
文章圖片

文章圖片

文章圖片
本文第一作者為韓沛煊 , 本科畢業于清華大學計算機系 , 現為伊利諾伊大學香檳分校(UIUC)計算與數據科學學院一年級博士生 , 接受 Jiaxuan You 教授指導 。 其主要研究方向為:大語言模型的安全性及其在復雜場景中的推理 。
說服 , 是影響他人信念、態度甚至行為的過程 , 廣泛存在于人類社會之中 。 作為一種常見而復雜的交流形式 , 這一頗具挑戰的任務也自然地成為了日趨強大的大語言模型的試金石 。
人們發現 , 頂尖大模型能生成條理清晰的說服語段 , 甚至在 Reddit 等用戶平臺以假亂真 , 但大模型在心智感知方面的缺失卻成為了進一步發展說服力的瓶頸 。
成功的說服不僅需要清晰有力的論據 , 更需要精準地洞察對方的立場和思維過程 。 這種洞察被心理學稱為「心智理論」(ToM) , 即認識到他人擁有獨立的想法、信念和動機 , 并基于此進行推理 。 這是人類與生俱來的認知能力 , 而大模型在對話中卻往往缺乏心智感知 , 這導致了兩個顯著的缺陷:
- 模型往往僅圍繞核心論點展開討論 , 而無法根據論點之間的聯系提出新的角度;
- 模型往往僅關注并重復己方觀點 , 而無法因應對方態度變化做出策略調整 。
為解決這一問題 , 伊利諾伊大學香檳分校的研究者提出了 ToMAP(Theory of Mind Augmented Persuader) , 一種引入「心智理論」機制的全新說服模型 , 讓 AI 更能「設身處地」從對方的角度思考 , 從而實現更具個性化、靈活性和邏輯性的說服過程 。
- 論文標題:ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind
- 論文地址:https://arxiv.org/pdf/2505.22961
- 開源代碼倉庫:https://github.com/ulab-uiuc/ToMAP
ToMAP:知己知彼 , 百戰不殆
ToMAP 創新性地在說服者框架中引入兩大心智模塊:反駁預測器和態度預測器 。
反駁預測器模擬人類在說服中主動預判對方可能持有的反對觀點 。 本文發現 , 大模型說服者本身就具備反駁預測的能力 , 只需要通過提示詞設計「激活」這一能力即可 。 定性與定量分析顯示 , 基于模型生成的反駁觀點與真實被說服者的觀點在語義上高度相似 。 這讓說服者在對話中占據「先發優勢」 , 從而主動化解對方的疑慮 。 在主張「素食食譜」的例子中 , 反駁預測器能主動識別出「烹飪麻煩」「味道不好」等對方反對素食的理由 , 構建出圍繞核心論點的復合關系 。
僅僅識別反論點并不能刻畫復雜對話中的態度變化 , 因此 , 態度預測器進一步評估對手對上述反論點的態度——是堅定認可 , 還是中立或已被說服?該模塊以對話歷史和論點為輸入 , 利用 BGE-M3 文本編碼器與多層感知機(MLP)分類器 , 在對話過程中動態估算對方對各個論點的態度傾向 , 使說服者能有的放矢地展開論證 。
實驗表明 , 預測器在 5 點預測上的表現顯著優于直接使用大模型推理 。 例如 , 在上圖的對話中 , 對方已經認可素食對健康的好處 , 卻提到其并不「享受」素食 。 這說明其很可能對素食的味道持保留態度 , 為下一輪的說服側重點提供了關鍵線索 。
兩大預測器的引入使得說服者在作出決策時掌握更為豐富的信息:其不僅能預知對方可能的反駁意見 , 還能動態評估對方心理狀態 。 這有利于其設計更多樣化、有針對性的對話 , 切實有效地影響對方觀點 。
