文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

機器之心報道
編輯:+0、張倩
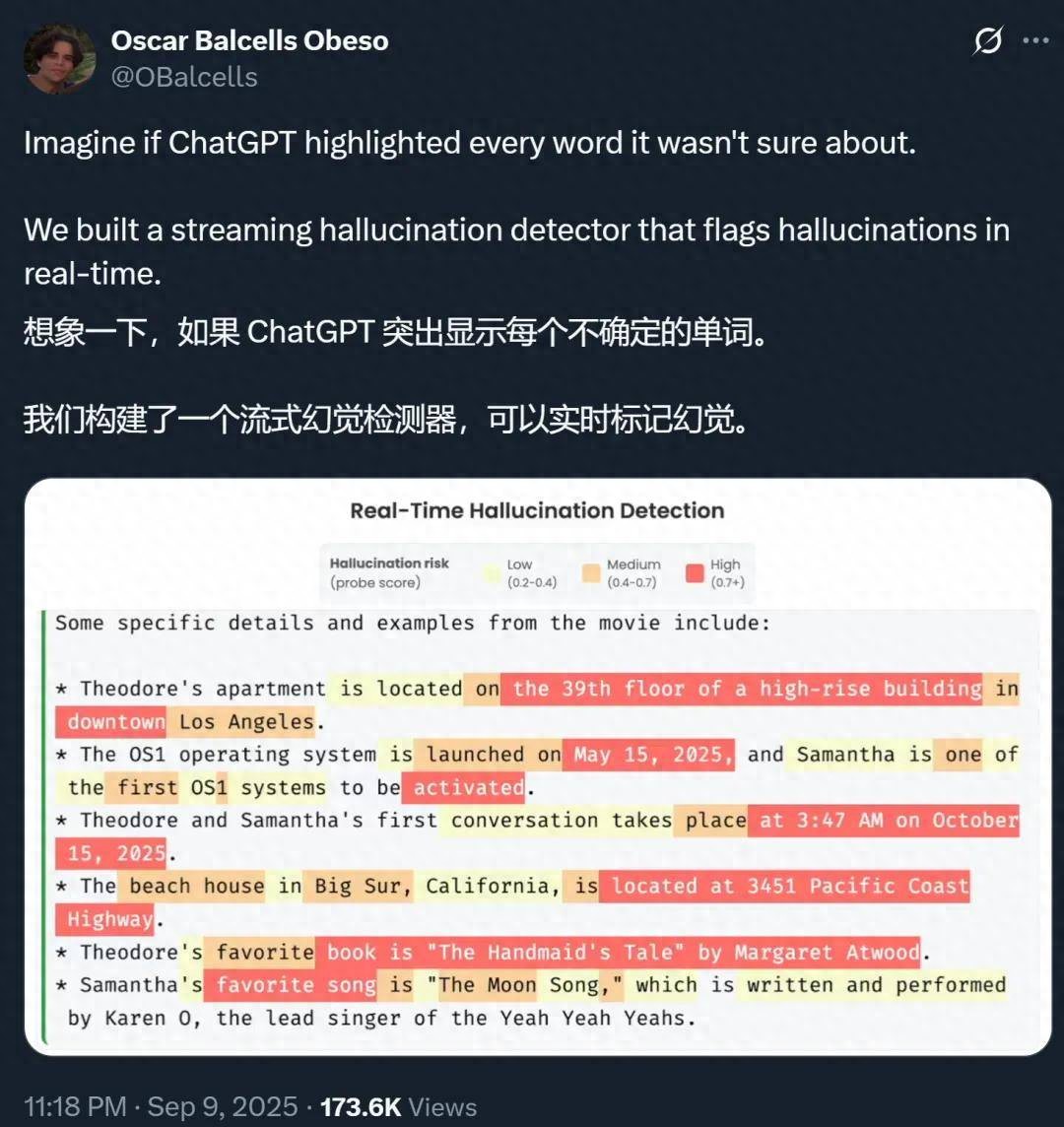
【AI胡說八道這事,終于有人管了?】想象一下 , 如果 ChatGPT 等 AI 大模型在生成的時候 , 能把自己不確定的地方都標記出來 , 你會不會對它們生成的答案放心很多?
