
文章圖片

文章圖片

文章圖片
文章圖片
當人們還在驚嘆大模型能寫代碼、能自動化辦公時 , 它們正在悄然踏入一個更敏感、更危險的領域 —— 網絡安全 。
想象一下 , 如果 AI 不只是寫代碼的助手 , 而是能夠像「白帽黑客」一樣 , 在不破壞系統的前提下模擬攻擊、發現漏洞、提出修復建議 , 會帶來怎樣的改變?
這個問題 , 最近由 Amazon AWS AI 的 Q Developer 團隊給出了答案 。 他們在 arXiv 上同時發布了兩篇論文 , 提出了訓練網絡安全大模型的全新方法:Cyber-Zero 和 CTF-Dojo 。 這兩項研究不僅是學術探索 , 更像是一次「實戰演練」的預告 , 預示著大模型智能體正在從通用任務走向網絡安全的前線 。
論文 1: Cyber-Zero: Training Cybersecurity Agents without Runtime
鏈接: https://arxiv.org/abs/2508.00910
論文 2: Training Language Model Agents to Find Vulnerabilities with CTF-Dojo
鏈接:https://arxiv.org/abs/2508.18370
網絡安全
大模型落地的一座特殊堡壘
在通用任務上 , 大模型的訓練已經形成了相對成熟的范式:海量數據、長時間預訓練、再經過對齊與微調 。 但網絡安全場景不同 , 其核心難點在于訓練環境與數據的高度敏感性 。
事實上 , 閉源大模型已經在安全攻防方向展現出一定潛力 。 Google 的 Project Zero 團隊就曾使用 Gemini 系列模型探索漏洞發現 , 一些初創公司甚至嘗試構建基于閉源模型的「AI 紅隊」 , 用來模擬攻擊并進行防御驗證 。 實際案例表明 , 這些強大的閉源模型確實具備了發現漏洞、自動化執行攻擊步驟的潛力 。
然而問題在于 , 這些模型的訓練范式和數據集完全不透明 。 我們無法得知它們是如何習得攻防知識的 , 也無法驗證模型的安全性與可靠性 。 更重要的是 , 閉源模型無法被研究者和企業安全團隊自主改造或控制 , 這本身在安全領域是一種潛在風險 。
另一方面 , 如果要讓模型從零開始學會攻防 , 傳統思路需要搭建真實運行環境 , 以生成交互軌跡 。 但這種方式成本高、風險大 , 甚至可能在實驗中觸發不可控的攻擊 。 而高質量的安全攻防數據本就極度稀缺 。 漏洞利用和修復往往涉及復雜的環境狀態、系統調用和長時間推理 , 很難像自然語言文本那樣容易轉化為標準語料 。
這意味著 , 如果繼續沿用傳統方式 , 「AI 白帽黑客」可能永遠只能停留在實驗階段 。 Amazon 團隊正是瞄準了這個瓶頸 , 提出了兩個互補的解決方案:Cyber-Zero 致力于「如何生成安全而高效的訓練數據」 , 而 CTF-Dojo 則專注于「如何在實戰中訓練模型發現漏洞」 。
Cyber-Zero
無需真實環境的模擬訓練場
Cyber-Zero 的核心思想是「runtime-free training」 , 即完全不依賴真實運行環境 , 而是通過已有知識和語言建模生成訓練所需的高質量行為軌跡 (trajectories) 。
團隊注意到 , 公開的 CTF(Capture The Flag)競賽 writeups 是極其寶貴的資源 。 它們記錄了參賽者如何分析題目、嘗試攻擊、定位漏洞以及最終解題的過程 。 Cyber-Zero 正是基于這些 writeups , 構建出高質量的訓練軌跡 。