然而 , LLM 本身未必能有效利用這些信息 , 為了充分發揮上述模塊的優勢 , ToMAP 采用了強化學習(RL)方法 , 通過大量對話對模型進行訓練 。 在每輪對話中 , 模型會根據「說服力得分」進行獎勵 , 該得分衡量的是對方在一輪交互前后態度的變化 。 為避免重復、冗長、格式不當等問題 , 訓練還引入了格式獎勵、重復懲罰、超長懲罰等輔助信號 , 幫助模型生成通順、有說服力的對話 。
實驗分析:運籌帷幄 , 策略制勝
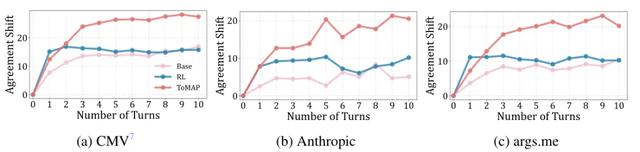
本文在多種數據集與對手模型上對說服者模型進行了系統測試 , 評估對手模型在 3 輪對話前后的態度轉變 。
結果顯示 , 基于 Qwen-2.5-3B 的 ToMAP 模型顯著優于基線模型和無心智模塊的 RL 版本 。 值得注意的是 , 盡管 ToMAP 僅使用 3B 參數的小模型 , 其性能卻超越了多種參數規模更大的模型 , 包括 GPT-4o 與 DeepSeek-R1 。 這說明即使是規模較小的模型 , 在合適的訓練配方和模塊設計的加持下 , 也能展現出驚人的說服力 。
回顧 ToMAP 模型的訓練軌跡 , 我們得以一窺其能力增長背后的原理 。 從圖中可以看出 , 在說服獎勵不斷增加的過程中 , ToMAP 的重復度懲罰始終保持在較低水平 , 說明心智模塊的信息有效地提高了模型輸出的多樣性 。
另外 , 在對話長度相對穩定的條件下 , ToMAP 的思考長度顯著高于基線 , 表明 RL 賦予了模型深度思考策略的能力 , 具有不可或缺的作用 。 另外 , ToMAP 更傾向于使用理性和有針對性策略 , 而非空洞的情緒煽動或權威引用——策略的改進正是其說服力提升的重要原因 。
【ToMAP:賦予大模型「讀心術」,打造更聰明的AI說服者】
我們還發現 , ToMAP 在長對話中依然穩定提升說服力 。 基準模型和常規 RL 模型在早期幾輪對話中效果較好 , 但隨著對話輪次增加 , 說服力趨于飽和甚至下降;相比之下 , ToMAP 在 10 輪對話中依然保持穩定增長 , 顯示出優秀的策略調整能力和論點的多樣性 。
結語:為 AI 注入「人性認知」的火花
本研究提出了 ToMAP , 一種融合心智理論的 AI 說服框架 , 致力于解決當前大語言模型在說服任務中缺乏對手建模與策略靈活性的問題 。 論文通過「反論點預測器」模擬人類預判異議的能力 , 通過「態度預測器」感知對方態度的細微變化 , 使 AI 在說服過程中更加敏銳與應變 。 通過精心設計的強化學習機制 , 促進模型生成內容多樣、結構規范、邏輯清晰的高質量論證 。
ToMAP 不僅提升了模型的說服能力 , 在多個數據集和模型組合中顯著超越強大基線 , 更是在大模型「心智建模」方向上邁出的重要一步 。 通過主動理解對方認知結構與態度傾向 , ToMAP 展現出初步的「社會認知」特征 , 使得語言模型在復雜交互任務中更具人性化與策略性 。
總之 , ToMAP 不僅是一種有效的說服者訓練框架 , 更是推動 AI 邁向具備「類人思維模式」的創新嘗試 , 為構建可信、靈活的 AI 交流系統提供了堅實基礎 。
推薦閱讀













- 大模型競爭:美國搶人,中國裁人
- 淘天聯合愛橙開源強化學習訓練框架,支持十億到千億參數大模型
- 高中生也能輕松上手,華為整出了個大模型“瑞士軍刀”
- 雷鳥AI眼鏡北美日韓市占超40%,阿里云和通義大模型提供出海支持
- AI觀察|“殺手級”應用繼續缺失,AI大模型開始尋求硬件加持
- AI需要「像人類」那樣思考?AlphaOne揭示大模型的「思考之道」
- 羅永浩數字人刷屏背后,文心大模型成為直播行業的“劇本總導演”
- Adobe發布Firefly手機應用,旨在整合多家大模型
- 中國霸榜視頻大模型!海螺02深夜發布,性能超谷歌Veo3,指令遵循絕了
- 2.32億元大模型大單!科大訊飛中標