
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
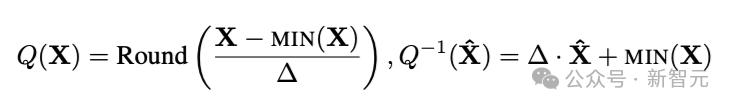
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
編輯:元宇
【新智元導讀】蘋果研究人員發現 , 在大模型中 , 極少量的參數 , 即便只有0.01% , 仍可能包含數十萬權重 , 他們將這一發現稱為「超級權重」 。 超級權重點透了大模型「命門」 , 使大模型走出「煉丹玄學」 。
0.01%參數定生死!
在刪掉極少量參數后 , 大模型立刻變得胡言亂語起來 , 在零樣本任務中只會瞎猜 , 原來的那股聰明勁兒全沒了 。
【0.01%參數定生死!蘋果揭秘LLM「超級權重」,刪掉就會胡說八道】但是 , 如果保留這些極少量參數 , 即使刪掉成千上萬其他參數 , 大模型的智力依然在線 , 幾乎看不出有什么影響 。
如果拿一棵樹比喻 , 剪掉樹(大模型)的幾千片葉子(冗余參數)不會傷筋動骨 , 但只要砍掉樹干上的一個關鍵節點(核心參數) , 整棵樹可能就死掉了 。
這個核心參數 , 就是大模型中存在的極少數關鍵性/高敏感度參數 。
有時甚至只需一個 , 就能對大模型的整體功能產生巨大影響 。
論文地址:https://arxiv.org/abs/2411.07191
近日 , 蘋果研究人員在論文《大語言模型中的超級權重》(The Super Weight in Large Language Models)中 , 將上述現象 , 稱為「超級權重現象」 。
如上圖1左側顯示 , 帶有超級權重的原始Llama-7B , 能順利接著生成合乎邏輯的內容 。
而在圖1右側 , 當超級權重參數被剪枝后 , Llama-7B就開始胡言亂語 , 生成的全是毫無意義的文本 。
這生動詮釋了什么叫「打蛇打七寸」:
剪枝一個「超級權重」的特殊參數 , 就可以完全破壞大模型的能力 。
讓大模型「科學瘦身」
「超級權重」的發現 , 為大模型在端側部署 , 掃清了道路 。
在實際應用中 , 大模型龐大的體格(動輒數十億甚至數千億參數) , 想要部署在移動端等一些低預算、資源受限等環境中 , 就像把大象塞進冰箱 , 往往會面臨巨大挑戰 。
如果只是簡單粗暴的等比壓縮或簡化 , 就好比削足適履 , 只會導致模型質量顯著下降 。
更為合理的做法 , 是讓大模型「科學瘦身」 , 比如縮小模型的規模和計算復雜度 , 從而降低內存與功耗 。
這時 , 超級權重就顯得至關重要 。
在模型壓縮和簡化過程中 , 要避免碰到這些數量雖小 , 卻牽一發而動全身的「命門級」參數 , 避免它們被顯著修改(通過壓縮)或被完全移除(剪枝) 。
即使它們的比例可以小到0.01% , 但對于擁有數十億參數的模型 , 仍然意味著有數十萬個單獨權重 。
蘋果研究人員發現 , 如果動了它們 , 就可能破壞LLM生成連貫文本的能力 , 比如讓困惑度上升3個數量級 , 這樣大模型就幾乎「讀不懂」語言了 。
又或者使大模型的零樣本學習準確率降低到「瞎猜」的水平 , 這意味著大模型的智能也幾乎廢掉了 。
如何定位「超級權重」?
