具只需修改URL就能讓內容適配大語言模型 , 非常實用 。
雖然未來大語言模型可能具備點擊操作的能力 , 但現在讓它們更便捷地獲取信息仍有必要 , 畢竟當前大語言模型調用成本較高 , 且操作復雜 , 很多軟件可能不會主動適配 , 所以這些工具很有存在價值 。
總結來看 , 現在進入這個行業正是時候:我們需要重寫大量代碼 , 未來專業開發者和大語言模型都會成為代碼的生產者 。 大語言模型就像早期的操作系統 , 這些“會犯錯的數字精靈”需要我們調整基礎設施來適配 。
今天我分享了高效使用大語言模型的方法、相關工具 , 以及如何快速迭代產品 。 回到“鋼鐵俠戰衣”的比喻 , 未來十年 , 我們會見證人機協作的邊界不斷拓展 , 我已經迫不及待想和大家一起參與其中 。
推薦閱讀















- 為什么一個彈幕,就能讓主播喵一百聲?
- 華為HarmonyOS 6來了,還有自研編程語言丨兩分鐘發布會
- 同一天開源新模型,一推理一編程,MiniMax和月之暗面開卷了
- 看一下就能買單 全球首個智能眼鏡支付來了
- 20瓦就能運行下一代AI?科學家瞄上了神經形態計算
- 讓用戶在Mac上玩3A游戲,不如直接就能運行手游
- 618就要結束了 這幾款熱門手機僅2000元出頭就能拿下
- 愛立信破解運營商“管道化”困局:可編程網絡與AI雙輪驅動
- 三星電子計劃下月引入AI編程助手 以提高軟件開發效率
- Cursor 1.0來襲!自動捉bug,秒改屎山代碼,AI編程分水嶺已至