具體來說 , 系統首先從 writeups 中提取關鍵步驟和思路 , 然后通過設定不同的人格(persona) , 讓大模型在純文本環境中模擬攻防雙方的對話與操作 。 例如 , 攻擊者 persona 會生成可能的利用路徑 , 防御者 persona 會進行應對 。 這一過程中生成的長序列交互被視作行為軌跡 , 用于訓練網絡安全智能體 。
實驗表明 , 這種免運行時的軌跡生成不僅規模可觀 , 而且多樣性豐富 , 覆蓋了常見的攻防模式 。 與真實環境生成的軌跡相比 , Cyber-Zero 的數據在漏洞定位、攻擊路徑推理等任務上的訓練效果毫不遜色 , 甚至在部分指標上表現更優 。 這意味著 , AI 白帽黑客可以在一個完全安全的虛擬訓練營中反復優化 , 而不必擔心成本和風險 。
【大模型智能體不止能寫代碼,還能被訓練成白帽黑客】
團隊還得出幾項關鍵發現:
通用的軟件工程智能體(SWE Agents)無法直接遷移至網絡安全任務 。 寫代碼 ≠ 找漏洞 , 兩類技能之間存在明顯鴻溝 。 模型規模與性能密切相關:參數更大的模型更擅長維持長程推理鏈 , 跨多步組合命令 , 并在多輪交互中保持狀態連貫 , 這對復雜攻防至關重要 。 經過 Cyber-Zero 軌跡微調的 32B 智能體 , 性能已接近閉源模型 Claude-3.7-Sonnet , 而推理成本僅為其 1% 。
這些結果一方面凸顯了 Cyber-Zero 的實用價值:它不僅能安全、低成本地生成訓練數據 , 還能讓模型通過微調在安全任務上具備實用能力;另一方面也指出了研究方向:如果不針對安全任務進行專門優化 , 即便是大規模的通用 SWE 智能體也難以承擔白帽黑客的角色 。
CTF-Dojo
讓 AI 在實戰中學會發現漏洞
如果說 Cyber-Zero 提供的是一個「虛構的訓練場」 , 它通過解析 CTF writeups 與 persona 模擬 , 在純文本空間中生成攻防軌跡 , 讓模型在完全無風險的虛擬環境中學習;那么 CTF-Dojo 就是一個「真實的戰場」 。 它直接構建可運行的 CTF 攻防環境 , 讓智能體能夠真正執行命令、與系統交互、發現并利用漏洞 。 前者強調規模化、安全、高效的數據生成 , 后者強調貼近實戰的攻防演練 , 兩者一虛一實 , 形成互補 。
CTF-Dojo 的核心難點在于:如何在大規模下為 LLM 智能體提供穩定的運行環境 。 傳統 SWE(軟件工程)代理通常需要專家手動配置環境才能運行 , 而每個任務的準備工作往往耗時數周 , 極大限制了研究規模 。 為此 , Amazon 團隊提出了 CTF-Forge , 一種能夠在幾分鐘內自動搭建運行時的容器化工具 , 可以快速部署數百個挑戰實例 , 顯著降低了人力成本 。
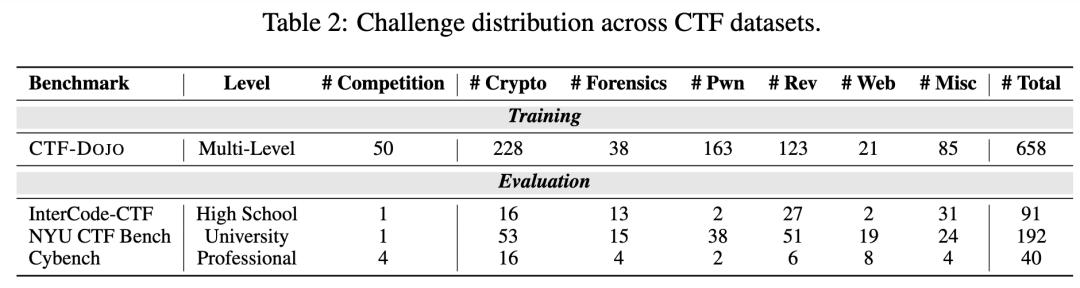
研究團隊選擇了全球最具代表性的 pwn.college CTF Archive 作為種子數據 。 該數據集收錄了數百個來自頂級賽事的高質量題目 , 涵蓋六大類別 , 從 Web 漏洞、二進制利用到密碼學挑戰一應俱全 。 通過精心篩選 , 并排除測試數據中已包含的題目 , 最終形成了 658 個獨立任務實例 , 為智能體訓練提供了堅實的基礎 。