許多研究都顯示出:少量最大幅值的異常值對模型質量至關重要 。
對于擁有數十億參數的模型 , 極少量的參數 , 即便是只有0.01% , 仍可能包含數十萬權重 。 蘋果研究人員將稱這個單標量權重為超級權重(super weight) 。
超級權重 , 會放大某個特征 , 產生超級激活 。
超級權重 , 會誘發相應稀有且幅度巨大的激活離群值 , 研究人員將之稱為super activations(超級激活) 。
所謂激活 , 是指模型在前向傳播時 , 每一層神經元的輸出值 。
它們通常是在超級權重之后出現 , 并在隨后的層中以一種恒定的幅度和位置持續存在 , 而不受輸入提示詞的影響 。
比如 , 一旦某個超級權重參與計算 , 它會把輸入信號放大成異常大的數值 , 于是緊接著的層中就出現超級激活 。
并且 , 超級激活與超級權重所在通道一致 。
于是 , 研究人員就提出了一種高效定位超權重的方法:
通過超級激活來定位超級權重:利用檢測向下投影輸入和輸出分布跨層中的尖峰來定位超級權重 。
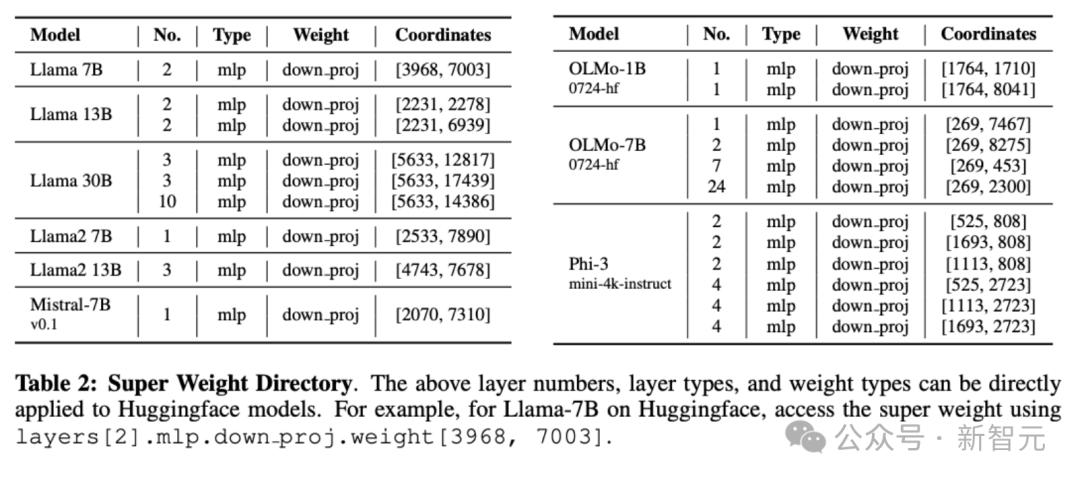
為了促進公開研究 , 研究人員還將一部分常見、公開可用的LLM超級權重標記了出來 , 如下表2:
研究人員發現 , 大多數模型每個張量中的超級權重不超過三個 。
即使超級權重數量最多的模型(例如Phi-3-mini-4k-instruct)也只包含六個 。
研究人員還通過圖2 , 展示了超級權重觸發超級激活 , 以及超級激活的傳播機制 。
圖2-I中藍紫色方框中展示了超級權重的觸發 , 它通常出現在較早層的down projection(降維投影) 。
這好比在一開始就有一個「功放器」 , 把某個信號突然放大到極高的音量 。
圖2-Ⅱ中表示超級激活通過跳躍連接傳播 , 用藍紫色線表示 , 它表示激活不是一次性消失 , 而是層層跳躍傳播下去 。
這好比擴音器的噪音通過音響的電路一路傳到所有揚聲器 , 無論后續放什么音樂 , 那個噪音始終存在 。
圖2-Ⅲ中表示 , 在最終的輸出logits(預測分布)里 , 超級激活會產生壓制停用詞(stopwords)的效果 。
而移除超級權重 , 會導致停用詞可能性增加 , 用藍紫色堆疊條表示 。
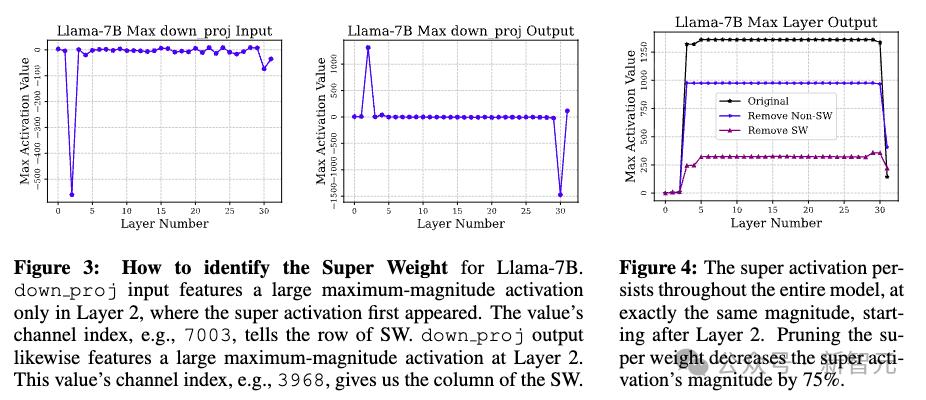
在圖3中 , down_proj輸入在層2中 , 僅有一個大幅度的激活值(super activation) , 這是超級激活首次出現的地方 。