上周末 , OpenAI 發的一篇論文引爆了社區 。 這篇論文系統性地揭示了幻覺的根源 , 指出問題出在獎勵上 —— 標準的訓練和評估程序更傾向于對猜測進行獎勵 , 而不是在模型勇于承認不確定時給予獎勵 。 可能就是因為意識到了這個問題 , 并找出了針對性的解法 , GPT-5 的幻覺率大幅降低 。
隨著 AI 大模型在醫療咨詢、法律建議等高風險領域的應用不斷深入 , 幻覺問題會變得越來越棘手 , 因此不少研究者都在往這一方向發力 。 除了像 OpenAI 那樣尋找幻覺原因 , 還有不少人在研究幻覺檢測技術 。 然而 , 現有的幻覺檢測技術在實際應用中面臨瓶頸 , 通常僅適用于簡短的事實性查詢 , 或需要借助昂貴的外部資源進行驗證 。
針對這一挑戰 , 來自蘇黎世聯邦理工學院(ETH)和 MATS 的一項新研究提出了一種低成本、可擴展的檢測方法 , 能夠實時識別長篇內容中的「幻覺 token」 , 并成功應用于高達 700 億(70B)參數的大型模型 。
論文標題:Real-Time Detection of Hallucinated Entities in Long-Form Generation 論文地址:https://arxiv.org/abs/2509.03531 代碼地址:https://github.com/obalcells/hallucination_probes 項目地址:https://www.hallucination-probes.com/ 代碼和數據集:https://github.com/obalcells/hallucination_probes該方法的核心是精準識別實體級幻覺 , 例如捏造的人名、日期或引文 , 而非判斷整個陳述的真偽 。 這種策略使其能夠自然地映射到 token 級別的標簽 , 從而實現實時流式檢測 。
通過 token 級探針檢測幻覺實體 。 在長文本生成場景(Long Fact、HealthBench)中 , 線性探針的性能遠超基于不確定性的基線方法 , 而 LoRA 探針則進一步提升了性能 。 該探針同樣在短文本場景(TriviaQA)以及分布外推理領域(MATH)中表現出色 。 圖中展示的是 Llama-3.3-70B 模型的結果 。
為實現這一目標 , 研究人員開發了一種高效的標注流程 。 他們利用網絡搜索來驗證模型生成內容中的實體 , 并為每一個 token 標注是否有事實依據 。 基于這個專門構建的數據集 , 研究人員通過線性探針(linear probes)等簡潔高效的技術 , 成功訓練出精準的幻覺分類器 。
在對四種主流模型家族的評估中 , 該分類器的表現全面超越了現有基準方法 。 尤其是在處理長篇回復時 , 其效果遠勝于語義熵(semantic entropy)等計算成本更高的方法 。 例如 , 在 Llama-3.3-70B 模型上 , 該方法的 AUC(分類器性能指標)達到了 0.90 , 而基準方法僅為 0.71 。 此外 , 它在短式問答場景中也展現出優越的性能 。
值得注意的是 , 盡管該分類器僅使用實體級標簽進行訓練 , 它卻能有效識別數學推理任務中的錯誤答案 。 這一發現表明 , 該方法具備了超越實體檢測的泛化能力 , 能夠識別更廣泛的邏輯錯誤 。
雖然原始數據集的標注成本高昂 , 但研究發現 , 基于一個模型標注的數據可被復用于訓練針對其他模型的有效分類器 。 因此 , 研究團隊已公開發布此數據集 , 以推動社區的后續研究 。
方法概覽
用于 token 級幻覺檢測的數據集構建
為了訓練能夠在 token 級別檢測幻覺的分類器 , 研究者需要一個對長文本中的幻覺內容有精確標注的數據集 。 這個過程分為兩步:(1) 生成包含事實與幻覺內容的混合文本 ;(2) 對這些文本進行準確的 token 級標注 , 以識別哪些 token 屬于被捏造的實體 。 下圖展示了該標注流程 。