然而 , 最初實驗表明 , 開源模型在這些復雜任務上的成功率極低 。 大部分 OSS 模型只能完成少數挑戰 , 生成的軌跡也質量參差不齊 。 為了提高可用樣本的產出率 , 團隊引入了三項推理階段增強技術:
將公開的賽題筆記(writeups) 作為提示 , 幫助模型更快鎖定解題方向; 運行時增強:通過在執行過程中動態修改環境配置或任務約束 , 把過于復雜的挑戰「降維」 , 從而提升模型完成任務的成功率; 教師模型多樣化:不僅依賴單一模型生成解題軌跡 , 而是同時調用多種不同類型的大模型(包括開源和閉源) , 讓它們各自貢獻成功案例 , 以此獲得更豐富、更具多樣性的訓練樣本 。
最終 , 團隊主要依賴 Qwen3-Code-480B 和 DeepSeek-V3-0324 兩個強大的開源模型 , 收集到來自 274 個挑戰的 1000+ 成功軌跡 。 在去除冗余、限制每個任務實例的最大樣本數后 , 最終得到了 486 條高質量、經過運行驗證的軌跡 。
基于這些數據 , 研究團隊對 Qwen3 系列模型(8B、14B 和 32B 參數規模)進行了訓練 , 并在多個網絡安全基準任務上評估了效果 。 結果顯示 , 經過 CTF-Dojo 訓練的模型 , 在 EnIGMA+ 基準(源自前作 Cyber-Zero)上取得了最高 11.6% 的絕對提升 , 不僅超過了開源基線模型 , 還表現出與閉源模型接近的水平 。 更重要的是 , 隨著訓練樣本數量的增加 , 性能呈現出清晰的可擴展性 , 證明了在真實環境軌跡驅動下 , 大模型在網絡安全任務上的潛力可以被系統性激發 。
這些結果意味著 , CTF-Dojo 不僅解決了過去「環境難以大規模配置」的工程難題 , 還驗證了一個核心科學問題:網絡安全智能體的性能能夠隨著執行數據的增加而持續提升 。 在已有 SWE 代理無法泛化的情況下 , CTF-Dojo 給出了一條清晰的道路:通過規模化、自動化的運行環境收集軌跡 , 推動模型逐步逼近人類白帽黑客的實戰水平 。
從虛擬到實戰的組合拳
把 Cyber-Zero 和 CTF-Dojo 放在一起看 , 就會發現它們形成了一個閉環 。 Cyber-Zero 提供的是安全、可擴展的訓練數據來源 , 相當于一個虛擬訓練營;而 CTF-Dojo 則是實戰武館 , 讓模型在真實挑戰中不斷迭代 。 前者解決了數據與成本的問題 , 后者解決了能力習得與遷移的問題 。 兩者結合 , 為 AI 白帽黑客的成長提供了完整路徑 。
這種設計思路的意義在于 , 它不僅追求理論上的可行性 , 還強調在生產環境中真正可部署 。 正如論文中展示的實驗結果 , Cyber-Zero 的數據生成和 CTF-Dojo 的環境構建都能規模化運行 , 且能在真實任務上帶來可驗證的性能提升 。 這標志著 AI 在網絡安全方向正在逐步進入應用落地階段 。
未來意義與挑戰
AI 白帽黑客蘊藏廣闊前景:在企業安全團隊中 , 它可以作為虛擬成員 , 自動掃描代碼、發現潛在漏洞 , 并提出修復建議;在紅隊演練中 , 它可以充當對手角色 , 幫助測試防御系統;在教育場景中 , 它可以成為學員的「陪練」 , 提供個性化的挑戰和反饋 。 更長遠來看 , 隨著成本降低和技術成熟 , 中小企業也有望借助這樣的系統獲得「普惠安全」 。