圖4表示 , 一旦在第2層被觸發 , 超級激活會在隨后的所有層中以相同的幅度、相同的位置持續存在 , 而不受輸入的影響 。 如果把超級權重剪掉 , 超級激活的強度會下降75% 。
圖5中顯示了超級權重對停用詞的抑制作用 。
研究人員發現 , 移除超級權重會導致停用詞概率增加2-5倍 , 這在各種LLMs中都存在 。
同時 , 非停用詞的概率急劇下降 , 減少2-3倍 , 低至0.1%的概率 。
整體上看 , 超權重會影響輸出Token的概率分布 。
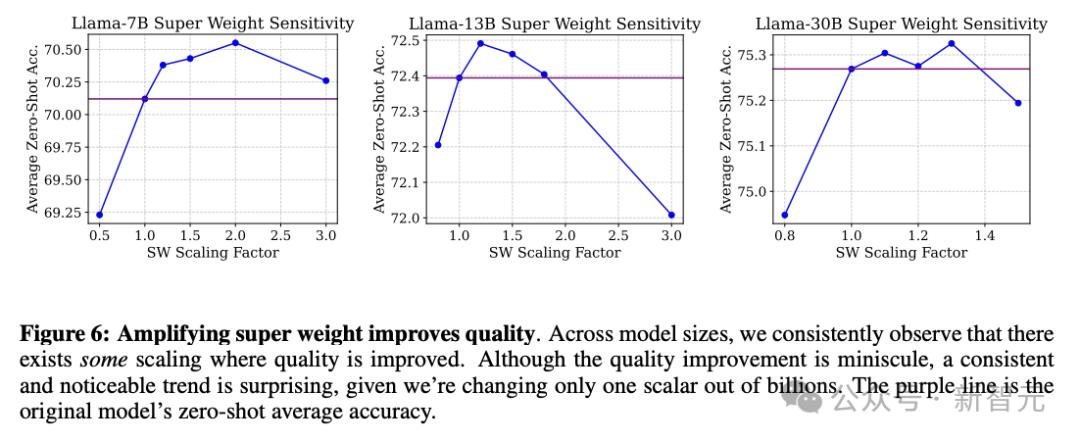
從圖6可以看出 , 增強超權重 , 可以在一定程度上提高模型準確率 。
超級離群值
模型量化的「關鍵鑰匙」
量化是壓縮模型、降低模型內存需求的一種強有力技術 。
其中影響量化質量的 , 是一種重要的指標離群值(outliers) 。 研究人員將超級權重和超級激活統稱為超級離群值 。
超級離群值 , 為人們認識大模型 , 改進大模型壓縮技術 , 提供了一把重要的鑰匙 。
在該項研究中 , 研究人員考慮的是一種最簡單的量化形式——即非對稱的就近取重量化(asymmetric round-to-nearest quantization):
保留超級權重參數 , 是大模型「瘦身」的一個黃金原則 。
研究人員發現 , 只要以高精度保留超級激活 , 通過簡單的就近取整(round-to-nearest)量化 , 也能將模型質量提升到與當前最先進方法相當的水平 。
如表3所示 , 在與FP16、Naive W8A8、SmoothQuant三種模型量化方法的比較中 , 就近取整量化雖然效果略次于SmoothQuant , 但優于Naive W8A8 , 尤其是在不需要校準數據的前提下 , 實用性更強 。
同樣 , 如果在保留超權重的同時 , 對其他權重異常值進行裁剪 , 就近取整量化 , 也可以實現更好的壓縮比 。
這意味著只需處理少量「超級離群值」 , 就能顯著提升壓縮質量 。
研究人員認為 , 與需要處理數十萬離群權重的方法相比 , 這無疑是一種更友好的硬件方案 。
它可以在提升模型效率的同時 , 又能盡可能保留原有性能 。
這也使得強大的LLM應用 , 在資源受限的硬件上部署和高質量運行 , 成為可能 。
激活量化與權重量化