token 級標注流水線 。
數據生成研究者在 LongFact 數據集的基礎上 , 創建了一個規模擴大 10 倍、領域更多樣化的提示集 LongFact++ 。
LongFact++ 包含主題查詢、名人傳記、引文生成和法律案件等四類提示 , 旨在誘導大語言模型生成富含實體的長文本 , 作為后續標注的原材料 。
token 級標注與傳統方法將文本分解為 atomic claims 不同 , 該研究專注于標注實體(如人名、日期、引文等) , 因為實體有明確的 token 邊界 , 易于進行流式檢測 。 他們使用帶有網絡搜索功能的 Claude 4 Sonnet 模型來自動完成標注流程 。
該系統會識別文本中的實體 , 通過網絡搜索驗證其真實性 , 并將其標記為「Supported」(有證據支持)、「Not Supported」(被證實是捏造的)或「Insufficient Information」(信息不足) 。
標簽質量為驗證標注質量 , 研究者進行了兩項檢查 。 首先 , 人類標注員的標注結果與大模型自動標注結果的一致性為 84% 。 其次 , 在一個包含已知錯誤(人工注入)的受控數據集中 , 該標注流程的召回率為 80.6% , 假陽性率為 15.8%。
訓練 token 級探針
實驗結果
在長文本設置中(LongFact 和 HealthBench) , token 級探針在兩個主要模型上的表現都顯著優于基線方法(表 1) 。 簡單的線性探針始終實現了 0.85 以上的 AUC 值 , 而 LoRA 探針進一步提升了性能 , 將 AUC 推高到 0.89 以上 。
相比之下 , 基于不確定性的基線方法表現均不佳 , AUC 值均未超過 0.76 。 在短文本設置中(TriviaQA) , 基線方法比長文本設置中表現更強 , 但探針仍然領先 。 LoRA 探針始終實現了超過 0.96 的 AUC 值 , 線性探針也表現良好 。 值得注意的是 , 本文提出的探針在 MATH 數據集上也取得了強勁的結果 。 這種分布外的性能表明 , 本文提出的方法捕獲了正確性的信號 , 這些信號的泛化性超出了其最初針對的虛構實體 。
作者在三個次要模型上復制了長文本結果 , 每個模型僅使用 2000 個其自身長文本生成的注釋樣本進行訓練 。 結果是相似的:LoRA 探針再次優于線性探針 , 在 LongFact 生成上的 AUC 值在 0.87-0.90 之間 。 次要模型的完整結果顯示在表 5 中 。
雖然 LoRA 探針的 AUC 值在多個設置中接近或超過 0.9 , 但長文本上的 R@0.1 最高約為 0.7 , 即在 10% 假陽性率下 , 檢測器能夠識別出大約三分之二的幻覺實體 。 這些結果既突出了相對于標準基于不確定性基線方法的實際收益 , 也表明在這類方法能夠廣泛應用于高風險場景之前 , 仍有進一步改進的空間 。
更多細節請參見原論文 。
推薦閱讀












- 魅族22終于定檔!直接公布外觀,官方繼續深表歉意
- 國行版iPhone AI,終于要發
- 1.5cm!新 iPhone 靈動島終于變了
- 0.01%參數定生死!蘋果揭秘LLM「超級權重」,刪掉就會胡說八道
- 終于不再藏著掖著,時隔4年,余承東能公開華為麒麟芯片了
- 8.8英寸+SIM卡,華為新機定價3899元,你們要的通話平板終于來了
- 余承東公布麒麟9020,終于不藏著掖著了
- 麒麟9020+鴻蒙5.1,定價17999元起,華為新機終于硬氣了
- iPhone 17 Pro Max 史詩級更新,終于來了
- 麒麟終于明牌!上一款公開麒麟芯的華為旗艦,還是“萬象雙環”