但與此同時 , 這項技術的雙重用途屬性不容忽視 。 正如研究團隊在論文中強調的那樣 , 雖然 Cyber-Zero 和 CTF-Dojo 的初衷是幫助開發者和研究人員在軟件部署前發現并修復漏洞 , 但同樣的能力也可能被濫用于進攻目的 , 比如自動化發現外部系統的漏洞 , 甚至開發惡意工具 。 特別是 Cyber-Zero 的「免運行時」方法 , 降低了訓練高性能網絡安全智能體的門檻 , 使其更容易被更廣泛的群體獲取和使用 。 這種民主化的趨勢既意味著安全研究的普及 , 也意味著風險的擴散 。
實驗結果已經證明 , 基于虛擬軌跡或執行驗證數據訓練的模型 , 能夠在多個基準任務上達到接近甚至媲美閉源前沿模型的性能 。 這表明先進網絡安全能力的民主化不僅在技術上可行 , 而且正在快速到來 。 如何確保這類能力更多地服務于防御 , 而不是被濫用于攻擊 , 將是未來亟需討論的議題 。
在未來研究方向上 , 團隊提出了幾個值得關注的思路 。 一個是構建實時更新的 CTF 基準:通過 CTF-Forge 自動重建比賽環境 , 把來自活躍 CTF 賽事的挑戰容器化 , 用于動態評測和軌跡采集 , 實現可擴展、實時的 benchmark 。 另一個方向是強化學習 , 即讓網絡安全智能體直接與動態環境交互 , 并通過結構化獎勵獲得反饋 。 這種范式有望突破單純模仿學習的局限 , 使模型能夠發展出更普適、更具適應性的策略 , 更好地應對未知的安全問題 。
因此 , 未來的關鍵在于平衡開放與安全 。 在推動技術進步與普及的同時 , 建立有效的安全護欄 , 需研究者、開發者、安全機構與政策制定者協同努力 , 確保這類強大工具以負責任的方式被開發和使用 。 唯有如此 , 才能真正增強整體網絡防御能力 , 迎接一個更安全的智能時代 。
參考資料:
[1
Zhuo T. Y. Wang D. Ding H. Kumar V.Wang Z. (2025). Cyber-Zero: Training Cybersecurity Agents without Runtime. arXiv preprint arXiv:2508.00910.
[2
Zhuo T. Y. Wang D. Ding H. Kumar V.Wang Z. (2025). Training Language Model Agents to Find Vulnerabilities with CTF-Dojo. arXiv preprint arXiv:2508.18370.
[3
https://x.com/terryyuezhuo/status/1962009753472950294
[4
https://github.com/amazon-science/Cyber-Zero
推薦閱讀










- 如果大模型是一片星空,誰是北斗?
- 放棄實體SIM卡的iPhone能買嗎:三大運營商均推進,聯通用戶或成首批嘗鮮者
- 二季度出貨的智能手機平均配備3.19個攝像頭
- 北京市通用人工智能產業創新伙伴計劃2.0發布
- 2025外灘大會科技智能創新賽落幕,優勝者獎金池達162萬元
- 當智能醒于物理世界,英偉達副總裁: 下一個十年屬于物理AI!
- 星鑰半導體8英寸Micro-LED芯片中試線在光谷通線
- iPhone 17 國行首發不支持 AI,蘋果智能預計年底上線
- IFA觀察|更智能、更綠色,中國企業高端出海
- 芝麻信用戰略升級商業信用服務體系 向高德地圖正式開放