為了全面展示超級權重的影響 , 研究人員將研究范圍擴大到更多大模型:OLMo(1B和7B版本)、Mistral-7B以及Llama-2-7B 。
表4顯示 , 處理超級激活可以提升激活量化效果 。
研究人員遵循SmoothQuant的設置 , 用FP16算術模擬W8A8量化 。
研究結果凸顯了超級激活 , 在量化期間維持模型性能的關鍵重要性 。
研究人員對Llama-7B的分析顯示 , AWQ將超級權重放大了12倍 , 這印證了他們對超級權重重要性的判斷 。
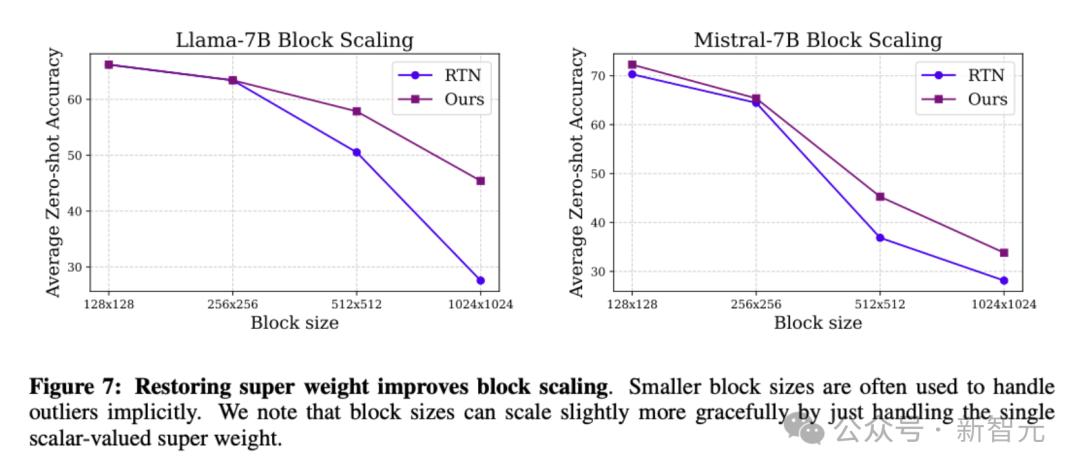
如圖7 , 藍線RTN顯示 , 如果不處理超級權重 , 隨著量化塊變大 , 模型性能急劇下降;紫線Ours表示 , 如果恢復超級權重 , 模型準確率下降更平緩 , 即使大塊量化也能維持較好性能 。
這說明 , 只要針對單個超級權重進行特殊處理 , 就能顯著提高量化的穩定性和可擴展性 。
探索超級離群值的版圖
蘋果研究人員的發現 , 為未來研究打開了多條道路 。
毫無疑問 , 進一步探索超級權重與超級激活的起源及其精確機制 , 將對LLM的運行動態 , 帶來更深入的洞見 。
同樣的 , 理解這些超級權重參數 , 如何在訓練過程中獲得如此「超級」的影響力 , 也可以為未來的模型設計、訓練策略提供更有針對性的指導 。
從另一個角度看 , 在更廣泛的模型架構和訓練范式中 , 展開對超級權重的研究 , 也有助于揭示它們的角色和形成機制 。
這些都將幫助我們解鎖 , 構建更高效、更穩健、更可解釋大模型的創新方法 , 讓大模型告別「煉丹玄學」 。
作者簡介
Mengxia Yu
Mengxia Yu是圣母大學計算機專業博士生 , 此前在北京大學獲得計算語言學學士學位 , 本論文是她在蘋果公司實習期間完成的 。
推薦閱讀










- 剛剛,阿里首個超萬億參數新王登基!Qwen3-Max屠榜全SOTA
- 7000mAh頂配小屏!小米這新機,預定年度最強
- iPhone 17 Pro 限定款提前上架,這價格太離譜了
- 新形態 iPhone 定了,指紋回歸!
- 智能體已重塑商業領導層決策制定過程
- 8.8英寸+SIM卡,華為新機定價3899元,你們要的通話平板終于來了
- 曝高通新旗艦Soc命名敲定:網友覺得太長了
- AI搜索引擎,蘋果決定自研,代號WKA
- 真我15系列定檔,定位“夜拍神器”
- 告別海量標注!浙大團隊讓GUI定位在無標簽數據上自我進化